Create Solana Account Using TypeScript, Rust and Golang
- Introduction
- Creating Solana Accounts with TypeScript
- Creating Solana Accounts with Rust
- Creating Solana Accounts with Golang
Introduction
We'll walk through the process of creating Solana accounts using TypeScript, Golang, and Rust.
Creating Solana Accounts with TypeScript
Introduction
In this tutorial, we'll walk through the process of creating Solana accounts using TypeScript. We'll cover everything from setting up your project to creating and funding accounts on the Solana blockchain.
Prerequisites
Before we begin, make sure you have the following prerequisites installed and set up on your system:
- Node.js (version 16 or later)
- npm or yarn
- Solana CLI installed
- Basic understanding of TypeScript and blockchain concepts
Project Setup
1. Initialize a New TypeScript Project
# Create a new directory
mkdir solana-account-creation
cd solana-account-creation
# Initialize npm project
pnpm init -y
# Install TypeScript and Solana Web3.js
pnpm install typescript @solana/web3.js ts-node @types/node
We need to configure the tsconfig.json file with the following content to run the code with ts-node:
cat <<EOF > tsconfig.json
{
"compilerOptions": {
"target": "es2016",
"module": "commonjs",
"types": ["node"],
"resolveJsonModule": true,
"esModuleInterop": true,
"forceConsistentCasingInFileNames": true,
"strict": true,
"skipLibCheck": true
}
}
EOF
2. Create a TypeScript File to Create Solana Accounts
touch create-account.ts
Add the following code to create-account.ts:
import {
SystemProgram,
Keypair,
PublicKey,
Transaction,
sendAndConfirmTransaction,
Connection,
clusterApiUrl,
LAMPORTS_PER_SOL,
} from "@solana/web3.js";
import { readFileSync } from "fs";
// NOTE: types field in compilerOption in `tsconfig.json` should be node
import { homedir } from "os";
async function getBalance(publicKey: PublicKey) {
const connection = new Connection(clusterApiUrl("devnet"), "confirmed");
const balance = await connection.getBalance(publicKey);
// console.log(`Payer's balance: ${balance / LAMPORTS_PER_SOL} SOL`);
return balance;
}
// Output: /Users/dylankyc
// console.log(process.env.HOME);
const payerFilePath = `${homedir()}/.config/solana/id.json`;
const payerSecretKey = Uint8Array.from(
JSON.parse(readFileSync(payerFilePath, "utf-8"))
);
console.log(`🌈 payerFilePath: ${payerFilePath}`);
const payer = Keypair.fromSecretKey(payerSecretKey);
const connection = new Connection(clusterApiUrl("devnet"), "confirmed");
// NOTE: Instead of generate keypair using Keypair::generate function,
// we'll use payer's public key
const fromPubkey = payer;
// const fromPubkey = Keypair.generate();
console.log("🌈 🌈 🌈 Create acount 🌈 🌈 🌈 ");
console.log(fromPubkey);
async function main() {
const balanceBefore = await getBalance(fromPubkey.publicKey);
// Airdrop SOL for transferring lamports to the created account
//
// NOTE: We have enough SOLs in local solana wallet, so skip airdrop
//
// const airdropSignature = await connection.requestAirdrop(
// fromPubkey.publicKey,
// LAMPORTS_PER_SOL
// );
// const tx = await connection.confirmTransaction(airdropSignature);
// // output tranasction info
// console.log('Transaction confirmed for airdrop:', tx);
// amount of space to reserve for the account
const space = 0;
// Seed the created account with lamports for rent exemption
const rentExemptionAmount =
await connection.getMinimumBalanceForRentExemption(space);
console.log(`🌈 rentExemptionAmount is : ${rentExemptionAmount}`);
const newAccountPubkey = Keypair.generate();
console.log("🌈 newAccountPubkey is generated");
console.log(
`🌈 new account address is : ${newAccountPubkey.publicKey.toBase58()}`
);
console.log(newAccountPubkey);
const createAccountParams = {
fromPubkey: fromPubkey.publicKey,
newAccountPubkey: newAccountPubkey.publicKey,
lamports: rentExemptionAmount,
space,
programId: SystemProgram.programId,
};
const createAccountTransaction = new Transaction().add(
SystemProgram.createAccount(createAccountParams)
);
const createAccountTx = await sendAndConfirmTransaction(
connection,
createAccountTransaction,
[fromPubkey, newAccountPubkey]
);
console.log("Transaction confirmed for account creation:", createAccountTx);
const balanceAfter = await getBalance(fromPubkey.publicKey);
console.log(`🌈 Balance before: ${balanceBefore}`);
console.log(`🌈 Balance after : ${balanceAfter}`);
// See transaction in devnet:
//
// https://explorer.solana.com/tx/5WqZGH4w3W65HvPhaqpKYQqn599By9wj1CWNM4XSp6VedB1C4dtNbv3zM3krd3nSLSLSsFLwGDD1UraxbCS1Vo4U?cluster=devnet
//
// https://explorer.solana.com/tx/3yio4oQfQ2WxNcYegQezpcriJZTguTffoPKjESeAb9W6NCjG4GBYAvqRdcnNz4AX3jqUofZyy9ugRhcqJVeWnmng?cluster=devnet
}
main();
Run the code:
npx ts-node create-account.ts
Output:
npx ts-node create-account.ts
🌈 payerFilePath: /Users/dylankyc/.config/solana/id.json
🌈 🌈 🌈 Create acount 🌈 🌈 🌈
Keypair {
_keypair: {
publicKey: Uint8Array(32) [
// omit
],
secretKey: Uint8Array(64) [
// omit
]
}
}
(node:87514) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead.
(Use `node --trace-deprecation ...` to show where the warning was created)
🌈 rentExemptionAmount is : 890880
🌈 newAccountPubkey is generated
🌈 new account address is : BN6yM69dUR98M3kxFeWQT8xRyeNE3cuREjSojJsHLZy7
Keypair {
_keypair: {
publicKey: Uint8Array(32) [
// omit
],
secretKey: Uint8Array(64) [
// omit
]
}
}
Transaction confirmed for account creation: 2yt5YKyYbQiW9WtEDDDG4QXfz6b2M1QhvrXpUG7mY9cWAKVQqeFoLxX25kWqjWFcR2Dj1QQWgu6FofUwrziqNNe3
🌈 Balance before: 90859560959
🌈 Balance after : 90858660079
Creating Solana Accounts with Rust
Project Setup
1. Initialize a New Rust Project using cargo
# Initialize a new Rust project
cargo new solana-rust-example
cd solana-rust-example
2. Add dependencies
# Add dependencies
cargo add anyhow bs58 dirs rand solana-rpc-client solana-sdk
Here is the Cargo.toml file:
name = "solana-rust-example"
version = "0.1.0"
edition = "2021"
[dependencies]
anyhow = "1.0.93"
bs58 = "0.5.1"
dirs = "5.0.1"
rand = "0.8.5"
solana-rpc-client = "2.1.4"
solana-sdk = "2.1.4"
3. Add src/main.rs
use anyhow::{Context, Result}; use rand::prelude::*; use solana_rpc_client::rpc_client::RpcClient; use solana_sdk::{ pubkey::Pubkey, signature::{read_keypair_file, Keypair, Signer}, system_instruction, system_program, transaction::Transaction, }; use std::path::PathBuf; fn create_account( client: &RpcClient, payer: &Keypair, new_account: &Keypair, space: u64, ) -> Result<()> { // Get minimum balance for rent exemption let rent = client.get_minimum_balance_for_rent_exemption(space.try_into()?)?; // Create account instruction let instr = system_instruction::create_account( &payer.pubkey(), &new_account.pubkey(), rent, space, &system_program::ID, ); // Get latest blockhash let blockhash = client.get_latest_blockhash()?; // Create transaction let tx = Transaction::new_signed_with_payer( &[instr], Some(&payer.pubkey()), &[payer, new_account], blockhash, ); // Send transaction and confirm let sig = client.send_and_confirm_transaction(&tx)?; println!("Transaction confirmed with signature: {}", sig); Ok(()) } fn main() -> Result<()> { // Replace with your Solana cluster URL (e.g., "https://api.mainnet-beta.solana.com") let rpc_url = "https://api.devnet.solana.com"; let client = RpcClient::new(rpc_url); println!("🌈 client connected"); // Load payer keypair from the default file location (~/.config/solana/id.json) let payer_path = dirs::home_dir() .expect("Could not find home directory") .join(".config/solana/id.json"); let payer = read_keypair_file(payer_path) .expect("Failed to read keypair file. Ensure the file exists and is valid."); println!("✅ Payer keypair loaded: {}", payer.pubkey()); // Generate a new account keypair let new_account = Keypair::new(); // Specify space for the new account (e.g., 0 for a simple account) let space = 0; // Call the create_account function match create_account(&client, &payer, &new_account, space) { Ok(_) => println!("Account created: {}", new_account.pubkey()), Err(e) => eprintln!("Error creating account: {:?}", e), } // ✅ Create account OK // See transaction: // https://explorer.solana.com/tx/2Wc9vs5RiqF2VQVAfVREYFg2xpddJJdkiywvBQ3ywxtdP7XPcgwa3eTdJLwnUghEwYDRuDXWtzhR1hFEguc3xyzn?cluster=devnet Ok(()) }
4. Explanation
The code is straightforward and easy to understand.
Let's break down what this code does:
- First, we set up the RPC client to connect to Solana's devnet:
#![allow(unused)] fn main() { let rpc_url = "https://api.devnet.solana.com"; let client = RpcClient::new(rpc_url); println!("🌈 client connected"); }
- Next, we load the payer's keypair from the default file location (~/.config/solana/id.json):
#![allow(unused)] fn main() { let payer_path = dirs::home_dir() .expect("Could not find home directory") .join(".config/solana/id.json"); let payer = read_keypair_file(payer_path) .expect("Failed to read keypair file. Ensure the file exists and is valid."); println!("✅ Payer keypair loaded: {}", payer.pubkey()); }
- We generate a new account keypair:
#![allow(unused)] fn main() { let new_account = Keypair::new(); }
- We specify the space for the new account (e.g., 0 for a simple account):
#![allow(unused)] fn main() { let space = 0; }
- Finally, we call the
create_accountfunction to create the new account:
#![allow(unused)] fn main() { match create_account(&client, &payer, &new_account, space) { Ok(_) => println!("Account created: {}", new_account.pubkey()), Err(e) => eprintln!("Error creating account: {:?}", e), } }
This function sends the transaction to create the new account and prints the transaction signature.
5. Run the code:
cargo run
Output:
🌈 client connected
✅ Payer keypair loaded: FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH
Transaction confirmed with signature: 4KtfYuuMVYcXbMydzUAMVjpDNeWdQELDnXLokYwksJbfN2sEVuMHn4XLsB13nF8RpRVmN7BEHVwzmCh8uPDeYmWc
Account created: EiQLqEn3pgmrfVVakztzRAoe9FHQtnyR7kHyUXUjn8p2
Creating Solana Accounts with Golang
Project Setup
1. Initialize a New Golang Project
mkdir solana-golang-example
cd solana-golang-example
go mod init solana-golang-example
2. Add Dependencies
go get github.com/gagliardetto/solana-go
go get github.com/gagliardetto/solana-go/rpc
Output:
go: downloading github.com/gagliardetto/solana-go v1.12.0
go: downloading filippo.io/edwards25519 v1.0.0-rc.1
go: downloading github.com/gagliardetto/binary v0.8.0
go: downloading github.com/davecgh/go-spew v1.1.1
go: downloading github.com/gagliardetto/treeout v0.1.4
go: downloading github.com/mr-tron/base58 v1.2.0
go: downloading github.com/mostynb/zstdpool-freelist v0.0.0-20201229113212-927304c0c3b1
go: downloading github.com/streamingfast/logging v0.0.0-20230608130331-f22c91403091
go: downloading go.mongodb.org/mongo-driver v1.12.2
go: downloading go.uber.org/zap v1.21.0
go: downloading github.com/fatih/color v1.9.0
go: downloading github.com/klauspost/compress v1.13.6
go: downloading github.com/blendle/zapdriver v1.3.1
go: downloading github.com/logrusorgru/aurora v2.0.3+incompatible
go: downloading golang.org/x/crypto v0.0.0-20220622213112-05595931fe9d
go: downloading go.uber.org/atomic v1.7.0
go: downloading go.uber.org/multierr v1.6.0
go: downloading github.com/mattn/go-colorable v0.1.4
go: downloading github.com/mattn/go-isatty v0.0.11
go: downloading golang.org/x/term v0.0.0-20210927222741-03fcf44c2211
go: downloading golang.org/x/sys v0.0.0-20220722155257-8c9f86f7a55f
go: added filippo.io/edwards25519 v1.0.0-rc.1
go: added github.com/blendle/zapdriver v1.3.1
go: added github.com/davecgh/go-spew v1.1.1
go: added github.com/fatih/color v1.9.0
go: added github.com/gagliardetto/binary v0.8.0
go: added github.com/gagliardetto/solana-go v1.12.0
go: added github.com/gagliardetto/treeout v0.1.4
go: added github.com/json-iterator/go v1.1.12
go: added github.com/klauspost/compress v1.13.6
go: added github.com/logrusorgru/aurora v2.0.3+incompatible
go: added github.com/mattn/go-colorable v0.1.4
go: added github.com/mattn/go-isatty v0.0.11
go: added github.com/mitchellh/go-testing-interface v1.14.1
go: added github.com/modern-go/concurrent v0.0.0-20180306012644-bacd9c7ef1dd
go: added github.com/modern-go/reflect2 v1.0.2
go: added github.com/mostynb/zstdpool-freelist v0.0.0-20201229113212-927304c0c3b1
go: added github.com/mr-tron/base58 v1.2.0
go: added github.com/streamingfast/logging v0.0.0-20230608130331-f22c91403091
go: added go.mongodb.org/mongo-driver v1.12.2
go: added go.uber.org/atomic v1.7.0
go: added go.uber.org/multierr v1.6.0
go: added go.uber.org/zap v1.21.0
go: added golang.org/x/crypto v0.0.0-20220622213112-05595931fe9d
go: added golang.org/x/sys v0.0.0-20220722155257-8c9f86f7a55f
go: added golang.org/x/term v0.0.0-20210927222741-03fcf44c2211
3. Add main.go
Although the code is simple, it's a good example to understand how to create a new account on Solana.
package main
import (
"context"
"fmt"
"github.com/gagliardetto/solana-go"
"github.com/gagliardetto/solana-go/rpc"
)
func main() {
// Create a new account:
account := solana.NewWallet()
fmt.Println("account private key:", account.PrivateKey)
fmt.Println("account public key:", account.PublicKey())
// Create a new RPC client:
// client := rpc.New(rpc.TestNet_RPC)
// Devnet RPC
client := rpc.New(rpc.DevNet_RPC)
// Airdrop 1 SOL to the new account:
out, err := client.RequestAirdrop(
context.TODO(),
account.PublicKey(),
solana.LAMPORTS_PER_SOL*1,
rpc.CommitmentFinalized,
)
if err != nil {
panic(err)
}
fmt.Println("airdrop transaction signature:", out)
}
4. Add create-account-with-payer.go
In order to fully understand how to create a new account on Solana, we need to add a create-account-with-payer.go file. This file will create a new account with a payer.
package main
import (
"context"
"fmt"
"os"
"path/filepath"
"github.com/gagliardetto/solana-go"
"github.com/gagliardetto/solana-go/programs/system"
"github.com/gagliardetto/solana-go/rpc"
)
func main() {
// Load payer keypair from ~/.config/solana/id.json
homeDir, err := os.UserHomeDir()
if err != nil {
panic(fmt.Errorf("failed to get home directory: %w", err))
}
payer, err := solana.PrivateKeyFromSolanaKeygenFile(filepath.Join(homeDir, ".config", "solana", "id.json"))
if err != nil {
panic(fmt.Errorf("failed to load payer keypair: %w", err))
}
// Create a new account
newAccount := solana.NewWallet()
fmt.Println("New account private key:", newAccount.PrivateKey)
fmt.Println("New account public key:", newAccount.PublicKey())
fmt.Println("Payer public key:", payer.PublicKey())
// Create RPC client
client := rpc.New(rpc.DevNet_RPC)
// Get recent blockhash
recent, err := client.GetLatestBlockhash(context.Background(), rpc.CommitmentFinalized)
if err != nil {
panic(fmt.Errorf("failed to get recent blockhash: %w", err))
}
// Create transaction to create account
tx, err := solana.NewTransaction(
[]solana.Instruction{
// NOTE: The order of the instructions is important.
//
// Here is the signature of NewCreateAccountInstruction:
//
// NewCreateAccountInstruction declares a new CreateAccount instruction with the provided parameters and accounts.
// func NewCreateAccountInstruction(
// // Parameters:
// lamports uint64,
// space uint64,
// owner ag_solanago.PublicKey,
// // Accounts:
// fundingAccount ag_solanago.PublicKey,
// newAccount ag_solanago.PublicKey) *CreateAccount {
// return NewCreateAccountInstructionBuilder().
// SetLamports(lamports).
// SetSpace(space).
// SetOwner(owner).
// SetFundingAccount(fundingAccount).
// SetNewAccount(newAccount)
// }
system.NewCreateAccountInstruction(
// solana.LAMPORTS_PER_SOL*1, // lamports
solana.LAMPORTS_PER_SOL/5, // lamports (0.2 SOL = 1/5 SOL)
0, // space
solana.SystemProgramID, // owner
payer.PublicKey(), // from
newAccount.PublicKey(), // new account (to)
).Build(),
},
recent.Value.Blockhash,
solana.TransactionPayer(payer.PublicKey()),
)
if err != nil {
panic(fmt.Errorf("failed to create transaction: %w", err))
}
// Sign transaction
_, err = tx.Sign(
func(key solana.PublicKey) *solana.PrivateKey {
if payer.PublicKey().Equals(key) {
return &payer
}
if newAccount.PublicKey().Equals(key) {
return &newAccount.PrivateKey
}
return nil
},
)
if err != nil {
panic(fmt.Errorf("unable to sign transaction: %w", err))
}
// Send transaction
sig, err := client.SendTransaction(context.Background(), tx)
if err != nil {
panic(fmt.Errorf("failed to send transaction: %w", err))
}
fmt.Println("Transaction signature:", sig)
}
5. Explanation
The code is straightforward and easy to understand.
Let's break down what this code does:
- First, we load the payer's keypair from the default file location (~/.config/solana/id.json):
payer, err := solana.PrivateKeyFromSolanaKeygenFile(filepath.Join(homeDir, ".config", "solana", "id.json"))
- Next, we create a new account:
newAccount := solana.NewWallet()
- We create a new RPC client:
client := rpc.New(rpc.DevNet_RPC)
- We get the recent blockhash:
recent, err := client.GetLatestBlockhash(context.Background(), rpc.CommitmentFinalized)
- We create a transaction to create the new account:
tx, err := solana.NewTransaction(
- We sign the transaction:
_, err = tx.Sign(
func(key solana.PublicKey) *solana.PrivateKey {
if payer.PublicKey().Equals(key) {
return &payer
}
if newAccount.PublicKey().Equals(key) {
return &newAccount.PrivateKey
}
return nil
},
)
The reason for this is that the payer needs to sign the transaction to approve spending SOL, and the new account needs to sign to prove ownership of the private key.
The Sign function is a bit complex, but it's necessary to ensure that the transaction is valid and can be executed on the Solana blockchain.
- We send the transaction:
sig, err := client.SendTransaction(context.Background(), tx)
Finally, we print the transaction signature:
fmt.Println("Transaction signature:", sig)
6. Run the code:
go run create-account-with-payer.go
Output:
go run create-account-with-payer.go
New account private key: 3YoYuoiBYMh7Quuo8sZTTLUGPpzEcgB7iipgV4B7JL1FS7Y7SaTLDSdvwkc1ometgLqyYkufayG3QW8qxnCFWM1F
New account public key: 7XJwrhf7AVpUsx3qAinUKbruxH9SVVfrR3sjvUk74vx5
Payer public key: FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH
Transaction signature: 5nbe1TfU9Pi7k6oaELuCfPtqGQAASn7Q9rP46r3vugC5jgjnxXCf9o5epFMWxn9kq4SnQiS2Tqdgd9UCrwSMkhbU
Developing Solana Program Without Anchor
- Initialize Project
- Write Code
- Build Program
- Deploy
- Tips
- Redeploy
- Best practices
- How to view deployed program
- Client call
- Some experiments
- Test
- Frontend
- Next Steps
- Refs
Initialize Project
Initialize Project with Cargo
We can use cargo to initialize the project.
cargo init hello_world --lib
Write Code
Program Entrypoint
We can use entrypoint macro to write the program entrypoint.
entrypoint macro needs a function parameter, which is the entrypoint function of the solana program.
#![allow(unused)] fn main() { pub fn process_instruction() -> ProgramResult { msg!("Hello, world!"); Ok(()) } }
If the function signature passed to the entrypoint macro does not meet the requirements, the compilation will fail with an error:
Checking hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
error[E0061]: this function takes 0 arguments but 3 arguments were supplied
--> src/lib.rs:6:1
|
6 | entrypoint!(process_instruction);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
| |
| unexpected argument #1 of type `&Pubkey`
| unexpected argument #2 of type `&Vec<AccountInfo<'_>>`
| unexpected argument #3 of type `&[u8]`
|
note: function defined here
--> src/lib.rs:8:8
|
8 | pub fn process_instruction() -> ProgramResult {
| ^^^^^^^^^^^^^^^^^^^
= note: this error originates in the macro `entrypoint` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0061`.
error: could not compile `hello_world` (lib) due to 1 previous error
Modify the signature of the process_instruction function
Add three parameters to the process_instruction function:
program_id:&Pubkeytype, representing the public key address of the current programaccounts:&[AccountInfo]type, representing the reference of an array of AccountInfo, which contains all the account information involved in the transactioninstruction_data:&[u8]type, representing the input data of the instruction, passed in as a byte array
These three parameters are the basic elements of the Solana program execution:
program_idis used to verify the program identity and permissionsaccountscontains all the account data that the program needs to read or modifyinstruction_datacarries the specific instruction data passed in when calling the program
#![allow(unused)] fn main() { pub fn process_instruction( _program_id: &Pubkey, _accounts: &[AccountInfo], _instruction_data: &[u8], ) -> ProgramResult { msg!("Hello, world!"); Ok(()) } }
Note that the parameter names are prefixed with an underscore (_) here, because we don't need to use these parameters in this simple example, which avoids compiler warnings about unused variables. In actual development, these parameters are very important, and we will explain how to use them in detail in subsequent examples.
We can also refer to the documentation of the solana_program_entrypoint crate for the function signature:
#![allow(unused)] fn main() { /// fn process_instruction( /// program_id: &Pubkey, // Public key of the account the program was loaded into /// accounts: &[AccountInfo], // All accounts required to process the instruction /// instruction_data: &[u8], // Serialized instruction-specific data /// ) -> ProgramResult; }
Build Program
Build Program with cargo build-sbf
To build the solana program, we need to use the cargo build-sbf program.
cargo build-sbf
The build failed, and here is the error message.
dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf
error: package `solana-program v2.1.4` cannot be built because it requires rustc 1.79.0 or newer, while the currently active rustc version is 1.75.0-dev
Either upgrade to rustc 1.79.0 or newer, or use
cargo update solana-program@2.1.4 --precise ver
where `ver` is the latest version of `solana-program` supporting rustc 1.75.0-dev
We can check the rustc version information by using the --version parameter.
cargo-build-sbf --version
Output:
solana-cargo-build-sbf 1.18.25
platform-tools v1.41
rustc 1.75.0
Regarding the version mismatch between the system Rust compiler and the Rust compiler used by build-sbf, you can refer to this issue. https://github.com/solana-labs/solana/issues/34987
Solve the build-sbf compilation failure problem
One way is to use an old version of solana-program, such as the =1.17.0 version.
[package]
name = "hello_world"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib", "lib"]
[dependencies]
solana-program = "=1.17.0"
# solana-program = "=1.18.0"
But after running cargo build-sbf, another error occurred.
error: failed to parse lock file at: /Users/dylan/Code/solana/projects/hello_world/Cargo.lock
Caused by:
lock file version 4 requires `-Znext-lockfile-bump`
It seems that the cargo version used by build-sbf does not support the Cargo.lock file version = 4, which is automatically generated by the editor (vscode/cursor).
Install the stable version of the solana cli tool chain: sh -c "$(curl -sSfL https://release.anza.xyz/stable/install)", but it still failed to compile, and the error is as follows:
dylan@smalltown ~/Code/solana/projects/hello_world (master)> sh -c "$(curl -sSfL https://release.anza.xyz/stable/install)"
downloading stable installer
✨ stable commit 7104d71 initialized
dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf --version
solana-cargo-build-sbf 2.0.17
platform-tools v1.42
dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf
[2024-12-04T11:14:48.052020000Z ERROR cargo_build_sbf] Failed to install platform-tools: HTTP status client error (404 Not Found) for url (https://github.com/anza-xyz/platform-tools/releases/download/v1.42/platform-tools-osx-x86_64.tar.bz2)
When compiling with cargo build-sbf, you need to download the corresponding version of platform-tools, because the v1.42 version of platform-tools for Mac (Intel) has not been released yet, so the above command failed to run.
dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf
Compiling cc v1.2.2
Compiling serde v1.0.215
Compiling solana-frozen-abi-macro v1.17.0
Compiling ahash v0.7.8
Compiling solana-frozen-abi v1.17.0
Compiling either v1.13.0
Compiling bs58 v0.4.0
Compiling log v0.4.22
Compiling hashbrown v0.11.2
Compiling itertools v0.10.5
Compiling solana-sdk-macro v1.17.0
Compiling bytemuck v1.20.0
Compiling borsh v0.9.3
Compiling num-derive v0.3.3
Compiling blake3 v1.5.5
Compiling solana-program v1.17.0
Compiling bv v0.11.1
Compiling serde_json v1.0.133
Compiling serde_bytes v0.11.15
Compiling bincode v1.3.3
Error: Function _ZN112_$LT$solana_program..instruction..InstructionError$u20$as$u20$solana_frozen_abi..abi_example..AbiEnumVisitor$GT$13visit_for_abi17hc69c00f4c61717f8E Stack offset of 6640 exceeded max offset of 4096 by 2544 bytes, please minimize large stack variables. Estimated function frame size: 6680 bytes. Exceeding the maximum stack offset may cause undefined behavior during execution.
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished `release` profile [optimized] target(s) in 25.19s
+ ./platform-tools/rust/bin/rustc --version
+ ./platform-tools/rust/bin/rustc --print sysroot
+ set +e
+ rustup toolchain uninstall solana
info: uninstalling toolchain 'solana'
info: toolchain 'solana' uninstalled
+ set -e
+ rustup toolchain link solana platform-tools/rust
+ exit 0
⏎
dylan@smalltown ~/Code/solana/projects/hello_world (master)> ls target/deploy/
hello_world-keypair.json hello_world.so
dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf --version
solana-cargo-build-sbf 2.1.4
platform-tools v1.43
rustc 1.79.0
dylan@smalltown ~/Code/solana/projects/hello_world (master) [1]> sh -c "$(curl -sSfL https://release.anza.xyz/beta/install)"
downloading beta installer
✨ beta commit 024d047 initialized
dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf --version
solana-cargo-build-sbf 2.1.4
platform-tools v1.43
rustc 1.79.0
dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf
Error: Function _ZN112_$LT$solana_program..instruction..InstructionError$u20$as$u20$solana_frozen_abi..abi_example..AbiEnumVisitor$GT$13visit_for_abi17hc69c00f4c61717f8E Stack offset of 6640 exceeded max offset of 4096 by 2544 bytes, please minimize large stack variables. Estimated function frame size: 6680 bytes. Exceeding the maximum stack offset may cause undefined behavior during execution.
Finished `release` profile [optimized] target(s) in 0.23s
Using the beta version of the solana cli tool suites, it could compile, but it encountered this error:
Exceeding the maximum stack offset may cause undefined behavior during execution.
Compiling bincode v1.3.3
Error: Function _ZN112_$LT$solana_program..instruction..InstructionError$u20$as$u20$solana_frozen_abi..abi_example..AbiEnumVisitor$GT$13visit_for_abi17hc69c00f4c61717f8E Stack offset of 6640 exceeded max offset of 4096 by 2544 bytes, please minimize large stack variables. Estimated function frame size: 6680 bytes. Exceeding the maximum stack offset may cause undefined behavior during execution.
The specific reason is still the version problem, and the analysis can be referred to: https://solana.stackexchange.com/questions/16443/error-function-stack-offset-of-7256-exceeded-max-offset-of-4096-by-3160-bytes
After updating the solana-program version to 2.1.4 (run sh -c "$(curl -sSfL https://release.anza.xyz/v2.1.4/install)"), use the following tool chain to compile:
> cargo build-sbf --version
solana-cargo-build-sbf 2.1.4
platform-tools v1.43
rustc 1.79.0
# solana-cargo-build-sbf 2.2.0
# platform-tools v1.43
# rustc 1.79.0
Run cargo build-sbf:
> cargo build-sbf
Compiling serde v1.0.215
Compiling equivalent v1.0.1
Compiling hashbrown v0.15.2
Compiling toml_datetime v0.6.8
Compiling syn v2.0.90
Compiling winnow v0.6.20
Compiling cfg_aliases v0.2.1
Compiling once_cell v1.20.2
Compiling borsh v1.5.3
Compiling solana-define-syscall v2.1.4
Compiling solana-sanitize v2.1.4
Compiling solana-atomic-u64 v2.1.4
Compiling bs58 v0.5.1
Compiling bytemuck v1.20.0
Compiling five8_core v0.1.1
Compiling five8_const v0.1.3
Compiling solana-decode-error v2.1.4
Compiling solana-msg v2.1.4
Compiling cc v1.2.2
Compiling solana-program-memory v2.1.4
Compiling log v0.4.22
Compiling solana-native-token v2.1.4
Compiling solana-program-option v2.1.4
Compiling indexmap v2.7.0
Compiling blake3 v1.5.5
Compiling toml_edit v0.22.22
Compiling serde_derive v1.0.215
Compiling bytemuck_derive v1.8.0
Compiling solana-sdk-macro v2.1.4
Compiling thiserror-impl v1.0.69
Compiling num-derive v0.4.2
Compiling proc-macro-crate v3.2.0
Compiling borsh-derive v1.5.3
Compiling thiserror v1.0.69
Compiling solana-secp256k1-recover v2.1.4
Compiling solana-borsh v2.1.4
Compiling solana-hash v2.1.4
Compiling bincode v1.3.3
Compiling bv v0.11.1
Compiling solana-serde-varint v2.1.4
Compiling serde_bytes v0.11.15
Compiling solana-fee-calculator v2.1.4
Compiling solana-short-vec v2.1.4
Compiling solana-sha256-hasher v2.1.4
Compiling solana-pubkey v2.1.4
Compiling solana-instruction v2.1.4
Compiling solana-sysvar-id v2.1.4
Compiling solana-slot-hashes v2.1.4
Compiling solana-clock v2.1.4
Compiling solana-epoch-schedule v2.1.4
Compiling solana-last-restart-slot v2.1.4
Compiling solana-rent v2.1.4
Compiling solana-program-error v2.1.4
Compiling solana-stable-layout v2.1.4
Compiling solana-serialize-utils v2.1.4
Compiling solana-account-info v2.1.4
Compiling solana-program-pack v2.1.4
Compiling solana-bincode v2.1.4
Compiling solana-slot-history v2.1.4
Compiling solana-program-entrypoint v2.1.4
Compiling solana-cpi v2.1.4
Compiling solana-program v2.1.4
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished `release` profile [optimized] target(s) in 50.87s
Finally, the compilation succeeded, let's celebrate with a bottle of champagne!
Here is the Cargo.toml file:
[package]
name = "hello_world"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib", "lib"]
[dependencies]
solana-program = "2.1.4"
# solana-program = "=1.17.0"
Build Product
cargo build-sbf is a special build command provided by Solana, which compiles a Rust program into BPF (Berkeley Packet Filter) bytecode that can be executed in the Solana runtime environment. This command does the following:
-
Use a specific Rust toolchain to compile the code
- Use a Rust compiler optimized for Solana
- Use the
bpfel-unknown-unknowntarget platform - Enable release mode optimization
-
Generate necessary deployment files
- Compile the
.sofile (shared object file) - Generate the program keypair (if it does not exist)
- Optimize and compress the final binary file
- Compile the
-
Verify the compilation result
- Check if the program size is within the limit
- Verify if the program format is correct
The command execution process:
- First, check and download the necessary toolchain
- Use cargo to compile the project
- Post-process the compilation result (e.g., strip debugging information)
- Place the final file in the
target/deploydirectory
This command replaces the earlier cargo build-bpf, providing a better build experience and more modern toolchain support.
Let's see what files are generated. After running the cargo build-sbf command, two important files will be generated in the target/deploy directory:
hello_world.so:The compiled program file, which is an executable file in BPF (Berkeley Packet Filter) formathello_world-keypair.json:The program keypair file, used for program deployment and upgrade
If you see output similar to the following, it indicates a successful build:
BPF SDK: /Users/username/.local/share/solana/install/releases/1.14.x/solana-release/bin/sdk/bpf
cargo-build-sbf child: rustup toolchain list -v
cargo-build-sbf child: cargo +bpf build --target bpfel-unknown-unknown --release
Finished release [optimized] target(s) in 0.20s
cargo-build-sbf child: /Users/username/.local/share/solana/install/releases/1.14.x/solana-release/bin/sdk/bpf/scripts/strip.sh /Users/username/projects/hello_world/target/bpfel-unknown-unknown/release/hello_world.so /Users/username/projects/hello_world/target/deploy/hello_world.so
Deploy
Now we can deploy the compiled program to the Solana network. In the development stage, we usually use the local testnet (localhost) or the devnet for testing.
First, ensure your Solana CLI is configured to the correct cluster:
# 切换到开发网
solana config set --url devnet
# 切换到本地测试网
solana config set --url localnet
# 查看当前配置
solana config get
Then use the following command to deploy the program:
solana program deploy target/deploy/hello_world.so
After successful deployment, you will see the program ID (public key address). Please save this address, as it will be needed for future interactions with the program.
But when we deploy the program by running the solana program deploy command, the deployment failed.
dylan@smalltown ~/Code/solana/projects/helloworld (master)> solana program deploy ./target/deploy/helloworld.so
⠁ 0.0% | Sending 1/173 transactions [block height 2957; re-sign in 150 blocks]
thread 'main' panicked at quic-client/src/nonblocking/quic_client.rs:142:14:
QuicLazyInitializedEndpoint::create_endpoint bind_in_range: Os { code: 55, kind: Uncategorized, message: "No buffer space available" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
So what does this No buffer space available mean?
After a long time of troubleshooting, I finally found that the problem was probably caused by version issues. Since the program created by the Anchor project can be deployed normally.
Here is the version information of the solana command:
> solana --version
solana-cli 2.2.0 (src:67704836; feat:1081947060, client:Agave)
Back to the Anchor project to verify that the deployment failure is due to version issues
We can create a new project by running anchor init helloworld and deploy the program by running anchor build and anchor deploy.
anchor init helloworld
cd helloworld
anchor build
anchor deploy
From the error message, it is found that the newly generated anchor project also encounters the same error when deploying: No buffer space available
dylan@smalltown ~/tmp/helloworld (main)> anchor deploy
Deploying cluster: https://api.devnet.solana.com
Upgrade authority: /Users/dylan/.config/solana/id.json
Deploying program "helloworld"...
Program path: /Users/dylan/tmp/helloworld/target/deploy/helloworld.so...
⠁ 0.0% | Sending 1/180 transactions [block height 332937196; re-sign in 150 blocks] thread 'main' panicked at quic-client/src/nonblocking/quic_client.rs:142:14:
QuicLazyInitializedEndpoint::create_endpoint bind_in_range: Os { code: 55, kind: Uncategorized, message: "No buffer space available" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
There was a problem deploying: Output { status: ExitStatus(unix_wait_status(25856)), stdout: "", stderr: "" }.
Check the anchor version:
dylan@smalltown ~/tmp/helloworld (main)> anchor deploy --help
Deploys each program in the workspace
Usage: anchor-0.30.1 deploy [OPTIONS] [-- <SOLANA_ARGS>...]
Arguments:
[SOLANA_ARGS]... Arguments to pass to the underlying `solana program deploy` command
Options:
-p, --program-name <PROGRAM_NAME> Only deploy this program
--provider.cluster <CLUSTER> Cluster override
--program-keypair <PROGRAM_KEYPAIR> Keypair of the program (filepath) (requires program-name)
--provider.wallet <WALLET> Wallet override
-v, --verifiable If true, deploy from path target/verifiable
-h, --help Print help
Check the solana version:
> solana --version
solana-cli 2.2.0 (src:67704836; feat:1081947060, client:Agave)
This 2.2.0 version looks strange, and I suddenly thought that I installed the edge version of solana cli to compile the solana program, and the version of the solana cli it carries is 2.2.0:
sh -c "$(curl -sSfL https://release.anza.xyz/edge/install)"
So I switched back to the stable version:
> sh -c "$(curl -sSfL https://release.anza.xyz/stable/install)"
downloading stable installer
✨ stable commit fbead11 initialized
The stable version of solana is 2.0.19.
> solana --version
solana-cli 2.0.19 (src:fbead118; feat:607245837, client:Agave)
Before re-deploying the program, let's clean up the buffers of the previously failed program, which is buffer accounts. For what is a buffer account, please refer to Tips 3.
- Check all buffer accounts:
solana program show --buffers - Close all buffer accounts:
solana program close --buffers- Closing buffer accounts can reclaim SOL stored in buffer accounts
Error: error sending request for url (https://api.devnet.solana.com/): operation timed out
dylan@smalltown ~/tmp/helloworld (main)> solana program show --buffers
Buffer Address | Authority | Balance
CcKFVBzcsrcReZHBLnwzkQbNGXoK4hUee7hkgtbHCKtL | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 0.12492504 SOL
62wFzMYBhxWg4ntEJmFZcQ3P3Qtm9SbaBcbTmV8o8yPk | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 0.12492504 SOL
9q88jzvR5AdPdNTihxWroxRL7cBWQ5xXepNfDdaqmMTv | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 1.26224472 SOL
3nqzHv9vUphsmAjoR1C5ShgZ54muTzkZZ6Z4NKfqrKqt | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 1.26224472 SOL
8tZ8YYA1WS6WFVyEbJAdgnszXYZwwq7b9RLdoiry2Fb1 | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 0.12492504 SOL
dylan@smalltown ~/tmp/helloworld (main)> solana program close --buffers
Buffer Address | Authority | Balance
CcKFVBzcsrcReZHBLnwzkQbNGXoK4hUee7hkgtbHCKtL | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 0.12492504 SOL
62wFzMYBhxWg4ntEJmFZcQ3P3Qtm9SbaBcbTmV8o8yPk | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 0.12492504 SOL
9q88jzvR5AdPdNTihxWroxRL7cBWQ5xXepNfDdaqmMTv | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 1.26224472 SOL
3nqzHv9vUphsmAjoR1C5ShgZ54muTzkZZ6Z4NKfqrKqt | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 1.26224472 SOL
8tZ8YYA1WS6WFVyEbJAdgnszXYZwwq7b9RLdoiry2Fb1 | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 0.12492504 SOL
After cleaning up the buffer accounts, we also switched back to the stable version of the solana cli, and we tried to deploy the program again:
> anchor deploy
Deploying cluster: https://api.devnet.solana.com
Upgrade authority: /Users/dylan/.config/solana/id.json
Deploying program "helloworld"...
Program path: /Users/dylan/tmp/helloworld/target/deploy/helloworld.so...
Program Id: DiSGTiXGq4HXCxq1pAibuGZjSpKT4Av8WShvuuYhTks9
Signature: 2EXHmU68k9SmJ5mXuM61pFDnUgozbJZ5ihHChPqFMVgjRJy4zCqnq6NAbvDkfiHd29xsmW4Vr3Kk6wHFbLEdCEZb
Deploy success
Success 🎉, let's celebrate with a bottle of champagne!
This further deepened our suspicion that the version issue was causing the program to fail to deploy.
Back to deploy our hello_world project
After verifying that the deployment failure was not due to the project type (anchor project or cargo project), we returned to the cargo init created project: hello_world.
We can deploy the program through the solana subcommand: run solana program deploy ./target/deploy/helloworld.so to deploy the program.
We will deploy on both localnet and devnet.
localnet deployment
First, let's deploy on localnet.
Switch to localnet:
dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana_local
Config File: /Users/dylan/.config/solana/cli/config.yml
RPC URL: http://localhost:8899
WebSocket URL: ws://localhost:8900/ (computed)
Keypair Path: /Users/dylan/.config/solana/id.json
Commitment: confirmed
dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana config get
Config File: /Users/dylan/.config/solana/cli/config.yml
RPC URL: http://localhost:8899
WebSocket URL: ws://localhost:8900/ (computed)
Keypair Path: /Users/dylan/.config/solana/id.json
Commitment: confirmed
Deploy the program:
dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana program deploy ./target/deploy/hello_world.so
Program Id: DhQr1KGGQcf8BeU5uQvR35p2kgKqEinD45PRTDDRqx7z
Signature: 3WVEWN4NUodsb8ZDjbjrTWXLikZ7wbWCuzuRZtSBmyKL4kVvESSeLwKZ3cJo1At4vDcaBs5iEcHhdteyXCwqwmDw
devnet deployment
Here is the devnet deployment.
Switch to localnet:
dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana_devnet
Config File: /Users/dylan/.config/solana/cli/config.yml
RPC URL: https://api.devnet.solana.com
WebSocket URL: wss://api.devnet.solana.com/ (computed)
Keypair Path: /Users/dylan/.config/solana/id.json
Commitment: confirmed
dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana config get
Config File: /Users/dylan/.config/solana/cli/config.yml
RPC URL: https://api.devnet.solana.com
WebSocket URL: wss://api.devnet.solana.com/ (computed)
Keypair Path: /Users/dylan/.config/solana/id.json
Commitment: confirmed
dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana program deploy ./target/deploy/hello_world.so
Program Id: DhQr1KGGQcf8BeU5uQvR35p2kgKqEinD45PRTDDRqx7z
Signature: 4P89gHNUNccQKJAsE3aXJVpFrWeqLxcmk9SYHbQCX7T1sEvyPrxcbrAeJbk8F8YKwWT79nTswSZkz7mtSb55nboF
We can check the balance before and after deployment through solana balance.
# Balance before deployment
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana balance
75.153619879 SOL
# Balance after deployment
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana balance
75.152378439 SOL
The version at this time:
dylan@smalltown ~/Code/solana/projects/helloworld (master)> solana --version
solana-cli 2.0.19 (src:fbead118; feat:607245837, client:Agave)
It can be seen that it is not recommended to use the latest version (solana-cli 2.2.0), otherwise it will be counterproductive.
Tips
Tip 1: Keep the version of solana cli consistent with the version in Cargo.toml
In the solana official tutorial it mentions this Tip:
It is highly recommended to keep your solana-program and other Solana Rust dependencies in-line with your installed version of the Solana CLI. For example, if you are running Solana CLI 2.0.3, you can instead run:
cargo add solana-program@"=2.0.3"
This will ensure your crate uses only 2.0.3 and nothing else. If you experience compatibility issues with Solana dependencies, check out the
Tip 2: Do not add solana-sdk to dependencies, as it is only used offchain
Refer to the explanation here: https://solana.stackexchange.com/questions/9109/cargo-build-bpf-failed
I have identified the issue. The solana-sdk is designed for off-chain use only, so it should be removed from the dependencies.
Error when adding solana-sdk to dependencies:
Compiling autocfg v1.4.0
Compiling jobserver v0.1.32
error: target is not supported, for more information see: https://docs.rs/getrandom/#unsupported-targets
--> src/lib.rs:267:9
|
267 | / compile_error!("\
268 | | target is not supported, for more information see: \
269 | | https://docs.rs/getrandom/#unsupported-targets\
270 | | ");
| |__________^
error[E0433]: failed to resolve: use of undeclared crate or module `imp`
--> src/lib.rs:291:5
|
291 | imp::getrandom_inner(dest)
| ^^^ use of undeclared crate or module `imp`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `getrandom` (lib) due to 2 previous errors
warning: build failed, waiting for other jobs to finish...
Tip 3: About buffer accounts
In Solana, buffer accounts are used as temporary accounts during the program deployment process. They are an important mechanism for deploying programs on Solana. Due to the transaction size limit of 1232 bytes, deploying a program usually requires multiple transaction steps. In this process, the buffer account serves as a storage for the program's bytecode until the deployment is complete.
Key points about buffer accounts:
- Temporary storage: Buffer accounts are used to store the program's bytecode, ensuring that large programs can be processed during deployment.
- Automatic closure: Once the program is successfully deployed, the associated buffer accounts are automatically closed, releasing the allocated resources.
- Failure handling: If the deployment fails, the buffer accounts are not automatically deleted. Users can choose:
- Continue using the existing buffer account to complete the deployment.
- Close buffer accounts to reclaim the allocated SOL (rent).
- Check buffer accounts: You can check if there are any unclosed buffer accounts using the command
solana program show --buffers. - Close buffer accounts: You can close buffer accounts using the command
solana program close --buffers.
For an explanation of the process of deploying a Solana program, you can refer to the official documentation: https://solana.com/docs/programs/deploying#program-deployment-process
Redeploy
Redeploying only requires editing the code and running cargo build-sbf to compile the code, then deploying through solana program deply ./target/deploy/hello_world.so.
cargo build-sbf
solana program deploy ./target/deploy/hello_world.so
You can verify that the new version of the program is running by running tests and client scripts.
# Run tests
cargo test-sbf
# Run client script
cargo run --example client
For example, if I modify the msg! input content to Hello, world! GM!GN!, running tests and client scripts will see this output in the log.
#![allow(unused)] fn main() { pub fn process_instruction( _program_id: &Pubkey, _accounts: &[AccountInfo], _instruction_data: &[u8], ) -> ProgramResult { msg!("Hello, world! GM!GN!"); Ok(()) } }
Run tests:
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo test-sbf
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished release [optimized] target(s) in 1.76s
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished `test` profile [unoptimized + debuginfo] target(s) in 13.92s
Running unittests src/lib.rs (target/debug/deps/hello_world-ee1a919556768e26)
running 1 test
[2024-12-06T08:06:57.714248000Z INFO solana_program_test] "hello_world" SBF program from /Users/dylan/Code/solana/projects/hello_world/target/deploy/hello_world.so, modified 19 seconds, 228 ms, 255 µs and 392 ns ago
[2024-12-06T08:06:57.947344000Z DEBUG solana_runtime::message_processor::stable_log] Program 1111111QLbz7JHiBTspS962RLKV8GndWFwiEaqKM invoke [1]
[2024-12-06T08:06:57.947695000Z DEBUG solana_runtime::message_processor::stable_log] Program log: Hello, world! GM!GN!
[2024-12-06T08:06:57.947738000Z DEBUG solana_runtime::message_processor::stable_log] Program 1111111QLbz7JHiBTspS962RLKV8GndWFwiEaqKM consumed 140 of 200000 compute units
[2024-12-06T08:06:57.947897000Z DEBUG solana_runtime::message_processor::stable_log] Program 1111111QLbz7JHiBTspS962RLKV8GndWFwiEaqKM success
test test::test_hello_world ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.24s
Doc-tests hello_world
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
TODO: image
Best practices
Best practice for installing solana-cli
The best way is to install a specific version of solana cli, such as using the following method to install the 2.0.3 version:
# Installing stable and beta are not recommended
# sh -c "$(curl -sSfL https://release.anza.xyz/stable/install)"
# sh -c "$(curl -sSfL https://release.anza.xyz/beta/install)"
# Recommended to install a specific version
sh -c "$(curl -sSfL https://release.anza.xyz/v2.0.3/install)"
Output:
downloading v2.0.3 installer
✨ 2.0.3 initialized
Run cargo build-sbf --version to check the version of cargo build-sbf:
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master) [1]> cargo build-sbf --version
solana-cargo-build-sbf 2.0.3
platform-tools v1.41
rustc 1.75.0
It can be seen that the rustc version here is 1.75.0, which is relatively old, and the compilation must include the -Znext-lockfile-bump parameter, otherwise it will compile with an error:
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf
info: uninstalling toolchain 'solana'
info: toolchain 'solana' uninstalled
error: failed to parse lock file at: /Users/dylan/Code/solana/projects/hello_world/Cargo.lock
Caused by:
lock file version 4 requires `-Znext-lockfile-bump`
Here is the complete compilation process after passing the -Znext-lockfile-bump parameter:
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf -- -Znext-lockfile-bump
Compiling proc-macro2 v1.0.92
Compiling unicode-ident v1.0.14
Compiling version_check v0.9.5
Compiling typenum v1.17.0
Compiling autocfg v1.4.0
Compiling serde v1.0.215
Compiling syn v1.0.109
Compiling cfg-if v1.0.0
Compiling equivalent v1.0.1
Compiling hashbrown v0.15.2
Compiling semver v1.0.23
Compiling generic-array v0.14.7
Compiling ahash v0.8.11
Compiling winnow v0.6.20
Compiling indexmap v2.7.0
Compiling toml_datetime v0.6.8
Compiling shlex v1.3.0
Compiling quote v1.0.37
Compiling subtle v2.6.1
Compiling cc v1.2.2
Compiling syn v2.0.90
Compiling once_cell v1.20.2
Compiling rustversion v1.0.18
Compiling feature-probe v0.1.1
Compiling zerocopy v0.7.35
Compiling cfg_aliases v0.2.1
Compiling borsh v1.5.3
Compiling bv v0.11.1
Compiling rustc_version v0.4.1
Compiling num-traits v0.2.19
Compiling memoffset v0.9.1
Compiling thiserror v1.0.69
Compiling toml_edit v0.22.22
Compiling blake3 v1.5.5
Compiling block-buffer v0.10.4
Compiling crypto-common v0.1.6
Compiling solana-program v2.0.3
Compiling digest v0.10.7
Compiling hashbrown v0.13.2
Compiling constant_time_eq v0.3.1
Compiling bs58 v0.5.1
Compiling arrayvec v0.7.6
Compiling arrayref v0.3.9
Compiling keccak v0.1.5
Compiling sha2 v0.10.8
Compiling toml v0.5.11
Compiling sha3 v0.10.8
Compiling proc-macro-crate v3.2.0
Compiling borsh-derive-internal v0.10.4
Compiling borsh-schema-derive-internal v0.10.4
Compiling getrandom v0.2.15
Compiling lazy_static v1.5.0
Compiling bytemuck v1.20.0
Compiling log v0.4.22
Compiling proc-macro-crate v0.1.5
Compiling serde_derive v1.0.215
Compiling thiserror-impl v1.0.69
Compiling num-derive v0.4.2
Compiling solana-sdk-macro v2.0.3
Compiling bytemuck_derive v1.8.0
Compiling borsh-derive v1.5.3
Compiling borsh-derive v0.10.4
Compiling borsh v0.10.4
Compiling serde_bytes v0.11.15
Compiling bincode v1.3.3
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished release [optimized] target(s) in 2m 28s
+ ./platform-tools/rust/bin/rustc --version
+ ./platform-tools/rust/bin/rustc --print sysroot
+ set +e
+ rustup toolchain uninstall solana
info: uninstalling toolchain 'solana'
info: toolchain 'solana' uninstalled
+ set -e
+ rustup toolchain link solana platform-tools/rust
+ exit 0
It is worth noting that both installing the stable version and the beta version will cause compilation failures. Running cargo build-sbf on the stable version will download the platform-tools for the x86_64 architecture from the github release page, but the official release does not provide platform-tools for this version. Here is the error information:
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master) [1]> cargo build-sbf --version
solana-cargo-build-sbf 2.0.19
platform-tools v1.42
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master) [1]> cargo build-sbf
[2024-12-05T06:17:30.547088000Z ERROR cargo_build_sbf] Failed to install platform-tools: HTTP status client error (404 Not Found) for url (https://github.com/anza-xyz/platform-tools/releases/download/v1.42/platform-tools-osx-x86_64.tar.bz2)
It is found that if --tools-version is specified as v1.43, it will also fail to compile.
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master) [1]> cargo build-sbf --tools-version v1.43
Blocking waiting for file lock on package cache
Blocking waiting for file lock on package cache
Compiling blake3 v1.5.5
Compiling solana-program v2.0.3
Compiling bs58 v0.5.1
Compiling solana-sdk-macro v2.0.3
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished `release` profile [optimized] target(s) in 1m 16s
+ curl -L https://github.com/anza-xyz/platform-tools/releases/download/v1.42/platform-tools-osx-x86_64.tar.bz2 -o platform-tools-osx-x86_64.tar.bz2
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 9 100 9 0 0 16 0 --:--:-- --:--:-- --:--:-- 16
+ tar --strip-components 1 -jxf platform-tools-osx-x86_64.tar.bz2
tar: Error opening archive: Unrecognized archive format
+ return 1
+ popd
+ return 1
/Users/dylan/.local/share/solana/install/releases/stable-fbead118867c08e6c3baaf8d196897c2536f067a/solana-release/bin/sdk/sbf/scripts/strip.sh: line 23: /Users/dylan/.local/share/solana/install/releases/stable-fbead118867c08e6c3baaf8d196897c2536f067a/solana-release/bin/sdk/sbf/dependencies/platform-tools/llvm/bin/llvm-objcopy: No such file or directory
So it is best to install a specific version of the solana cli.
How to view deployed program
We can view the deployed program by accessing the following address.
https://explorer.solana.com/?cluster=custom
It will automatically use the local localhost:8899 as the rpc endpoint, and search for the program id in the search bar to view the transaction details.
Client call
Client call program (Rust) (invoke solana program)
First, create the examples directory, and then create the client.rs file in the examples directory.
mkdir -p examples
touch examples/client.rs
Add the following content to Cargo.toml:
[[example]]
name = "client"
path = "examples/client.rs"
Add solana-client dependency:
cargo add solana-client@1.18.26 --dev
Add the following code to examples/client.rs, note to replace the program ID you deployed:
use solana_client::rpc_client::RpcClient; use solana_sdk::{ commitment_config::CommitmentConfig, instruction::Instruction, pubkey::Pubkey, signature::{Keypair, Signer}, transaction::Transaction, }; use std::str::FromStr; #[tokio::main] async fn main() { // Program ID (replace with your actual program ID) let program_id = Pubkey::from_str("85K3baeo8tvZBmuty2UP8mMVd1vZtxLkmeUkj1s6tnT6").unwrap(); // Connect to the Solana devnet let rpc_url = String::from("http://127.0.0.1:8899"); let client = RpcClient::new_with_commitment(rpc_url, CommitmentConfig::confirmed()); // Generate a new keypair for the payer let payer = Keypair::new(); // Request airdrop let airdrop_amount = 1_000_000_000; // 1 SOL let signature = client .request_airdrop(&payer.pubkey(), airdrop_amount) .expect("Failed to request airdrop"); // Wait for airdrop confirmation loop { let confirmed = client.confirm_transaction(&signature).unwrap(); if confirmed { break; } } // Create the instruction let instruction = Instruction::new_with_borsh( program_id, &(), // Empty instruction data vec![], // No accounts needed ); // Add the instruction to new transaction let mut transaction = Transaction::new_with_payer(&[instruction], Some(&payer.pubkey())); transaction.sign(&[&payer], client.get_latest_blockhash().unwrap()); // Send and confirm the transaction match client.send_and_confirm_transaction(&transaction) { Ok(signature) => println!("Transaction Signature: {}", signature), Err(err) => eprintln!("Error sending transaction: {}", err), } }
This simple script can invoke the deployed solana program, which mainly does the following:
- Connect to the local RPC
- Create a new account
- Airdrop 1 SOL to the new account
- Create the instruction (Instruction) required for the hello_world program
- Send the transaction (through
send_and_confirm_transaction)
About the program ID, we can get the program ID through the solana address -k <program keypair>.json command:
solana address -k ./target/deploy/hello_world-keypair.json
The -k parameter receives the keypair file, and can obtain the PublicKey.
Run client:
cargo run --example client
Run client code output:
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo run --example client
Blocking waiting for file lock on package cache
Blocking waiting for file lock on package cache
Blocking waiting for file lock on package cache
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 5.13s
Running `target/debug/examples/client`
Transaction Signature: iPcYzbBCM6kkXvdx5GQLS9WYunT6yWFAp8NeRyNH5ZHbjXNpGuT1pqLAmQZSa2g7mubuFmaCTxqPVS54J4Zz22h
Client call (TypeScript)
We can send transactions by creating a nodejs project:
mkdir -p helloworld
npm init -y
npm install --save-dev typescript
npm install @solana/web3.js@1 @solana-developers/helpers@2
Create the tsconfig.json configuration file:
{
"compilerOptions": {
"target": "es2016",
"module": "commonjs",
"types": ["node"],
"esModuleInterop": true,
"forceConsistentCasingInFileNames": true,
"strict": true,
"skipLibCheck": true
}
}
Create the hello-world-client.ts file, note to modify the PublicKey parameter to the programID you deployed:
import {
Connection,
PublicKey,
Transaction,
TransactionInstruction,
} from "@solana/web3.js";
import { getKeypairFromFile } from "@solana-developers/helpers";
async function main() {
const programId = new PublicKey(
"DhQr1KGGQcf8BeU5uQvR35p2kgKqEinD45PRTDDRqx7z"
);
// Connect to a solana cluster. Either to your local test validator or to devnet
const connection = new Connection("http://localhost:8899", "confirmed");
//const connection = new Connection("https://api.devnet.solana.com", "confirmed");
// We load the keypair that we created in a previous step
const keyPair = await getKeypairFromFile("~/.config/solana/id.json");
// Every transaction requires a blockhash
const blockhashInfo = await connection.getLatestBlockhash();
// Create a new transaction
const tx = new Transaction({
...blockhashInfo,
});
// Add our Hello World instruction
tx.add(
new TransactionInstruction({
programId: programId,
keys: [],
data: Buffer.from([]),
})
);
// Sign the transaction with your previously created keypair
tx.sign(keyPair);
// Send the transaction to the Solana network
const txHash = await connection.sendRawTransaction(tx.serialize());
console.log("Transaction sent with hash:", txHash);
await connection.confirmTransaction({
blockhash: blockhashInfo.blockhash,
lastValidBlockHeight: blockhashInfo.lastValidBlockHeight,
signature: txHash,
});
console.log(
`Congratulations! Look at your ‘Hello World' transaction in the Solana Explorer:
https://explorer.solana.com/tx/${txHash}?cluster=custom`
);
}
main();
Run:
npx ts-node hello-world-client.ts
Output:
(base) dylan@smalltown ~/Code/solana/projects/solana-web3-example (master)> npx ts-node hello-world-client.ts
(node:4408) ExperimentalWarning: CommonJS module /usr/local/lib/node_modules/npm/node_modules/debug/src/node.js is loading ES Module /usr/local/lib/node_modules/npm/node_modules/supports-color/index.js using require().
Support for loading ES Module in require() is an experimental feature and might change at any time
(Use `node --trace-warnings ...` to show where the warning was created)
(node:4467) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead.
(Use `node --trace-deprecation ...` to show where the warning was created)
Transaction sent with hash: 29aFYDNv1cyrByA8FTBxrhohJx3H1FVLSUordaA1RVcXSNSy7zN5mGW5rwj6pDuopMvvoBaKNHeKmQ8c17uVnqoN
Congratulations! Look at your ‘Hello World' transaction in the Solana Explorer:
https://explorer.solana.com/tx/29aFYDNv1cyrByA8FTBxrhohJx3H1FVLSUordaA1RVcXSNSy7zN5mGW5rwj6pDuopMvvoBaKNHeKmQ8c17uVnqoN?cluster=custom
Some experiments
Which versions can successfully compile and test
First, check the versions of build-sbf and test-sbf we installed:
# build-sbf version
> cargo build-sbf --version
solana-cargo-build-sbf 2.1.4
platform-tools v1.43
rustc 1.79.0
# test-sbf version
> cargo test-sbf --version
solana-cargo-test-sbf 2.1.4
We test which versions can compile and test correctly through this command: rm -rf target Cargo.lock && cargo build-sbf && cargo test-sbf
| version | DevDependencies & Dependencies | NOTE |
|---|---|---|
| ✅2.1.4 | cargo add solana-sdk@2.1.4 solana-program-test@2.1.4 tokio --dev && cargo add solana-program@2.1.4 | latest version |
| ✅2.0.18 | cargo add solana-sdk@2.0.18 solana-program-test@2.0.18 tokio --dev && cargo add solana-program@2.0.18 | latest version |
| ✅2.0.3 | cargo add solana-sdk@2.0.3 solana-program-test@2.0.3 tokio --dev && cargo add solana-program@2.0.3 | |
| ✅1.18.26 | cargo add solana-sdk@1.18.26 solana-program-test@1.18.26 tokio --dev && cargo add solana-program@1.18.26 |
Here is an example of Cargo.toml (corresponding to version 2.0.3):
[package]
name = "hello_world"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib", "lib"]
[dependencies]
solana-program = "2.0.3"
[dev-dependencies]
solana-program-test = "2.0.3"
solana-sdk = "2.0.3"
tokio = "1.42.0"
Test
About the test of solana program, we usually use:
bankrun is a lightweight framework for testing Solana programs in Node.js. Compared to the traditional solana-test-validator, it provides higher speed and convenience. It can achieve some functions that solana-test-validator cannot, such as time rollback and dynamic setting of account data.
It starts a lightweight BanksServer, which is similar to an RPC node but faster, and creates a BanksClient to communicate with the server.
Main features:
- High efficiency: Much faster than solana-test-validator.
- Flexibility: Supports time rollback and dynamic account data setting.
- solana-bankrun is based on solana-program-test, using a lightweight BanksServer and BanksClient.
Next, let's see how to write test cases using Rust (solana-program-test) and NodeJS (solana-bankrun).
Test (Rust)
First, let's use Rust code to test.
First, install the dependencies required for testing:
cargo add solana-sdk@1.18.26 solana-program-test@1.18.26 tokio --dev
# NOTE: There's no error like `Exceeding maximum ...` when building with solana-program = 2.1.4
# We use solana cli with version `2.1.4`
# To install solana-cli with version 2.1.4, run this command:
#
# sh -c "$(curl -sSfL https://release.anza.xyz/v2.1.4/install)"
#
# cargo add solana-sdk@=2.1.4 solana-program-test@=2.1.4 tokio --dev
# cargo add solana-program@=2.1.4
We have tested that versions 2.1.4, 2.0.18, 2.0.3, and 1.18.26 can successfully compile and test, so we only selected version 1.18.26 for demonstration.
Test result output:
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo test-sbf
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished `release` profile [optimized] target(s) in 2.46s
Blocking waiting for file lock on build directory
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished `test` profile [unoptimized + debuginfo] target(s) in 14.29s
Running unittests src/lib.rs (target/debug/deps/hello_world-823cf88515d0fd05)
running 1 test
[2024-12-06T02:00:47.545448000Z INFO solana_program_test] "hello_world" SBF program from /Users/dylan/Code/solana/projects/hello_world/target/deploy/hello_world.so, modified 16 seconds, 964 ms, 380 µs and 220 ns ago
[2024-12-06T02:00:47.750627000Z DEBUG solana_runtime::message_processor::stable_log] Program 1111111QLbz7JHiBTspS962RLKV8GndWFwiEaqKM invoke [1]
[2024-12-06T02:00:47.750876000Z DEBUG solana_runtime::message_processor::stable_log] Program log: Hello, world!
[2024-12-06T02:00:47.750906000Z DEBUG solana_runtime::message_processor::stable_log] Program 1111111QLbz7JHiBTspS962RLKV8GndWFwiEaqKM consumed 137 of 200000 compute units
[2024-12-06T02:00:47.750953000Z DEBUG solana_runtime::message_processor::stable_log] Program 1111111QLbz7JHiBTspS962RLKV8GndWFwiEaqKM success
test test::test_hello_world ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.21s
Doc-tests hello_world
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Test (NodeJS)
Next, let's use NodeJS to write test cases.
First, use pnpm to create a new project.
mkdir hello_world_frontend
cd hello_world_frontend
# Initialize pnpm project
pnpm init
Next, install the dependencies:
# Install necessary dependencies
pnpm add -D typescript ts-node @types/node chai ts-mocha solana-bankrun
pnpm add @solana/web3.js solana-bankrun
Next, write the test program:
import {
PublicKey,
Transaction,
TransactionInstruction,
} from "@solana/web3.js";
import { start } from "solana-bankrun";
import { describe, test } from "node:test";
import { assert } from "chai";
describe("hello-solana", async () => {
// load program in solana-bankrun
const PROGRAM_ID = PublicKey.unique();
const context = await start(
[{ name: "hello_world", programId: PROGRAM_ID }],
[]
);
const client = context.banksClient;
const payer = context.payer;
test("Say hello!", async () => {
const blockhash = context.lastBlockhash;
// We set up our instruction first.
let ix = new TransactionInstruction({
// using payer keypair from context to sign the txn
keys: [{ pubkey: payer.publicKey, isSigner: true, isWritable: true }],
programId: PROGRAM_ID,
data: Buffer.alloc(0), // No data
});
const tx = new Transaction();
tx.recentBlockhash = blockhash;
// using payer keypair from context to sign the txn
tx.add(ix).sign(payer);
// Now we process the transaction
let transaction = await client.processTransaction(tx);
assert(transaction.logMessages[0].startsWith("Program " + PROGRAM_ID));
const message = "Program log: " + "Hello, world! GM!GN!";
console.log("🌈🌈🌈 ");
console.log(transaction.logMessages[1]);
// NOTE: transaction.logMesages is an array:
//
// [
// 'Program 11111111111111111111111111111112 invoke [1]',
// 'Program log: Hello, world! GM!GN!',
// 'Program 11111111111111111111111111111112 consumed 340 of 200000 compute units',
// 'Program 11111111111111111111111111111112 success'
// ]
assert(transaction.logMessages[1] === message);
assert(
transaction.logMessages[2] ===
"Program log: Our program's Program ID: " + PROGRAM_ID
);
assert(
transaction.logMessages[3].startsWith(
"Program " + PROGRAM_ID + " consumed"
)
);
assert(transaction.logMessages[4] === "Program " + PROGRAM_ID + " success");
assert(transaction.logMessages.length == 5);
});
});
First, we generate a context through the start function, which will have the bankClient and payer account for interacting with the bankServer.
Next, we prepare the transaction Instruction through the TransactionInstruction class, and send the transaction by signing the message with the payer account.
let ix = new TransactionInstruction({
keys: [{ pubkey: payer.publicKey, isSigner: true, isWritable: true }],
programId: PROGRAM_ID,
data: Buffer.alloc(0), // No data
});
Create a new transaction instruction (TransactionInstruction), the definition and parameter type TransactionInstructionCtorFields of TransactionInstruction are as follows:
/**
* Transaction Instruction class
*/
declare class TransactionInstruction {
/**
* Public keys to include in this transaction
* Boolean represents whether this pubkey needs to sign the transaction
*/
keys: Array<AccountMeta>;
/**
* Program Id to execute
*/
programId: PublicKey;
/**
* Program input
*/
data: Buffer;
constructor(opts: TransactionInstructionCtorFields);
}
/**
* List of TransactionInstruction object fields that may be initialized at construction
*/
type TransactionInstructionCtorFields = {
keys: Array<AccountMeta>;
programId: PublicKey;
data?: Buffer;
};
About the TransactionInstructionCtorFields:
keys: The public key (payer's public key) to sign.programId: The ID of the program.data: There is no additional data.
Next, we prepare the data of Transaction.
First, Transaction needs the latest block hash, which can be obtained from context.lastBlockhash.
const blockhash = context.lastBlockhash;
Next, we create the transaction.
const tx = new Transaction();
tx.recentBlockhash = blockhash;
tx.add(ix).sign(payer);
Creating a new transaction (Transaction) requires the following steps:
- Set the latest block hash.
- Add the previously defined instruction (
tx.add), and sign the transaction with the payer's key (.sign).
The add function converts parameters to an array type using Javascript's Rest parameters feature, and each array type is a union type of Transaction | TransactionInstruction | TransactionInstructionCtorFields.
declare class Transaction {
/**
* Signatures for the transaction. Typically created by invoking the
* `sign()` method
*/
signatures: Array<SignaturePubkeyPair>;
/**
* The first (payer) Transaction signature
*
* @returns {Buffer | null} Buffer of payer's signature
*/
get signature(): Buffer | null;
/**
* The transaction fee payer
*/
feePayer?: PublicKey;
/**
* The instructions to atomically execute
*/
instructions: Array<TransactionInstruction>;
/**
* Add one or more instructions to this Transaction
*
* @param {Array< Transaction | TransactionInstruction | TransactionInstructionCtorFields >} items - Instructions to add to the Transaction
*/
add(
...items: Array<
Transaction | TransactionInstruction | TransactionInstructionCtorFields
>
): Transaction;
}
After creating the transaction, send it through client.processTransaction and wait for the result.
let transaction = await client.processTransaction(tx);
Here is the definition of processTransaction:
/**
* A client for the ledger state, from the perspective of an arbitrary validator.
*
* The client is used to send transactions and query account data, among other things.
* Use `start()` to initialize a BanksClient.
*/
export declare class BanksClient {
constructor(inner: BanksClientInner);
private inner;
/**
* Send a transaction and return immediately.
* @param tx - The transaction to send.
*/
sendTransaction(tx: Transaction | VersionedTransaction): Promise<void>;
/**
* Process a transaction and return the result with metadata.
* @param tx - The transaction to send.
* @returns The transaction result and metadata.
*/
processTransaction(
tx: Transaction | VersionedTransaction
): Promise<BanksTransactionMeta>;
}
Its inner is a BanksClient, which can do many things besides processing transactions, as shown below.
export class BanksClient {
getAccount(address: Uint8Array, commitment?: CommitmentLevel | undefined | null): Promise<Account | null>
sendLegacyTransaction(txBytes: Uint8Array): Promise<void>
sendVersionedTransaction(txBytes: Uint8Array): Promise<void>
processLegacyTransaction(txBytes: Uint8Array): Promise<BanksTransactionMeta>
processVersionedTransaction(txBytes: Uint8Array): Promise<BanksTransactionMeta>
tryProcessLegacyTransaction(txBytes: Uint8Array): Promise<BanksTransactionResultWithMeta>
tryProcessVersionedTransaction(txBytes: Uint8Array): Promise<BanksTransactionResultWithMeta>
simulateLegacyTransaction(txBytes: Uint8Array, commitment?: CommitmentLevel | undefined | null): Promise<BanksTransactionResultWithMeta>
simulateVersionedTransaction(txBytes: Uint8Array, commitment?: CommitmentLevel | undefined | null): Promise<BanksTransactionResultWithMeta>
getTransactionStatus(signature: Uint8Array): Promise<TransactionStatus | null>
getTransactionStatuses(signatures: Array<Uint8Array>): Promise<Array<TransactionStatus | undefined | null>>
getSlot(commitment?: CommitmentLevel | undefined | null): Promise<bigint>
getBlockHeight(commitment?: CommitmentLevel | undefined | null): Promise<bigint>
getRent(): Promise<Rent>
getClock(): Promise<Clock>
getBalance(address: Uint8Array, commitment?: CommitmentLevel | undefined | null): Promise<bigint>
getLatestBlockhash(commitment?: CommitmentLevel | undefined | null): Promise<BlockhashRes | null>
getFeeForMessage(messageBytes: Uint8Array, commitment?: CommitmentLevel | undefined | null): Promise<bigint | null>
}
/**
* Process a transaction and return the result with metadata.
* @param tx - The transaction to send.
* @returns The transaction result and metadata.
*/
async processTransaction(
tx: Transaction | VersionedTransaction,
): Promise<BanksTransactionMeta> {
const serialized = tx.serialize();
const internal = this.inner;
const inner =
tx instanceof Transaction
? await internal.processLegacyTransaction(serialized)
: await internal.processVersionedTransaction(serialized);
return new BanksTransactionMeta(inner);
}
processTransaction first serializes the transaction through serialize, determines whether it belongs to LegacyTransaction or VersionedTransaction, and then calls the asynchronous methods processLegacyTransaction or processVersionedTransaction respectively, and returns the result through BanksTransactionMeta.
And BanksTransactionMeta contains the logMessages, returnData, and computeUnitsConsumed properties.
export class TransactionReturnData {
get programId(): Uint8Array;
get data(): Uint8Array;
}
export class BanksTransactionMeta {
get logMessages(): Array<string>;
get returnData(): TransactionReturnData | null;
get computeUnitsConsumed(): bigint;
}
Among them, logMessages is a string array used to store log messages related to the transaction. We can verify the test results through these log messages.
For example, you can verify that the solana program is invoked by checking the logMessages[0] to start with Program + PROGRAM_ID:
assert(transaction.logMessages[0].startsWith("Program " + PROGRAM_ID));
An example of a simple logMessages array:
[
"Program 11111111111111111111111111111112 invoke [1]",
"Program log: Hello, world! GM!GN!",
"Program log: Our program's Program ID: {program_id}",
"Program 11111111111111111111111111111112 consumed 443 of 200000 compute units",
"Program 11111111111111111111111111111112 success"
]
Note that in our solana program, the first msg! output is Hello, world! GM!GN!, but in the logMessages array returned by sending the transaction, it is the second element. What is the reason for this?
#![allow(unused)] fn main() { pub fn process_instruction( program_id: &Pubkey, _accounts: &[AccountInfo], _instruction_data: &[u8], ) -> ProgramResult { msg!("Hello, world! GM!GN!"); // NOTE: You must not use interpolating string like this, as it will not // output the string value correctly. // // You must use placeholder instead. // // Below is the transaction.logMessages array when using interpolating string // // [ // 'Program 11111111111111111111111111111112 invoke [1]', // 'Program log: Hello, world! GM!GN!', // "Program log: Our program's Program ID: {program_id}", // 'Program 11111111111111111111111111111112 consumed 443 of 200000 compute units', // 'Program 11111111111111111111111111111112 success' // ] // msg!("Our program's Program ID: {program_id}"); msg!("Our program's Program ID: {}", program_id); Ok(()) } }
The reason is that when the solana program is executed, the program runtime prints the invoked log through the program_invoke function, which is here: Program 11111111111111111111111111111112 invoke [1]. You can find the code of the program_invoke function in anza-xyz/agave.
#![allow(unused)] fn main() { /// Log a program invoke. /// /// The general form is: /// /// ```notrust /// "Program <address> invoke [<depth>]" /// ``` pub fn program_invoke( log_collector: &Option<Rc<RefCell<LogCollector>>>, program_id: &Pubkey, invoke_depth: usize, ) { ic_logger_msg!( log_collector, "Program {} invoke [{}]", program_id, invoke_depth ); } }
The subsequent checks can be performed step by step according to the specific business scenario.
For example, the following checks the content of the first msg! print in the solana program:
const message = "Program log: " + "Hello, world! GM!GN!";
assert(transaction.logMessages[1] === message);
Next, check the content of the second msg! print in the solana program:
assert(transaction.logMessages[1] === message);
assert(
transaction.logMessages[2] ===
"Program log: Our program's Program ID: " + PROGRAM_ID
);
Next, check the content and format of other log messages, including the success message of the program and the consumed compute units, and ensure the total number of log messages is 5.
assert(
transaction.logMessages[3].startsWith("Program " + PROGRAM_ID + " consumed")
);
assert(transaction.logMessages[4] === "Program " + PROGRAM_ID + " success");
assert(transaction.logMessages.length == 5);
So far, a simple test written through NodeJS is ready.
All in one test setup script
If you are lazy, you can directly run the following script to setup.sh, and run bash setup.sh.
# Create test directory
mkdir hello_world_frontend
cd hello_world_frontend
# Initialize pnpm project
pnpm init
# Install necessary dependencies
pnpm add -D typescript ts-node @types/node chai ts-mocha solana-bankrun
pnpm add @solana/web3.js solana-bankrun
# Create TypeScript configuration file
cat > tsconfig.json << EOF
{
"compilerOptions": {
"target": "es2020",
"module": "commonjs",
"strict": true,
"esModuleInterop": true,
"skipLibCheck": true,
"forceConsistentCasingInFileNames": true,
"outDir": "./dist",
"rootDir": "./src"
},
"include": ["src/**/*"],
"exclude": ["node_modules"]
}
EOF
# Create source code directory and test file
mkdir -p tests
cat > tests/hello_world.test.ts << EOF
import {
PublicKey,
Transaction,
TransactionInstruction,
} from "@solana/web3.js";
import { start } from "solana-bankrun";
import { describe, test } from "node:test";
import { assert } from "chai";
describe("hello-solana", async () => {
// load program in solana-bankrun
const PROGRAM_ID = PublicKey.unique();
const context = await start(
[{ name: "hello_world", programId: PROGRAM_ID }],
[],
);
const client = context.banksClient;
const payer = context.payer;
test("Say hello!", async () => {
const blockhash = context.lastBlockhash;
// We set up our instruction first.
let ix = new TransactionInstruction({
// using payer keypair from context to sign the txn
keys: [{ pubkey: payer.publicKey, isSigner: true, isWritable: true }],
programId: PROGRAM_ID,
data: Buffer.alloc(0), // No data
});
const tx = new Transaction();
tx.recentBlockhash = blockhash;
// using payer keypair from context to sign the txn
tx.add(ix).sign(payer);
// Now we process the transaction
let transaction = await client.processTransaction(tx);
assert(transaction.logMessages[0].startsWith("Program " + PROGRAM_ID));
const message = "Program log: " + "Hello, world! GM!GN!";
console.log("🌈🌈🌈 ");
console.log(transaction.logMessages);
assert(transaction.logMessages[1] === message);
assert(
transaction.logMessages[2] ===
"Program log: Our program's Program ID: " + PROGRAM_ID,
);
assert(
transaction.logMessages[3].startsWith(
"Program " + PROGRAM_ID + " consumed",
),
);
assert(transaction.logMessages[4] === "Program " + PROGRAM_ID + " success");
assert(transaction.logMessages.length == 5);
});
});
EOF
# Update package.json to add test script
cat > package.json << EOF
{
"name": "hello_world_frontend",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "pnpm ts-mocha -p ./tsconfig.json -t 1000000 ./tests/hello_world.test.ts"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"@types/jest": "^29.5.11",
"@types/node": "^20.10.5",
"chai": "^5.1.2",
"jest": "^29.7.0",
"solana-bankrun": "^0.4.0",
"ts-jest": "^29.1.1",
"ts-mocha": "^10.0.0",
"ts-node": "^10.9.2",
"typescript": "^5.3.3"
},
"dependencies": {
"@solana/web3.js": "^1.87.6"
}
}
# Run test
pnpm test
EOF
Frontend
There are two methods to develop solana frontend:
- Using Anchor framework
- Not using Anchor framework
I will help you implement both methods to develop Solana frontend. Let's start from the most basic one, and build step by step.
1. Not using Anchor framework
First, create a new Next.js project:
npx create-next-app@latest solana-frontend-nextjs --typescript --tailwind --eslint
cd solana-frontend-nextjs
Install necessary dependencies:
pnpm install \
@solana/web3.js \
@solana/wallet-adapter-react \
@solana/wallet-adapter-react-ui \
@solana/wallet-adapter-base \
@solana/wallet-adapter-wallets
1.1 Basic setup
First, create a wallet configuration file:
'use client'
import { FC, ReactNode, useMemo } from "react";
import {
ConnectionProvider,
WalletProvider,
} from "@solana/wallet-adapter-react";
import { WalletModalProvider } from "@solana/wallet-adapter-react-ui";
import { clusterApiUrl } from "@solana/web3.js";
import {
PhantomWalletAdapter,
SolflareWalletAdapter,
} from "@solana/wallet-adapter-wallets";
require("@solana/wallet-adapter-react-ui/styles.css");
export const WalletContextProvider: FC<{ children: ReactNode }> = ({ children }) => {
const url = useMemo(() => clusterApiUrl("devnet"), []);
const wallets = useMemo(
() => [
new PhantomWalletAdapter(),
new SolflareWalletAdapter(),
],
[]
);
return (
<ConnectionProvider endpoint={url}>
<WalletProvider wallets={wallets} autoConnect>
<WalletModalProvider>{children}</WalletModalProvider>
</WalletProvider>
</ConnectionProvider>
);
};
Update the layout file:
import { WalletContextProvider } from '@/context/WalletContextProvider'
import './globals.css'
export default function RootLayout({
children,
}: {
children: React.ReactNode
}) {
return (
<html lang="en">
<body>
<WalletContextProvider>
{children}
</WalletContextProvider>
</body>
</html>
)
}
1.2 Create main page component
Note that you need to replace the PROGRAM_ID in the src/app/page.tsx file with your program ID.
'use client'
import { useConnection, useWallet } from '@solana/wallet-adapter-react'
import { WalletMultiButton } from '@solana/wallet-adapter-react-ui'
import { LAMPORTS_PER_SOL, PublicKey, Transaction, TransactionInstruction } from '@solana/web3.js'
import { FC, useState } from 'react'
const Home: FC = () => {
const { connection } = useConnection()
const { publicKey, sendTransaction } = useWallet()
const [loading, setLoading] = useState(false)
// Replace with your program ID
const PROGRAM_ID = new PublicKey("3KUbj4gMH77adZnZhatXutJ695qCGzB6G8cmMU1SYMWW")
const sayHello = async () => {
if (!publicKey) {
alert("Please connect your wallet!")
return
}
setLoading(true)
try {
const instruction = new TransactionInstruction({
keys: [
{
pubkey: publicKey,
isSigner: true,
isWritable: true,
},
],
programId: PROGRAM_ID,
data: Buffer.from([]),
})
const transaction = new Transaction()
transaction.add(instruction)
const signature = await sendTransaction(transaction, connection)
await connection.confirmTransaction(signature)
alert("Transaction successful!")
} catch (error) {
console.error(error)
alert(`Error: ${error instanceof Error ? error.message : String(error)}`)
} finally {
setLoading(false)
}
}
return (
<main className="flex min-h-screen flex-col items-center justify-between p-24">
<div className="z-10 max-w-5xl w-full items-center justify-between font-mono text-sm">
<div className="flex flex-col items-center gap-8">
<h1 className="text-4xl font-bold">Solana Hello World</h1>
<WalletMultiButton />
{publicKey && (
<button
onClick={sayHello}
disabled={loading}
className="bg-blue-500 hover:bg-blue-700 text-white font-bold py-2 px-4 rounded"
>
{loading ? "Processing..." : "Say Hello"}
</button>
)}
</div>
</div>
</main>
)
}
export default Home
1.3 Run project
Run:
pnpm dev
Click the Say Hello button to send a transaction through phantom wallet, and you can see the transaction details on the explorer:
https://explorer.solana.com/tx/4H3nfuDqaz1s6TDGe3HSL6DsEvq9r3TwcGqqw9kfGGk3c9pjK2HGohmCrfWcZCFXdMJsPobsbcj3UAdmkj2QK8vd?cluster=devnet
2. Using Anchor framework
Create a new project:
npx create-next-app@latest solana-anchor-frontend-nextjs --typescript --tailwind --eslint
cd solana-anchor-frontend-nextjs
Install dependencies:
pnpm install \
@project-serum/anchor \
@solana/web3.js \
@solana/wallet-adapter-react \
@solana/wallet-adapter-react-ui \
@solana/wallet-adapter-base \
@solana/wallet-adapter-wallets
2.1 Create Anchor IDL type
export type HelloWorld = {
"version": "0.1.0",
"name": "hello_world",
"instructions": [
{
"name": "sayHello",
"accounts": [],
"args": []
}
]
};
export const IDL: HelloWorld = {
"version": "0.1.0",
"name": "hello_world",
"instructions": [
{
"name": "sayHello",
"accounts": [],
"args": []
}
]
};
2.2 Create Anchor workspace provider
"use client";
import { createContext, useContext, ReactNode } from "react"
import { Program, AnchorProvider } from "@project-serum/anchor"
import { AnchorWallet, useAnchorWallet, useConnection } from "@solana/wallet-adapter-react"
import { HelloWorld, IDL } from "@/idl/hello_world"
import { PublicKey } from "@solana/web3.js"
const WorkspaceContext = createContext({})
interface Workspace {
program?: Program<HelloWorld>
}
export const WorkspaceProvider = ({ children }: { children: ReactNode }) => {
const { connection } = useConnection()
const wallet = useAnchorWallet()
const provider = new AnchorProvider(
connection,
wallet as AnchorWallet,
AnchorProvider.defaultOptions()
)
const program = new Program(
IDL,
new PublicKey("3KUbj4gMH77adZnZhatXutJ695qCGzB6G8cmMU1SYMWW"),
provider
)
const workspace = {
program,
}
return (
<WorkspaceContext.Provider value={workspace}>
{children}
</WorkspaceContext.Provider>
)
}
export const useWorkspace = (): Workspace => {
return useContext(WorkspaceContext) as Workspace
}
2.3 Update layout component
import { WalletContextProvider } from '@/context/WalletContextProvider'
import { WorkspaceProvider } from '@/context/WorkspaceProvider'
import './globals.css'
export default function RootLayout({
children,
}: {
children: React.ReactNode
}) {
return (
<html lang="en">
<body>
<WalletContextProvider>
<WorkspaceProvider>
{children}
</WorkspaceProvider>
</WalletContextProvider>
</body>
</html>
)
}
2.4 Create main page component
'use client'
import { useWallet } from '@solana/wallet-adapter-react'
import { WalletMultiButton } from '@solana/wallet-adapter-react-ui'
import { FC, useState } from 'react'
import { useWorkspace } from '@/context/WorkspaceProvider'
const Home: FC = () => {
const { publicKey } = useWallet()
const { program } = useWorkspace()
const [loading, setLoading] = useState(false)
const sayHello = async () => {
if (!publicKey || !program) {
alert("Please connect your wallet!")
return
}
setLoading(true)
try {
const tx = await program.methods
.sayHello()
.accounts({})
.rpc()
alert(`Transaction successful! Signature: ${tx}`)
} catch (error) {
console.error(error)
alert(`Error: ${error instanceof Error ? error.message : String(error)}`)
} finally {
setLoading(false)
}
}
return (
<main className="flex min-h-screen flex-col items-center justify-between p-24">
<div className="z-10 max-w-5xl w-full items-center justify-between font-mono text-sm">
<div className="flex flex-col items-center gap-8">
<h1 className="text-4xl font-bold">Solana Hello World (Anchor)</h1>
<WalletMultiButton />
{publicKey && (
<button
onClick={sayHello}
disabled={loading}
className="bg-blue-500 hover:bg-blue-700 text-white font-bold py-2 px-4 rounded"
>
{loading ? "Processing..." : "Say Hello"}
</button>
)}
</div>
</div>
</main>
)
}
export default Home
2.5 tsconfig.json configuration
To correctly use @ path aliases, you need to configure the tsconfig.json file:
{
"compilerOptions": {
"target": "ES2017",
"lib": ["dom", "dom.iterable", "esnext"],
"allowJs": true,
"skipLibCheck": true,
"strict": true,
"noEmit": true,
"esModuleInterop": true,
"module": "esnext",
"moduleResolution": "bundler",
"resolveJsonModule": true,
"isolatedModules": true,
"jsx": "preserve",
"incremental": true,
"plugins": [
{
"name": "next"
}
],
"paths": {
"@/*": ["./*"],
"@/idl/*": ["./app/idl/*"],
"@/context/*": ["./app/context/*"]
}
},
"include": ["next-env.d.ts", "**/*.ts", "**/*.tsx", ".next/types/**/*.ts"],
"exclude": ["node_modules"]
}
This configuration file adds aliases for @/idl/* and @/context/* to use these paths in the code.
2.6 Run project
Run:
pnpm dev
Click the Say Hello button to send a transaction through phantom wallet, and you can see the transaction details on the explorer:
https://explorer.solana.com/tx/5dustfzfhSopVKrDiL3CoXAg35jimMBs3oFkxDsiBqM1xQ6t4JnsonbdZirzYdR5i5HGsUKmfhKZb3NQunWDbWiw?cluster=devnet
Key Differences Between Two Methods
- Without Anchor:
- Directly use
@solana/web3.jsto create transactions and instructions - Manually construct transaction structures
- Lower-level control
- With Anchor:
- Use Anchor IDL type definitions
- Higher-level abstractions and type safety
- More concise program invocation
- Better development experience
Which method to choose depends on your needs:
- If you need more low-level control or have a smaller project, you can choose not to use Anchor
- If you need better development experience and type safety, it's recommended to use Anchor
Next Steps
At this point, we have completed the development and deployment of a basic Solana program. Although this program simply prints "Hello, world!", it contains the fundamental elements of Solana program development:
- Program entry point definition
- Basic parameter structure
- Build and deployment process
In the upcoming content, we will learn:
- How to develop programs using the Anchor framework
- How to handle account data
- How to implement more complex instruction logic
- How to test programs
- How to ensure program security
Stay tuned!
Refs
Explanation about cargo-build-sbf https://github.com/solana-labs/solana/issues/34987#issuecomment-1913538260
https://solana.stackexchange.com/questions/16443/error-function-stack-offset-of-7256-exceeded-max-offset-of-4096-by-3160-bytes
Installing Solana CLI tool suites (Note: Don't install edge version as it may cause deployment issues) https://solana.com/docs/intro/installation
https://github.com/solana-labs/solana/issues/34987#issuecomment-1914665002 https://github.com/anza-xyz/agave/issues/1572
Writing a Hello World program on Solana https://solana.com/developers/guides/getstarted/local-rust-hello-world#create-a-new-rust-library-with-cargo
solana wallet nextjs setup https://solana.com/developers/guides/wallets/add-solana-wallet-adapter-to-nextjs
https://solana.com/developers/cookbook/wallets/connect-wallet-react https://www.anza.xyz/blog/solana-web3-js-2-release
https://solana.stackexchange.com/questions/1723/anchor-useanchorwallet-vs-solanas-usewallet
anchor client side development https://solana.com/developers/courses/onchain-development/intro-to-anchor-frontend
不使用 Anchor 开发 solana program
初始化工程
使用 Cargo 初始化工程
我们可以使用 cargo 来初始化工程。
cargo init hello_world --lib
编写代码
程序入口 entrypoint
下面利用 entrypoint 来编写程序入口。
entrypoint macro 需要一个函数参数,作为 solana program 的入口函数。
#![allow(unused)] fn main() { pub fn process_instruction() -> ProgramResult { msg!("Hello, world!"); Ok(()) } }
如果传递给 entrypoint macro 的函数签名不符合要求,编译时会报错:
Checking hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
error[E0061]: this function takes 0 arguments but 3 arguments were supplied
--> src/lib.rs:6:1
|
6 | entrypoint!(process_instruction);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
| |
| unexpected argument #1 of type `&Pubkey`
| unexpected argument #2 of type `&Vec<AccountInfo<'_>>`
| unexpected argument #3 of type `&[u8]`
|
note: function defined here
--> src/lib.rs:8:8
|
8 | pub fn process_instruction() -> ProgramResult {
| ^^^^^^^^^^^^^^^^^^^
= note: this error originates in the macro `entrypoint` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0061`.
error: could not compile `hello_world` (lib) due to 1 previous error
修改 process_instruction 函数的签名
给 process_instruction 函数添加三个参数:
program_id:&Pubkey类型,表示当前程序的公钥地址accounts:&[AccountInfo]类型,是一个 AccountInfo 数组的引用,包含了交易涉及的所有账户信息instruction_data:&[u8]类型,是指令的输入数据,以字节数组的形式传入
这三个参数是 Solana 程序执行时的基本要素:
program_id用于验证程序身份和权限accounts包含了程序需要读取或修改的所有账户数据instruction_data携带了调用程序时传入的具体指令数据
#![allow(unused)] fn main() { pub fn process_instruction( _program_id: &Pubkey, _accounts: &[AccountInfo], _instruction_data: &[u8], ) -> ProgramResult { msg!("Hello, world!"); Ok(()) } }
注意这里参数名前加了下划线前缀(_),是因为在这个简单的示例中我们暂时没有使用这些参数,这样可以避免编译器的未使用变量警告。在实际开发中,这些参数都是非常重要的,我们会在后续的示例中详细介绍如何使用它们。
关于函数签名,我们也可以参考 solana_program_entrypoint 这个 crate 的文档:
#![allow(unused)] fn main() { /// fn process_instruction( /// program_id: &Pubkey, // Public key of the account the program was loaded into /// accounts: &[AccountInfo], // All accounts required to process the instruction /// instruction_data: &[u8], // Serialized instruction-specific data /// ) -> ProgramResult; }
构建程序
使用 cargo build-sbf 构建程序
为了构建 solana program,我们需要使用 cargo build-sbf 程序。
cargo build-sbf
构建失败了,以下是报错信息。
dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf
error: package `solana-program v2.1.4` cannot be built because it requires rustc 1.79.0 or newer, while the currently active rustc version is 1.75.0-dev
Either upgrade to rustc 1.79.0 or newer, or use
cargo update solana-program@2.1.4 --precise ver
where `ver` is the latest version of `solana-program` supporting rustc 1.75.0-dev
我们可以通过 --version 参数来查看 rustc 的版本信息。
cargo-build-sbf --version
输出:
solana-cargo-build-sbf 1.18.25
platform-tools v1.41
rustc 1.75.0
关于系统版本的 rust compiler 和 build-sbf 使用的 rust compiler 不对应的问题,可以参考这个 issue。 https://github.com/solana-labs/solana/issues/34987
解决 build-sbf 编译失败问题
一种方式是使用旧版本的 solana-program,如 =1.17.0 版本。
[package]
name = "hello_world"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib", "lib"]
[dependencies]
solana-program = "=1.17.0"
# solana-program = "=1.18.0"
但是运行 cargo build-sbf 之后,出现了另外的错误。
error: failed to parse lock file at: /Users/dylan/Code/solana/projects/hello_world/Cargo.lock
Caused by:
lock file version 4 requires `-Znext-lockfile-bump`
猜测可能是 build-sbf 使用的 cargo 版本不支持 version = 4 版本的 Cargo.lock 文件,而这个是编辑器(vscode/cursor)打开的状态下,rust-analyser 自动生成的。
安装 stable 版本的 solana cli 工具链: sh -c "$(curl -sSfL https://release.anza.xyz/stable/install)",发现还是无法编译,报错如下:
dylan@smalltown ~/Code/solana/projects/hello_world (master)> sh -c "$(curl -sSfL https://release.anza.xyz/stable/install)"
downloading stable installer
✨ stable commit 7104d71 initialized
dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf --version
solana-cargo-build-sbf 2.0.17
platform-tools v1.42
dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf
[2024-12-04T11:14:48.052020000Z ERROR cargo_build_sbf] Failed to install platform-tools: HTTP status client error (404 Not Found) for url (https://github.com/anza-xyz/platform-tools/releases/download/v1.42/platform-tools-osx-x86_64.tar.bz2)
在进行 cargo build-sbf 编译的时候,需要下载对应版本的 platform-tools,因为未发布针对 Mac(Intel) 的 v1.42 版本 的 platform-tools,所以上述命令运行失败。
dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf
Compiling cc v1.2.2
Compiling serde v1.0.215
Compiling solana-frozen-abi-macro v1.17.0
Compiling ahash v0.7.8
Compiling solana-frozen-abi v1.17.0
Compiling either v1.13.0
Compiling bs58 v0.4.0
Compiling log v0.4.22
Compiling hashbrown v0.11.2
Compiling itertools v0.10.5
Compiling solana-sdk-macro v1.17.0
Compiling bytemuck v1.20.0
Compiling borsh v0.9.3
Compiling num-derive v0.3.3
Compiling blake3 v1.5.5
Compiling solana-program v1.17.0
Compiling bv v0.11.1
Compiling serde_json v1.0.133
Compiling serde_bytes v0.11.15
Compiling bincode v1.3.3
Error: Function _ZN112_$LT$solana_program..instruction..InstructionError$u20$as$u20$solana_frozen_abi..abi_example..AbiEnumVisitor$GT$13visit_for_abi17hc69c00f4c61717f8E Stack offset of 6640 exceeded max offset of 4096 by 2544 bytes, please minimize large stack variables. Estimated function frame size: 6680 bytes. Exceeding the maximum stack offset may cause undefined behavior during execution.
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished `release` profile [optimized] target(s) in 25.19s
+ ./platform-tools/rust/bin/rustc --version
+ ./platform-tools/rust/bin/rustc --print sysroot
+ set +e
+ rustup toolchain uninstall solana
info: uninstalling toolchain 'solana'
info: toolchain 'solana' uninstalled
+ set -e
+ rustup toolchain link solana platform-tools/rust
+ exit 0
⏎
dylan@smalltown ~/Code/solana/projects/hello_world (master)> ls target/deploy/
hello_world-keypair.json hello_world.so
dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf --version
solana-cargo-build-sbf 2.1.4
platform-tools v1.43
rustc 1.79.0
dylan@smalltown ~/Code/solana/projects/hello_world (master) [1]> sh -c "$(curl -sSfL https://release.anza.xyz/beta/install)"
downloading beta installer
✨ beta commit 024d047 initialized
dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf --version
solana-cargo-build-sbf 2.1.4
platform-tools v1.43
rustc 1.79.0
dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf
Error: Function _ZN112_$LT$solana_program..instruction..InstructionError$u20$as$u20$solana_frozen_abi..abi_example..AbiEnumVisitor$GT$13visit_for_abi17hc69c00f4c61717f8E Stack offset of 6640 exceeded max offset of 4096 by 2544 bytes, please minimize large stack variables. Estimated function frame size: 6680 bytes. Exceeding the maximum stack offset may cause undefined behavior during execution.
Finished `release` profile [optimized] target(s) in 0.23s
使用 beta 版本的 solana cli tool suites 虽然能够编译,但是遇到了这个错误:
Exceeding the maximum stack offset may cause undefined behavior during execution.
Compiling bincode v1.3.3
Error: Function _ZN112_$LT$solana_program..instruction..InstructionError$u20$as$u20$solana_frozen_abi..abi_example..AbiEnumVisitor$GT$13visit_for_abi17hc69c00f4c61717f8E Stack offset of 6640 exceeded max offset of 4096 by 2544 bytes, please minimize large stack variables. Estimated function frame size: 6680 bytes. Exceeding the maximum stack offset may cause undefined behavior during execution.
具体原因依旧是老生常谈的版本问题,原因分析可以参考: https://solana.stackexchange.com/questions/16443/error-function-stack-offset-of-7256-exceeded-max-offset-of-4096-by-3160-bytes
尝试更新 solana-program 的版本到 2.1.4 之后(运行 sh -c "$(curl -sSfL https://release.anza.xyz/v2.1.4/install)"),用以下版本的工具链进行编译:
> cargo build-sbf --version
solana-cargo-build-sbf 2.1.4
platform-tools v1.43
rustc 1.79.0
# solana-cargo-build-sbf 2.2.0
# platform-tools v1.43
# rustc 1.79.0
运行 cargo build-sbf:
> cargo build-sbf
Compiling serde v1.0.215
Compiling equivalent v1.0.1
Compiling hashbrown v0.15.2
Compiling toml_datetime v0.6.8
Compiling syn v2.0.90
Compiling winnow v0.6.20
Compiling cfg_aliases v0.2.1
Compiling once_cell v1.20.2
Compiling borsh v1.5.3
Compiling solana-define-syscall v2.1.4
Compiling solana-sanitize v2.1.4
Compiling solana-atomic-u64 v2.1.4
Compiling bs58 v0.5.1
Compiling bytemuck v1.20.0
Compiling five8_core v0.1.1
Compiling five8_const v0.1.3
Compiling solana-decode-error v2.1.4
Compiling solana-msg v2.1.4
Compiling cc v1.2.2
Compiling solana-program-memory v2.1.4
Compiling log v0.4.22
Compiling solana-native-token v2.1.4
Compiling solana-program-option v2.1.4
Compiling indexmap v2.7.0
Compiling blake3 v1.5.5
Compiling toml_edit v0.22.22
Compiling serde_derive v1.0.215
Compiling bytemuck_derive v1.8.0
Compiling solana-sdk-macro v2.1.4
Compiling thiserror-impl v1.0.69
Compiling num-derive v0.4.2
Compiling proc-macro-crate v3.2.0
Compiling borsh-derive v1.5.3
Compiling thiserror v1.0.69
Compiling solana-secp256k1-recover v2.1.4
Compiling solana-borsh v2.1.4
Compiling solana-hash v2.1.4
Compiling bincode v1.3.3
Compiling bv v0.11.1
Compiling solana-serde-varint v2.1.4
Compiling serde_bytes v0.11.15
Compiling solana-fee-calculator v2.1.4
Compiling solana-short-vec v2.1.4
Compiling solana-sha256-hasher v2.1.4
Compiling solana-pubkey v2.1.4
Compiling solana-instruction v2.1.4
Compiling solana-sysvar-id v2.1.4
Compiling solana-slot-hashes v2.1.4
Compiling solana-clock v2.1.4
Compiling solana-epoch-schedule v2.1.4
Compiling solana-last-restart-slot v2.1.4
Compiling solana-rent v2.1.4
Compiling solana-program-error v2.1.4
Compiling solana-stable-layout v2.1.4
Compiling solana-serialize-utils v2.1.4
Compiling solana-account-info v2.1.4
Compiling solana-program-pack v2.1.4
Compiling solana-bincode v2.1.4
Compiling solana-slot-history v2.1.4
Compiling solana-program-entrypoint v2.1.4
Compiling solana-cpi v2.1.4
Compiling solana-program v2.1.4
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished `release` profile [optimized] target(s) in 50.87s
总算编译成功了,开瓶香槟庆祝一下吧!
这里是 Cargo.toml 文件:
[package]
name = "hello_world"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib", "lib"]
[dependencies]
solana-program = "2.1.4"
# solana-program = "=1.17.0"
构建产物
cargo build-sbf 是 Solana 提供的一个特殊的构建命令,用于将 Rust 程序编译成可以在 Solana 运行时环境中执行的 BPF (Berkeley Packet Filter) 字节码。这个命令做了以下几件事:
-
使用特定的 Rust 工具链编译代码
- 使用针对 Solana 优化的 Rust 编译器
- 使用
bpfel-unknown-unknown目标平台 - 启用发布模式优化
-
生成必要的部署文件
- 编译出
.so文件(共享对象文件) - 生成程序密钥对(如果不存在)
- 优化和压缩最终的二进制文件
- 编译出
-
验证编译结果
- 检查程序大小是否在限制范围内
- 验证程序格式是否正确
命令执行流程:
- 首先检查并下载必要的工具链
- 使用 cargo 编译项目
- 对编译产物进行后处理(如剥离调试信息)
- 将最终文件放置在
target/deploy目录
这个命令替代了早期的 cargo build-bpf,提供了更好的构建体验和更现代的工具链支持。
我们来看看具体生成了哪些文件,运行 cargo build-sbf 这个命令之后会在 target/deploy 目录下生成两个重要文件:
hello_world.so:编译后的程序文件,这是一个 BPF (Berkeley Packet Filter) 格式的可执行文件hello_world-keypair.json:程序的密钥对文件,用于程序的部署和升级
如果你看到类似下面的输出,说明构建成功:
BPF SDK: /Users/username/.local/share/solana/install/releases/1.14.x/solana-release/bin/sdk/bpf
cargo-build-sbf child: rustup toolchain list -v
cargo-build-sbf child: cargo +bpf build --target bpfel-unknown-unknown --release
Finished release [optimized] target(s) in 0.20s
cargo-build-sbf child: /Users/username/.local/share/solana/install/releases/1.14.x/solana-release/bin/sdk/bpf/scripts/strip.sh /Users/username/projects/hello_world/target/bpfel-unknown-unknown/release/hello_world.so /Users/username/projects/hello_world/target/deploy/hello_world.so
部署
现在我们可以将编译好的程序部署到 Solana 网络上。在开发阶段,我们通常使用本地测试网(localhost)或开发网(devnet)进行测试。
首先确保你的 Solana CLI 配置指向了正确的集群:
# 切换到开发网
solana config set --url devnet
# 切换到本地测试网
solana config set --url localnet
# 查看当前配置
solana config get
然后使用以下命令部署程序:
solana program deploy target/deploy/hello_world.so
部署成功后,你会看到程序的 ID(公钥地址)。请保存这个地址,因为在后续与程序交互时会需要它。
但是,当我们通过运行 solana program deploy 命令来部署程序的时候,部署失败了。
dylan@smalltown ~/Code/solana/projects/helloworld (master)> solana program deploy ./target/deploy/helloworld.so
⠁ 0.0% | Sending 1/173 transactions [block height 2957; re-sign in 150 blocks]
thread 'main' panicked at quic-client/src/nonblocking/quic_client.rs:142:14:
QuicLazyInitializedEndpoint::create_endpoint bind_in_range: Os { code: 55, kind: Uncategorized, message: "No buffer space available" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
那么这个 No buffer space available 是什么意思呢?
排查了很久终于无果,凭借多年的经验,大概率应该是 版本 的问题,因为通过 Anchor 创建的工程是能够正常部署的。
这里记录一下 solana 命令的版本信息:
> solana --version
solana-cli 2.2.0 (src:67704836; feat:1081947060, client:Agave)
回到 Anchor 工程验证部署失败源自版本的问题
我们可以通过 anchor init helloworld 新建工程,并通过 anchor build 和 anchor deploy 来部署程序。
anchor init helloworld
cd helloworld
anchor build
anchor deploy
从出错信息了解到,全新生成的 anchor 工程部署的时候会发生同样的错误:No buffer space available
dylan@smalltown ~/tmp/helloworld (main)> anchor deploy
Deploying cluster: https://api.devnet.solana.com
Upgrade authority: /Users/dylan/.config/solana/id.json
Deploying program "helloworld"...
Program path: /Users/dylan/tmp/helloworld/target/deploy/helloworld.so...
⠁ 0.0% | Sending 1/180 transactions [block height 332937196; re-sign in 150 blocks] thread 'main' panicked at quic-client/src/nonblocking/quic_client.rs:142:14:
QuicLazyInitializedEndpoint::create_endpoint bind_in_range: Os { code: 55, kind: Uncategorized, message: "No buffer space available" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
There was a problem deploying: Output { status: ExitStatus(unix_wait_status(25856)), stdout: "", stderr: "" }.
检查下 anchor 的版本:
dylan@smalltown ~/tmp/helloworld (main)> anchor deploy --help
Deploys each program in the workspace
Usage: anchor-0.30.1 deploy [OPTIONS] [-- <SOLANA_ARGS>...]
Arguments:
[SOLANA_ARGS]... Arguments to pass to the underlying `solana program deploy` command
Options:
-p, --program-name <PROGRAM_NAME> Only deploy this program
--provider.cluster <CLUSTER> Cluster override
--program-keypair <PROGRAM_KEYPAIR> Keypair of the program (filepath) (requires program-name)
--provider.wallet <WALLET> Wallet override
-v, --verifiable If true, deploy from path target/verifiable
-h, --help Print help
检查下 solana 的版本:
> solana --version
solana-cli 2.2.0 (src:67704836; feat:1081947060, client:Agave)
这个 2.2.0 的版本看着有些奇怪,忽然想到为了编译 solana 程序,我安装了 edge 版本的 solana cli,其携带的 solana cli 的版本是 2.2.0:
sh -c "$(curl -sSfL https://release.anza.xyz/edge/install)"
于是换回了 stable 版本:
> sh -c "$(curl -sSfL https://release.anza.xyz/stable/install)"
downloading stable installer
✨ stable commit fbead11 initialized
而 stable 版本的 solana 是 2.0.19。
> solana --version
solana-cli 2.0.19 (src:fbead118; feat:607245837, client:Agave)
重新部署程序之前,我们先来清理下之前部署失败的程序的 buffers,也就是 buffer accounts。关于什么是 buffer accounts,请参考 Tips 3。
- 查看所有的 buffer accounts:
solana program show --buffers - 关闭所有的 buffer accounts:
solana program close --buffers- 关闭 buffer accounts 可以回收存储在 buffer accounts 里的 SOL
Error: error sending request for url (https://api.devnet.solana.com/): operation timed out
dylan@smalltown ~/tmp/helloworld (main)> solana program show --buffers
Buffer Address | Authority | Balance
CcKFVBzcsrcReZHBLnwzkQbNGXoK4hUee7hkgtbHCKtL | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 0.12492504 SOL
62wFzMYBhxWg4ntEJmFZcQ3P3Qtm9SbaBcbTmV8o8yPk | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 0.12492504 SOL
9q88jzvR5AdPdNTihxWroxRL7cBWQ5xXepNfDdaqmMTv | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 1.26224472 SOL
3nqzHv9vUphsmAjoR1C5ShgZ54muTzkZZ6Z4NKfqrKqt | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 1.26224472 SOL
8tZ8YYA1WS6WFVyEbJAdgnszXYZwwq7b9RLdoiry2Fb1 | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 0.12492504 SOL
dylan@smalltown ~/tmp/helloworld (main)> solana program close --buffers
Buffer Address | Authority | Balance
CcKFVBzcsrcReZHBLnwzkQbNGXoK4hUee7hkgtbHCKtL | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 0.12492504 SOL
62wFzMYBhxWg4ntEJmFZcQ3P3Qtm9SbaBcbTmV8o8yPk | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 0.12492504 SOL
9q88jzvR5AdPdNTihxWroxRL7cBWQ5xXepNfDdaqmMTv | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 1.26224472 SOL
3nqzHv9vUphsmAjoR1C5ShgZ54muTzkZZ6Z4NKfqrKqt | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 1.26224472 SOL
8tZ8YYA1WS6WFVyEbJAdgnszXYZwwq7b9RLdoiry2Fb1 | FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH | 0.12492504 SOL
好了 buffer accounts 清理完毕,此时我们也换回了 stable 版本的 solana cli,我们再尝试部署程序:
> anchor deploy
Deploying cluster: https://api.devnet.solana.com
Upgrade authority: /Users/dylan/.config/solana/id.json
Deploying program "helloworld"...
Program path: /Users/dylan/tmp/helloworld/target/deploy/helloworld.so...
Program Id: DiSGTiXGq4HXCxq1pAibuGZjSpKT4Av8WShvuuYhTks9
Signature: 2EXHmU68k9SmJ5mXuM61pFDnUgozbJZ5ihHChPqFMVgjRJy4zCqnq6NAbvDkfiHd29xsmW4Vr3Kk6wHFbLEdCEZb
Deploy success
成功了 🎉,再开一瓶香槟庆祝下吧!
这更加深了我们的猜测:版本问题导致程序无法部署。
再回来部署我们的 hello_world 工程
好了,验证了部署失败不是工程类型(anchor project or cargo projct)导致的原因之后,我们再回到 cargo init 创建的工程:hello_world.
我们可以通过 solana 的子命令来部署程序: 运行 solana program deploy ./target/deploy/helloworld.so 部署程序。
我们会分别在 localnet 和 devnet 部署。
localnet 部署
首先是 localnet 部署。
切换环境到 localnet:
dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana_local
Config File: /Users/dylan/.config/solana/cli/config.yml
RPC URL: http://localhost:8899
WebSocket URL: ws://localhost:8900/ (computed)
Keypair Path: /Users/dylan/.config/solana/id.json
Commitment: confirmed
dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana config get
Config File: /Users/dylan/.config/solana/cli/config.yml
RPC URL: http://localhost:8899
WebSocket URL: ws://localhost:8900/ (computed)
Keypair Path: /Users/dylan/.config/solana/id.json
Commitment: confirmed
部署程序:
dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana program deploy ./target/deploy/hello_world.so
Program Id: DhQr1KGGQcf8BeU5uQvR35p2kgKqEinD45PRTDDRqx7z
Signature: 3WVEWN4NUodsb8ZDjbjrTWXLikZ7wbWCuzuRZtSBmyKL4kVvESSeLwKZ3cJo1At4vDcaBs5iEcHhdteyXCwqwmDw
devnet 部署
下面是 devnet 部署。
切换环境到 localnet:
dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana_devnet
Config File: /Users/dylan/.config/solana/cli/config.yml
RPC URL: https://api.devnet.solana.com
WebSocket URL: wss://api.devnet.solana.com/ (computed)
Keypair Path: /Users/dylan/.config/solana/id.json
Commitment: confirmed
dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana config get
Config File: /Users/dylan/.config/solana/cli/config.yml
RPC URL: https://api.devnet.solana.com
WebSocket URL: wss://api.devnet.solana.com/ (computed)
Keypair Path: /Users/dylan/.config/solana/id.json
Commitment: confirmed
dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana program deploy ./target/deploy/hello_world.so
Program Id: DhQr1KGGQcf8BeU5uQvR35p2kgKqEinD45PRTDDRqx7z
Signature: 4P89gHNUNccQKJAsE3aXJVpFrWeqLxcmk9SYHbQCX7T1sEvyPrxcbrAeJbk8F8YKwWT79nTswSZkz7mtSb55nboF
我们可以通过 solana balance 来查询下部署前后的余额
# 部署之前余额
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana balance
75.153619879 SOL
# 部署之后余额
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master)> solana balance
75.152378439 SOL
而此时的版本:
dylan@smalltown ~/Code/solana/projects/helloworld (master)> solana --version
solana-cli 2.0.19 (src:fbead118; feat:607245837, client:Agave)
由此可见,不要尝鲜用最新的版本(solana-cli 2.2.0),否则会弄巧成拙。
Tips
Tip 1: solana cli 的版本和 Cargo.toml 里的版本保持一致
在 solana 的官方教程里提到这个 Tip:
It is highly recommended to keep your solana-program and other Solana Rust dependencies in-line with your installed version of the Solana CLI. For example, if you are running Solana CLI 2.0.3, you can instead run:
cargo add solana-program@"=2.0.3"
This will ensure your crate uses only 2.0.3 and nothing else. If you experience compatibility issues with Solana dependencies, check out the
Tip 2: 不要在 dependencies 里添加 solana-sdk,因为这是 offchain 使用的
参考这里的说明: https://solana.stackexchange.com/questions/9109/cargo-build-bpf-failed
I have identified the issue. The solana-sdk is designed for off-chain use only, so it should be removed from the dependencies.
错误将 solana-sdk 添加到 dependencies 报错:
Compiling autocfg v1.4.0
Compiling jobserver v0.1.32
error: target is not supported, for more information see: https://docs.rs/getrandom/#unsupported-targets
--> src/lib.rs:267:9
|
267 | / compile_error!("\
268 | | target is not supported, for more information see: \
269 | | https://docs.rs/getrandom/#unsupported-targets\
270 | | ");
| |__________^
error[E0433]: failed to resolve: use of undeclared crate or module `imp`
--> src/lib.rs:291:5
|
291 | imp::getrandom_inner(dest)
| ^^^ use of undeclared crate or module `imp`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `getrandom` (lib) due to 2 previous errors
warning: build failed, waiting for other jobs to finish...
Tip 3: 关于 buffer accounts
在 Solana 中,buffer accounts 是用于程序部署过程中的一种临时账户,它是 Solana 部署程序时的一个重要机制。由于 Solana 的交易大小限制为 1232 字节,部署程序时通常需要多个交易步骤。在这个过程中,buffer account 的作用是存储程序的字节码,直到部署完成。
buffer account 的关键点:
- 临时存储:buffer account 用于存放程序的字节码,确保在部署过程中能够处理较大的程序。
- 自动关闭:一旦程序成功部署,相关的 buffer account 会自动关闭,从而释放占用的资源。
- 失败处理:如果部署失败,buffer account 不会自动删除,用户可以选择:
- 继续使用现有的 buffer account 来完成部署。
- 关闭 buffer account,以便回收已分配的 SOL(租金)。
- 检查 buffer accounts:可以通过命令
solana program show --buffers来检查当前是否存在未关闭的 buffer accounts。 - 关闭 buffer accounts:可以通过命令
solana program close --buffers来关闭 buffer accounts。
关于 solana 程序部署的过程的解释,可以查考官方文档: https://solana.com/docs/programs/deploying#program-deployment-process
重新部署
重新部署只需要编辑代码之后运行 cargo build-sbf 编译代码,再通过 solana program deply ./target/deploy/hello_world.so 部署即可。
cargo build-sbf
solana program deploy ./target/deploy/hello_world.so
可以通过运行测试和 client 脚本来验证运行的是新版本的 program。
# 运行测试
cargo test-sbf
# 运行 client 脚本
cargo run --example client
比如,我修改 msg! 输入内容为 Hello, world! GM!GN!,运行测试和 client 脚本能够看到 log 里有这个输出。
#![allow(unused)] fn main() { pub fn process_instruction( _program_id: &Pubkey, _accounts: &[AccountInfo], _instruction_data: &[u8], ) -> ProgramResult { msg!("Hello, world! GM!GN!"); Ok(()) } }
运行测试:
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo test-sbf
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished release [optimized] target(s) in 1.76s
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished `test` profile [unoptimized + debuginfo] target(s) in 13.92s
Running unittests src/lib.rs (target/debug/deps/hello_world-ee1a919556768e26)
running 1 test
[2024-12-06T08:06:57.714248000Z INFO solana_program_test] "hello_world" SBF program from /Users/dylan/Code/solana/projects/hello_world/target/deploy/hello_world.so, modified 19 seconds, 228 ms, 255 µs and 392 ns ago
[2024-12-06T08:06:57.947344000Z DEBUG solana_runtime::message_processor::stable_log] Program 1111111QLbz7JHiBTspS962RLKV8GndWFwiEaqKM invoke [1]
[2024-12-06T08:06:57.947695000Z DEBUG solana_runtime::message_processor::stable_log] Program log: Hello, world! GM!GN!
[2024-12-06T08:06:57.947738000Z DEBUG solana_runtime::message_processor::stable_log] Program 1111111QLbz7JHiBTspS962RLKV8GndWFwiEaqKM consumed 140 of 200000 compute units
[2024-12-06T08:06:57.947897000Z DEBUG solana_runtime::message_processor::stable_log] Program 1111111QLbz7JHiBTspS962RLKV8GndWFwiEaqKM success
test test::test_hello_world ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.24s
Doc-tests hello_world
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
TODO: image
最佳实践
安装 solana-cli 的最佳实践
最好的方式是安装指定版本的 solana cli,如可以用以下方式安装 2.0.3 的版本:
# 安装 stable 和 beta 都不推荐
# sh -c "$(curl -sSfL https://release.anza.xyz/stable/install)"
# sh -c "$(curl -sSfL https://release.anza.xyz/beta/install)"
# 推荐安装指定版本
sh -c "$(curl -sSfL https://release.anza.xyz/v2.0.3/install)"
输出:
downloading v2.0.3 installer
✨ 2.0.3 initialized
运行 cargo build-sbf --version 查看下 cargo build-sbf 的版本:
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master) [1]> cargo build-sbf --version
solana-cargo-build-sbf 2.0.3
platform-tools v1.41
rustc 1.75.0
可以看到,这里的 rustc 版本是 1.75.0,比较老旧,编译的时候必须带上 -Znext-lockfile-bump 参数,否则编译出错:
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf
info: uninstalling toolchain 'solana'
info: toolchain 'solana' uninstalled
error: failed to parse lock file at: /Users/dylan/Code/solana/projects/hello_world/Cargo.lock
Caused by:
lock file version 4 requires `-Znext-lockfile-bump`
以下是传递 -Znext-lockfile-bump 参数之后,完整的编译过程:
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo build-sbf -- -Znext-lockfile-bump
Compiling proc-macro2 v1.0.92
Compiling unicode-ident v1.0.14
Compiling version_check v0.9.5
Compiling typenum v1.17.0
Compiling autocfg v1.4.0
Compiling serde v1.0.215
Compiling syn v1.0.109
Compiling cfg-if v1.0.0
Compiling equivalent v1.0.1
Compiling hashbrown v0.15.2
Compiling semver v1.0.23
Compiling generic-array v0.14.7
Compiling ahash v0.8.11
Compiling winnow v0.6.20
Compiling indexmap v2.7.0
Compiling toml_datetime v0.6.8
Compiling shlex v1.3.0
Compiling quote v1.0.37
Compiling subtle v2.6.1
Compiling cc v1.2.2
Compiling syn v2.0.90
Compiling once_cell v1.20.2
Compiling rustversion v1.0.18
Compiling feature-probe v0.1.1
Compiling zerocopy v0.7.35
Compiling cfg_aliases v0.2.1
Compiling borsh v1.5.3
Compiling bv v0.11.1
Compiling rustc_version v0.4.1
Compiling num-traits v0.2.19
Compiling memoffset v0.9.1
Compiling thiserror v1.0.69
Compiling toml_edit v0.22.22
Compiling blake3 v1.5.5
Compiling block-buffer v0.10.4
Compiling crypto-common v0.1.6
Compiling solana-program v2.0.3
Compiling digest v0.10.7
Compiling hashbrown v0.13.2
Compiling constant_time_eq v0.3.1
Compiling bs58 v0.5.1
Compiling arrayvec v0.7.6
Compiling arrayref v0.3.9
Compiling keccak v0.1.5
Compiling sha2 v0.10.8
Compiling toml v0.5.11
Compiling sha3 v0.10.8
Compiling proc-macro-crate v3.2.0
Compiling borsh-derive-internal v0.10.4
Compiling borsh-schema-derive-internal v0.10.4
Compiling getrandom v0.2.15
Compiling lazy_static v1.5.0
Compiling bytemuck v1.20.0
Compiling log v0.4.22
Compiling proc-macro-crate v0.1.5
Compiling serde_derive v1.0.215
Compiling thiserror-impl v1.0.69
Compiling num-derive v0.4.2
Compiling solana-sdk-macro v2.0.3
Compiling bytemuck_derive v1.8.0
Compiling borsh-derive v1.5.3
Compiling borsh-derive v0.10.4
Compiling borsh v0.10.4
Compiling serde_bytes v0.11.15
Compiling bincode v1.3.3
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished release [optimized] target(s) in 2m 28s
+ ./platform-tools/rust/bin/rustc --version
+ ./platform-tools/rust/bin/rustc --print sysroot
+ set +e
+ rustup toolchain uninstall solana
info: uninstalling toolchain 'solana'
info: toolchain 'solana' uninstalled
+ set -e
+ rustup toolchain link solana platform-tools/rust
+ exit 0
值得注意的是,无论是安装 stable 版本还是 beta 版本都会导致编译失败,stable 版本运行 cargo build-sbf 会去 github release 页面下载针对 x86_64 架构的 platform-tools,但是官方没有发布提供针对这个版本的 platform-tools。以下是出错信息:
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master) [1]> cargo build-sbf --version
solana-cargo-build-sbf 2.0.19
platform-tools v1.42
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master) [1]> cargo build-sbf
[2024-12-05T06:17:30.547088000Z ERROR cargo_build_sbf] Failed to install platform-tools: HTTP status client error (404 Not Found) for url (https://github.com/anza-xyz/platform-tools/releases/download/v1.42/platform-tools-osx-x86_64.tar.bz2)
发现如果指定 --tools-version 为 v1.43 也不能成功编译。
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master) [1]> cargo build-sbf --tools-version v1.43
Blocking waiting for file lock on package cache
Blocking waiting for file lock on package cache
Compiling blake3 v1.5.5
Compiling solana-program v2.0.3
Compiling bs58 v0.5.1
Compiling solana-sdk-macro v2.0.3
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished `release` profile [optimized] target(s) in 1m 16s
+ curl -L https://github.com/anza-xyz/platform-tools/releases/download/v1.42/platform-tools-osx-x86_64.tar.bz2 -o platform-tools-osx-x86_64.tar.bz2
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 9 100 9 0 0 16 0 --:--:-- --:--:-- --:--:-- 16
+ tar --strip-components 1 -jxf platform-tools-osx-x86_64.tar.bz2
tar: Error opening archive: Unrecognized archive format
+ return 1
+ popd
+ return 1
/Users/dylan/.local/share/solana/install/releases/stable-fbead118867c08e6c3baaf8d196897c2536f067a/solana-release/bin/sdk/sbf/scripts/strip.sh: line 23: /Users/dylan/.local/share/solana/install/releases/stable-fbead118867c08e6c3baaf8d196897c2536f067a/solana-release/bin/sdk/sbf/dependencies/platform-tools/llvm/bin/llvm-objcopy: No such file or directory
所以还是老老实实安装指定版本的 solana cli 吧。
如何查看部署的 program
我们可以通过访问以下地址来查看部署的 program。
https://explorer.solana.com/?cluster=custom
它会自动用本地的 localhost:8899 作为 rpc endpoint,在搜索栏搜索 program id,即可看到 transaction 详情。
客户端调用
客户调用程序 (Rust) (invoke solana program)
首先创建 examples 目录,并在 examples 目录下创建 client.rs 文件。
mkdir -p examples
touch examples/client.rs
在 Cargo.toml 增加以下内容:
[[example]]
name = "client"
path = "examples/client.rs"
添加 solana-client 依赖:
cargo add solana-client@1.18.26 --dev
添加以下代码到 examples/client.rs,注意替换你自己部署的 program ID:
use solana_client::rpc_client::RpcClient; use solana_sdk::{ commitment_config::CommitmentConfig, instruction::Instruction, pubkey::Pubkey, signature::{Keypair, Signer}, transaction::Transaction, }; use std::str::FromStr; #[tokio::main] async fn main() { // Program ID (replace with your actual program ID) let program_id = Pubkey::from_str("85K3baeo8tvZBmuty2UP8mMVd1vZtxLkmeUkj1s6tnT6").unwrap(); // Connect to the Solana devnet let rpc_url = String::from("http://127.0.0.1:8899"); let client = RpcClient::new_with_commitment(rpc_url, CommitmentConfig::confirmed()); // Generate a new keypair for the payer let payer = Keypair::new(); // Request airdrop let airdrop_amount = 1_000_000_000; // 1 SOL let signature = client .request_airdrop(&payer.pubkey(), airdrop_amount) .expect("Failed to request airdrop"); // Wait for airdrop confirmation loop { let confirmed = client.confirm_transaction(&signature).unwrap(); if confirmed { break; } } // Create the instruction let instruction = Instruction::new_with_borsh( program_id, &(), // Empty instruction data vec![], // No accounts needed ); // Add the instruction to new transaction let mut transaction = Transaction::new_with_payer(&[instruction], Some(&payer.pubkey())); transaction.sign(&[&payer], client.get_latest_blockhash().unwrap()); // Send and confirm the transaction match client.send_and_confirm_transaction(&transaction) { Ok(signature) => println!("Transaction Signature: {}", signature), Err(err) => eprintln!("Error sending transaction: {}", err), } }
这个简单的脚本能够调用已部署的 solana program,它主要做了以下几件事:
- 连接本地 RPC
- 创建新账户
- 空投 1 SOL 给新开的账户
- 创建 hello_world program 所需的指令(Instruction)
- 发送交易 (通过
send_and_confirm_transaction)
关于 program ID,我们可以通过 solana address -k <program keypair>.json 命令来获取 program ID:
solana address -k ./target/deploy/hello_world-keypair.json
-k 参数接收 keypair 的文件,可以获得 PublicKey。
运行 client:
cargo run --example client
运行 client 代码的输出:
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo run --example client
Blocking waiting for file lock on package cache
Blocking waiting for file lock on package cache
Blocking waiting for file lock on package cache
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 5.13s
Running `target/debug/examples/client`
Transaction Signature: iPcYzbBCM6kkXvdx5GQLS9WYunT6yWFAp8NeRyNH5ZHbjXNpGuT1pqLAmQZSa2g7mubuFmaCTxqPVS54J4Zz22h
客户端调用(TypeScript)
我们可以通过建立 nodejs 工程来发送交易:
mkdir -p helloworld
npm init -y
npm install --save-dev typescript
npm install @solana/web3.js@1 @solana-developers/helpers@2
建立 tsconfig.json 配置文件:
{
"compilerOptions": {
"target": "es2016",
"module": "commonjs",
"types": ["node"],
"esModuleInterop": true,
"forceConsistentCasingInFileNames": true,
"strict": true,
"skipLibCheck": true
}
}
创建 hello-world-client.ts 文件,注意修改 PublicKey 的参数为你部署时生成的 programID:
import {
Connection,
PublicKey,
Transaction,
TransactionInstruction,
} from "@solana/web3.js";
import { getKeypairFromFile } from "@solana-developers/helpers";
async function main() {
const programId = new PublicKey(
"DhQr1KGGQcf8BeU5uQvR35p2kgKqEinD45PRTDDRqx7z"
);
// Connect to a solana cluster. Either to your local test validator or to devnet
const connection = new Connection("http://localhost:8899", "confirmed");
//const connection = new Connection("https://api.devnet.solana.com", "confirmed");
// We load the keypair that we created in a previous step
const keyPair = await getKeypairFromFile("~/.config/solana/id.json");
// Every transaction requires a blockhash
const blockhashInfo = await connection.getLatestBlockhash();
// Create a new transaction
const tx = new Transaction({
...blockhashInfo,
});
// Add our Hello World instruction
tx.add(
new TransactionInstruction({
programId: programId,
keys: [],
data: Buffer.from([]),
})
);
// Sign the transaction with your previously created keypair
tx.sign(keyPair);
// Send the transaction to the Solana network
const txHash = await connection.sendRawTransaction(tx.serialize());
console.log("Transaction sent with hash:", txHash);
await connection.confirmTransaction({
blockhash: blockhashInfo.blockhash,
lastValidBlockHeight: blockhashInfo.lastValidBlockHeight,
signature: txHash,
});
console.log(
`Congratulations! Look at your ‘Hello World' transaction in the Solana Explorer:
https://explorer.solana.com/tx/${txHash}?cluster=custom`
);
}
main();
运行:
npx ts-node hello-world-client.ts
输出:
(base) dylan@smalltown ~/Code/solana/projects/solana-web3-example (master)> npx ts-node hello-world-client.ts
(node:4408) ExperimentalWarning: CommonJS module /usr/local/lib/node_modules/npm/node_modules/debug/src/node.js is loading ES Module /usr/local/lib/node_modules/npm/node_modules/supports-color/index.js using require().
Support for loading ES Module in require() is an experimental feature and might change at any time
(Use `node --trace-warnings ...` to show where the warning was created)
(node:4467) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead.
(Use `node --trace-deprecation ...` to show where the warning was created)
Transaction sent with hash: 29aFYDNv1cyrByA8FTBxrhohJx3H1FVLSUordaA1RVcXSNSy7zN5mGW5rwj6pDuopMvvoBaKNHeKmQ8c17uVnqoN
Congratulations! Look at your ‘Hello World' transaction in the Solana Explorer:
https://explorer.solana.com/tx/29aFYDNv1cyrByA8FTBxrhohJx3H1FVLSUordaA1RVcXSNSy7zN5mGW5rwj6pDuopMvvoBaKNHeKmQ8c17uVnqoN?cluster=custom
一些实验
哪些版本能成功编译和测试
首先看一下我们安装的 build-sbf 和 test-sbf 的版本:
# build-sbf 版本
> cargo build-sbf --version
solana-cargo-build-sbf 2.1.4
platform-tools v1.43
rustc 1.79.0
# test-sbf 版本
> cargo test-sbf --version
solana-cargo-test-sbf 2.1.4
我们通过这个命令来测试哪些版本能够正确编译和测试: rm -rf target Cargo.lock && cargo build-sbf && cargo test-sbf
| version | DevDependencies & Dependencies | NOTE |
|---|---|---|
| ✅2.1.4 | cargo add solana-sdk@2.1.4 solana-program-test@2.1.4 tokio --dev && cargo add solana-program@2.1.4 | latest version |
| ✅2.0.18 | cargo add solana-sdk@2.0.18 solana-program-test@2.0.18 tokio --dev && cargo add solana-program@2.0.18 | latest version |
| ✅2.0.3 | cargo add solana-sdk@2.0.3 solana-program-test@2.0.3 tokio --dev && cargo add solana-program@2.0.3 | |
| ✅1.18.26 | cargo add solana-sdk@1.18.26 solana-program-test@1.18.26 tokio --dev && cargo add solana-program@1.18.26 |
这里是 Cargo.toml 的例子(对应版本是 2.0.3):
[package]
name = "hello_world"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib", "lib"]
[dependencies]
solana-program = "2.0.3"
[dev-dependencies]
solana-program-test = "2.0.3"
solana-sdk = "2.0.3"
tokio = "1.42.0"
测试
关于 solana 程序的测试,我们一般采用
bankrun 是一个用于在 Node.js 中测试 Solana 程序的轻量级框架。与传统的 solana-test-validator 相比,bankrun 提供了更高的速度和便利性。它能够实现一些 solana-test-validator 无法做到的功能,例如时间回溯和动态设置账户数据。
它会启动一个轻量级的 BanksServer,这个服务类似于一个 RPC 节点,但速度更快,并且创建一个 BanksClient 来与服务器进行通信
主要特点:
- 高效性:比 solana-test-validator 快得多。
- 灵活性:支持时间回溯和动态账户数据设置。
- solana-bankrun 底层基于 solana-program-test,使用轻量级的 BanksServer 和 BanksClient。
接下来,我们来看看如何用 Rust(solana-program-test) 和 NodeJS(solana-bankrun) 编写测试用例。
测试(Rust)
首先,我们来用 Rust 代码进行测试。
首先安装测试所需要的依赖:
cargo add solana-sdk@1.18.26 solana-program-test@1.18.26 tokio --dev
# NOTE: There's no error like `Exceeding maximum ...` when building with solana-program = 2.1.4
# We use solana cli with version `2.1.4`
# To install solana-cli with version 2.1.4, run this command:
#
# sh -c "$(curl -sSfL https://release.anza.xyz/v2.1.4/install)"
#
# cargo add solana-sdk@=2.1.4 solana-program-test@=2.1.4 tokio --dev
# cargo add solana-program@=2.1.4
因为我们已经测试过,对于版本 2.1.4, 2.0.18, 2.0.3, 1.18.26 都能成功编译和测试,所以我们只选择了其中一个版本 1.18.26 来做演示。
测试结果输出:
(base) dylan@smalltown ~/Code/solana/projects/hello_world (master)> cargo test-sbf
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished `release` profile [optimized] target(s) in 2.46s
Blocking waiting for file lock on build directory
Compiling hello_world v0.1.0 (/Users/dylan/Code/solana/projects/hello_world)
Finished `test` profile [unoptimized + debuginfo] target(s) in 14.29s
Running unittests src/lib.rs (target/debug/deps/hello_world-823cf88515d0fd05)
running 1 test
[2024-12-06T02:00:47.545448000Z INFO solana_program_test] "hello_world" SBF program from /Users/dylan/Code/solana/projects/hello_world/target/deploy/hello_world.so, modified 16 seconds, 964 ms, 380 µs and 220 ns ago
[2024-12-06T02:00:47.750627000Z DEBUG solana_runtime::message_processor::stable_log] Program 1111111QLbz7JHiBTspS962RLKV8GndWFwiEaqKM invoke [1]
[2024-12-06T02:00:47.750876000Z DEBUG solana_runtime::message_processor::stable_log] Program log: Hello, world!
[2024-12-06T02:00:47.750906000Z DEBUG solana_runtime::message_processor::stable_log] Program 1111111QLbz7JHiBTspS962RLKV8GndWFwiEaqKM consumed 137 of 200000 compute units
[2024-12-06T02:00:47.750953000Z DEBUG solana_runtime::message_processor::stable_log] Program 1111111QLbz7JHiBTspS962RLKV8GndWFwiEaqKM success
test test::test_hello_world ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.21s
Doc-tests hello_world
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
测试(NodeJS)
接下来,我们来用 NodeJS 编写测试用例。
首先使用 pnpm 新建工程。
mkdir hello_world_frontend
cd hello_world_frontend
# 初始化 pnpm 项目
pnpm init
接下来安装依赖:
# 安装必要的依赖
pnpm add -D typescript ts-node @types/node chai ts-mocha solana-bankrun
pnpm add @solana/web3.js solana-bankrun
然后,编写测试程序:
import {
PublicKey,
Transaction,
TransactionInstruction,
} from "@solana/web3.js";
import { start } from "solana-bankrun";
import { describe, test } from "node:test";
import { assert } from "chai";
describe("hello-solana", async () => {
// load program in solana-bankrun
const PROGRAM_ID = PublicKey.unique();
const context = await start(
[{ name: "hello_world", programId: PROGRAM_ID }],
[]
);
const client = context.banksClient;
const payer = context.payer;
test("Say hello!", async () => {
const blockhash = context.lastBlockhash;
// We set up our instruction first.
let ix = new TransactionInstruction({
// using payer keypair from context to sign the txn
keys: [{ pubkey: payer.publicKey, isSigner: true, isWritable: true }],
programId: PROGRAM_ID,
data: Buffer.alloc(0), // No data
});
const tx = new Transaction();
tx.recentBlockhash = blockhash;
// using payer keypair from context to sign the txn
tx.add(ix).sign(payer);
// Now we process the transaction
let transaction = await client.processTransaction(tx);
assert(transaction.logMessages[0].startsWith("Program " + PROGRAM_ID));
const message = "Program log: " + "Hello, world! GM!GN!";
console.log("🌈🌈🌈 ");
console.log(transaction.logMessages[1]);
// NOTE: transaction.logMesages is an array:
//
// [
// 'Program 11111111111111111111111111111112 invoke [1]',
// 'Program log: Hello, world! GM!GN!',
// 'Program 11111111111111111111111111111112 consumed 340 of 200000 compute units',
// 'Program 11111111111111111111111111111112 success'
// ]
assert(transaction.logMessages[1] === message);
assert(
transaction.logMessages[2] ===
"Program log: Our program's Program ID: " + PROGRAM_ID
);
assert(
transaction.logMessages[3].startsWith(
"Program " + PROGRAM_ID + " consumed"
)
);
assert(transaction.logMessages[4] === "Program " + PROGRAM_ID + " success");
assert(transaction.logMessages.length == 5);
});
});
首先,我们通过 start 函数生成一个 context,这个 context 里会有和 bankServer 交互的 bankClient 以及 payer 账户。
接下来,通过 TransactionInstruction 来准备交易的 Instruction,发送交易需要对消息进行签名,这里使用 payer 来对交易进行签名,将它放在 keys 数组里。
let ix = new TransactionInstruction({
keys: [{ pubkey: payer.publicKey, isSigner: true, isWritable: true }],
programId: PROGRAM_ID,
data: Buffer.alloc(0), // No data
});
创建一个新的交易指令 (TransactionInstruction),TransactionInstruction 的定义及参数类型 TransactionInstructionCtorFields 如下:
/**
* Transaction Instruction class
*/
declare class TransactionInstruction {
/**
* Public keys to include in this transaction
* Boolean represents whether this pubkey needs to sign the transaction
*/
keys: Array<AccountMeta>;
/**
* Program Id to execute
*/
programId: PublicKey;
/**
* Program input
*/
data: Buffer;
constructor(opts: TransactionInstructionCtorFields);
}
/**
* List of TransactionInstruction object fields that may be initialized at construction
*/
type TransactionInstructionCtorFields = {
keys: Array<AccountMeta>;
programId: PublicKey;
data?: Buffer;
};
关于 TransactionInstructionCtorFields 的说明:
keys: 需要签名的公钥(支付者的公钥)。programId: 程序的 ID。data: 这里没有附加数据。
然后我们准备 Transaction 的数据。
首先 Transaction 需要最近的区块哈希,这个可以从 context 的 lastBlockHash 获取。
const blockhash = context.lastBlockhash;
下面是创建交易的过程。
const tx = new Transaction();
tx.recentBlockhash = blockhash;
tx.add(ix).sign(payer);
创建一个新的交易 (Transaction) 需要如下步骤:
- 设置最近的区块哈希。
- 添加之前定义的指令(
tx.add),并使用支付者的密钥对交易进行签名(.sign)。
add 函数通过 Javascript 的 Rest parameters 特性将参数转换成数组类型,每个数组类型的是 Transaction | TransactionInstruction | TransactionInstructionCtorFields 的联合类型 Union Type。
declare class Transaction {
/**
* Signatures for the transaction. Typically created by invoking the
* `sign()` method
*/
signatures: Array<SignaturePubkeyPair>;
/**
* The first (payer) Transaction signature
*
* @returns {Buffer | null} Buffer of payer's signature
*/
get signature(): Buffer | null;
/**
* The transaction fee payer
*/
feePayer?: PublicKey;
/**
* The instructions to atomically execute
*/
instructions: Array<TransactionInstruction>;
/**
* Add one or more instructions to this Transaction
*
* @param {Array< Transaction | TransactionInstruction | TransactionInstructionCtorFields >} items - Instructions to add to the Transaction
*/
add(
...items: Array<
Transaction | TransactionInstruction | TransactionInstructionCtorFields
>
): Transaction;
}
创建完交易之后,通过 client.processTransaction 发送交易并等到结果。
let transaction = await client.processTransaction(tx);
这里是 processTransaction 的定义:
/**
* A client for the ledger state, from the perspective of an arbitrary validator.
*
* The client is used to send transactions and query account data, among other things.
* Use `start()` to initialize a BanksClient.
*/
export declare class BanksClient {
constructor(inner: BanksClientInner);
private inner;
/**
* Send a transaction and return immediately.
* @param tx - The transaction to send.
*/
sendTransaction(tx: Transaction | VersionedTransaction): Promise<void>;
/**
* Process a transaction and return the result with metadata.
* @param tx - The transaction to send.
* @returns The transaction result and metadata.
*/
processTransaction(
tx: Transaction | VersionedTransaction
): Promise<BanksTransactionMeta>;
}
其 inner 是个 BanksClient,除了处理交易外,它还能干很多事情,以下是它的定义。
export class BanksClient {
getAccount(address: Uint8Array, commitment?: CommitmentLevel | undefined | null): Promise<Account | null>
sendLegacyTransaction(txBytes: Uint8Array): Promise<void>
sendVersionedTransaction(txBytes: Uint8Array): Promise<void>
processLegacyTransaction(txBytes: Uint8Array): Promise<BanksTransactionMeta>
processVersionedTransaction(txBytes: Uint8Array): Promise<BanksTransactionMeta>
tryProcessLegacyTransaction(txBytes: Uint8Array): Promise<BanksTransactionResultWithMeta>
tryProcessVersionedTransaction(txBytes: Uint8Array): Promise<BanksTransactionResultWithMeta>
simulateLegacyTransaction(txBytes: Uint8Array, commitment?: CommitmentLevel | undefined | null): Promise<BanksTransactionResultWithMeta>
simulateVersionedTransaction(txBytes: Uint8Array, commitment?: CommitmentLevel | undefined | null): Promise<BanksTransactionResultWithMeta>
getTransactionStatus(signature: Uint8Array): Promise<TransactionStatus | null>
getTransactionStatuses(signatures: Array<Uint8Array>): Promise<Array<TransactionStatus | undefined | null>>
getSlot(commitment?: CommitmentLevel | undefined | null): Promise<bigint>
getBlockHeight(commitment?: CommitmentLevel | undefined | null): Promise<bigint>
getRent(): Promise<Rent>
getClock(): Promise<Clock>
getBalance(address: Uint8Array, commitment?: CommitmentLevel | undefined | null): Promise<bigint>
getLatestBlockhash(commitment?: CommitmentLevel | undefined | null): Promise<BlockhashRes | null>
getFeeForMessage(messageBytes: Uint8Array, commitment?: CommitmentLevel | undefined | null): Promise<bigint | null>
}
/**
* Process a transaction and return the result with metadata.
* @param tx - The transaction to send.
* @returns The transaction result and metadata.
*/
async processTransaction(
tx: Transaction | VersionedTransaction,
): Promise<BanksTransactionMeta> {
const serialized = tx.serialize();
const internal = this.inner;
const inner =
tx instanceof Transaction
? await internal.processLegacyTransaction(serialized)
: await internal.processVersionedTransaction(serialized);
return new BanksTransactionMeta(inner);
}
processTransaction 会先通过 serialize 对 transaction 进行序列化,判断属于 LegacyTransaction 还是 VersionedTransaction,分别调用 processLegacyTransaction 或 processVersionedTransaction 异步方法,并将结果通过 BanksTransactionMeta 返回。
而 BanksTransactionMeta 包含了 logMessages returnData 和 computeUnitsConsumed 属性。
export class TransactionReturnData {
get programId(): Uint8Array;
get data(): Uint8Array;
}
export class BanksTransactionMeta {
get logMessages(): Array<string>;
get returnData(): TransactionReturnData | null;
get computeUnitsConsumed(): bigint;
}
其中 logMessages 是一个字符串数组,用于存储与交易相关的日志消息。我们可以通过这些日志信息,对测试结果进行验证。
比如,可以通过对 logMessages[0] 验证 solana program 被调用时,会输出以 Program + PROGRAM_ID 开头的内容:
assert(transaction.logMessages[0].startsWith("Program " + PROGRAM_ID));
一个简单的 logMessages 数组的例子:
[
"Program 11111111111111111111111111111112 invoke [1]",
"Program log: Hello, world! GM!GN!",
"Program log: Our program's Program ID: {program_id}",
"Program 11111111111111111111111111111112 consumed 443 of 200000 compute units",
"Program 11111111111111111111111111111112 success"
]
值得注意的是,在我们的 solana program 里,第一个 msg! 输出的日志是 Hello, world! GM!GN!,但是发送交易返回的 logMessages 数组里它在数组的第二个元素,这是什么原因呢?
#![allow(unused)] fn main() { pub fn process_instruction( program_id: &Pubkey, _accounts: &[AccountInfo], _instruction_data: &[u8], ) -> ProgramResult { msg!("Hello, world! GM!GN!"); // NOTE: You must not use interpolating string like this, as it will not // output the string value correctly. // // You must use placeholder instead. // // Below is the transaction.logMessages array when using interpolating string // // [ // 'Program 11111111111111111111111111111112 invoke [1]', // 'Program log: Hello, world! GM!GN!', // "Program log: Our program's Program ID: {program_id}", // 'Program 11111111111111111111111111111112 consumed 443 of 200000 compute units', // 'Program 11111111111111111111111111111112 success' // ] // msg!("Our program's Program ID: {program_id}"); msg!("Our program's Program ID: {}", program_id); Ok(()) } }
其原因是 solana program 执行时 program runtime 会通过 program_invoke 函数打印被调用的日志,也就是这里的: Program 11111111111111111111111111111112 invoke [1]。关于 program_invoke 函数的代码可以在 anza-xyz/agave 这里找到。
#![allow(unused)] fn main() { /// Log a program invoke. /// /// The general form is: /// /// ```notrust /// "Program <address> invoke [<depth>]" /// ``` pub fn program_invoke( log_collector: &Option<Rc<RefCell<LogCollector>>>, program_id: &Pubkey, invoke_depth: usize, ) { ic_logger_msg!( log_collector, "Program {} invoke [{}]", program_id, invoke_depth ); } }
接下来的检查可以根据具体的业务场景按部就班的进行。
比如,下面检查 solana program 里第一个 msg! 打印的内容:
const message = "Program log: " + "Hello, world! GM!GN!";
assert(transaction.logMessages[1] === message);
接下来,检查 solana program 里第二个 msg! 打印的内容:
assert(transaction.logMessages[1] === message);
assert(
transaction.logMessages[2] ===
"Program log: Our program's Program ID: " + PROGRAM_ID
);
再下来,检查其他日志消息的内容和格式,包括程序的成功消息和消耗的计算单位,并确保日志消息的总数为 5。
assert(
transaction.logMessages[3].startsWith("Program " + PROGRAM_ID + " consumed")
);
assert(transaction.logMessages[4] === "Program " + PROGRAM_ID + " success");
assert(transaction.logMessages.length == 5);
至此,一个简单的通过 NodeJS 编写的测试就写好了。
All in one test setup script
如果你比较懒,可以直接运行以下脚本到 setup.sh,并运行 bash setup.sh。
# 创建测试目录
mkdir hello_world_frontend
cd hello_world_frontend
# 初始化 pnpm 项目
pnpm init
# 安装必要的依赖
pnpm add -D typescript ts-node @types/node chai ts-mocha solana-bankrun
pnpm add @solana/web3.js solana-bankrun
# 创建 TypeScript 配置文件
cat > tsconfig.json << EOF
{
"compilerOptions": {
"target": "es2020",
"module": "commonjs",
"strict": true,
"esModuleInterop": true,
"skipLibCheck": true,
"forceConsistentCasingInFileNames": true,
"outDir": "./dist",
"rootDir": "./src"
},
"include": ["src/**/*"],
"exclude": ["node_modules"]
}
EOF
# 创建源代码目录和测试文件
mkdir -p tests
cat > tests/hello_world.test.ts << EOF
import {
PublicKey,
Transaction,
TransactionInstruction,
} from "@solana/web3.js";
import { start } from "solana-bankrun";
import { describe, test } from "node:test";
import { assert } from "chai";
describe("hello-solana", async () => {
// load program in solana-bankrun
const PROGRAM_ID = PublicKey.unique();
const context = await start(
[{ name: "hello_world", programId: PROGRAM_ID }],
[],
);
const client = context.banksClient;
const payer = context.payer;
test("Say hello!", async () => {
const blockhash = context.lastBlockhash;
// We set up our instruction first.
let ix = new TransactionInstruction({
// using payer keypair from context to sign the txn
keys: [{ pubkey: payer.publicKey, isSigner: true, isWritable: true }],
programId: PROGRAM_ID,
data: Buffer.alloc(0), // No data
});
const tx = new Transaction();
tx.recentBlockhash = blockhash;
// using payer keypair from context to sign the txn
tx.add(ix).sign(payer);
// Now we process the transaction
let transaction = await client.processTransaction(tx);
assert(transaction.logMessages[0].startsWith("Program " + PROGRAM_ID));
const message = "Program log: " + "Hello, world! GM!GN!";
console.log("🌈🌈🌈 ");
console.log(transaction.logMessages);
assert(transaction.logMessages[1] === message);
assert(
transaction.logMessages[2] ===
"Program log: Our program's Program ID: " + PROGRAM_ID,
);
assert(
transaction.logMessages[3].startsWith(
"Program " + PROGRAM_ID + " consumed",
),
);
assert(transaction.logMessages[4] === "Program " + PROGRAM_ID + " success");
assert(transaction.logMessages.length == 5);
});
});
EOF
# 更新 package.json 添加测试脚本
cat > package.json << EOF
{
"name": "hello_world_frontend",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "pnpm ts-mocha -p ./tsconfig.json -t 1000000 ./tests/hello_world.test.ts"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"@types/jest": "^29.5.11",
"@types/node": "^20.10.5",
"chai": "^5.1.2",
"jest": "^29.7.0",
"solana-bankrun": "^0.4.0",
"ts-jest": "^29.1.1",
"ts-mocha": "^10.0.0",
"ts-node": "^10.9.2",
"typescript": "^5.3.3"
},
"dependencies": {
"@solana/web3.js": "^1.87.6"
}
}
# 运行测试
pnpm test
EOF
Frontend
我们有两种方法来开发 solana frontend:
- 使用 Anchor 框架
- 不使用 Anchor 框架
我会帮你实现两种方法来开发 Solana frontend。让我们从最基础的开始,逐步构建。
1. 不使用 Anchor 框架
首先创建一个新的 Next.js 项目:
npx create-next-app@latest solana-frontend-nextjs --typescript --tailwind --eslint
cd solana-frontend-nextjs
安装必要的依赖:
pnpm install \
@solana/web3.js \
@solana/wallet-adapter-react \
@solana/wallet-adapter-react-ui \
@solana/wallet-adapter-base \
@solana/wallet-adapter-wallets
1.1 基础设置
首先创建钱包配置文件:
'use client'
import { FC, ReactNode, useMemo } from "react";
import {
ConnectionProvider,
WalletProvider,
} from "@solana/wallet-adapter-react";
import { WalletModalProvider } from "@solana/wallet-adapter-react-ui";
import { clusterApiUrl } from "@solana/web3.js";
import {
PhantomWalletAdapter,
SolflareWalletAdapter,
} from "@solana/wallet-adapter-wallets";
require("@solana/wallet-adapter-react-ui/styles.css");
export const WalletContextProvider: FC<{ children: ReactNode }> = ({ children }) => {
const url = useMemo(() => clusterApiUrl("devnet"), []);
const wallets = useMemo(
() => [
new PhantomWalletAdapter(),
new SolflareWalletAdapter(),
],
[]
);
return (
<ConnectionProvider endpoint={url}>
<WalletProvider wallets={wallets} autoConnect>
<WalletModalProvider>{children}</WalletModalProvider>
</WalletProvider>
</ConnectionProvider>
);
};
更新 layout 文件:
import { WalletContextProvider } from '@/context/WalletContextProvider'
import './globals.css'
export default function RootLayout({
children,
}: {
children: React.ReactNode
}) {
return (
<html lang="en">
<body>
<WalletContextProvider>
{children}
</WalletContextProvider>
</body>
</html>
)
}
1.2 创建主页面组件
注意,要在 src/app/page.tsx 文件中,将 PROGRAM_ID 替换为你的程序 ID。
'use client'
import { useConnection, useWallet } from '@solana/wallet-adapter-react'
import { WalletMultiButton } from '@solana/wallet-adapter-react-ui'
import { LAMPORTS_PER_SOL, PublicKey, Transaction, TransactionInstruction } from '@solana/web3.js'
import { FC, useState } from 'react'
const Home: FC = () => {
const { connection } = useConnection()
const { publicKey, sendTransaction } = useWallet()
const [loading, setLoading] = useState(false)
// 替换为你的程序 ID
const PROGRAM_ID = new PublicKey("3KUbj4gMH77adZnZhatXutJ695qCGzB6G8cmMU1SYMWW")
const sayHello = async () => {
if (!publicKey) {
alert("Please connect your wallet!")
return
}
setLoading(true)
try {
const instruction = new TransactionInstruction({
keys: [
{
pubkey: publicKey,
isSigner: true,
isWritable: true,
},
],
programId: PROGRAM_ID,
data: Buffer.from([]),
})
const transaction = new Transaction()
transaction.add(instruction)
const signature = await sendTransaction(transaction, connection)
await connection.confirmTransaction(signature)
alert("Transaction successful!")
} catch (error) {
console.error(error)
alert(`Error: ${error instanceof Error ? error.message : String(error)}`)
} finally {
setLoading(false)
}
}
return (
<main className="flex min-h-screen flex-col items-center justify-between p-24">
<div className="z-10 max-w-5xl w-full items-center justify-between font-mono text-sm">
<div className="flex flex-col items-center gap-8">
<h1 className="text-4xl font-bold">Solana Hello World</h1>
<WalletMultiButton />
{publicKey && (
<button
onClick={sayHello}
disabled={loading}
className="bg-blue-500 hover:bg-blue-700 text-white font-bold py-2 px-4 rounded"
>
{loading ? "Processing..." : "Say Hello"}
</button>
)}
</div>
</div>
</main>
)
}
export default Home
1.3 运行项目
运行:
pnpm dev
点击 Say Hello 按钮通过 phantom wallet 发送交易,交易成功之后,可以在 explorer 上看到交易详情:
https://explorer.solana.com/tx/4H3nfuDqaz1s6TDGe3HSL6DsEvq9r3TwcGqqw9kfGGk3c9pjK2HGohmCrfWcZCFXdMJsPobsbcj3UAdmkj2QK8vd?cluster=devnet
2. 使用 Anchor 框架
创建新项目:
npx create-next-app@latest solana-anchor-frontend-nextjs --typescript --tailwind --eslint
cd solana-anchor-frontend-nextjs
安装依赖:
pnpm install \
@coral-xyz/anchor \
@solana/web3.js \
@solana/wallet-adapter-react \
@solana/wallet-adapter-react-ui \
@solana/wallet-adapter-base \
@solana/wallet-adapter-wallets
2.1 创建 Anchor IDL 类型
export type HelloWorld = {
"version": "0.1.0",
"name": "hello_world",
"instructions": [
{
"name": "sayHello",
"accounts": [],
"args": []
}
]
};
export const IDL: HelloWorld = {
"version": "0.1.0",
"name": "hello_world",
"instructions": [
{
"name": "sayHello",
"accounts": [],
"args": []
}
]
};
2.2 创建 Anchor 工作区提供者
"use client";
import { createContext, useContext, ReactNode } from "react"
import { Program, AnchorProvider } from "@coral-xyz/anchor"
import { AnchorWallet, useAnchorWallet, useConnection } from "@solana/wallet-adapter-react"
import { HelloWorld, IDL } from "@/idl/hello_world"
import { PublicKey } from "@solana/web3.js"
const WorkspaceContext = createContext({})
interface Workspace {
program?: Program<HelloWorld>
}
export const WorkspaceProvider = ({ children }: { children: ReactNode }) => {
const { connection } = useConnection()
const wallet = useAnchorWallet()
const provider = new AnchorProvider(
connection,
wallet as AnchorWallet,
AnchorProvider.defaultOptions()
)
const program = new Program(
IDL,
new PublicKey("3KUbj4gMH77adZnZhatXutJ695qCGzB6G8cmMU1SYMWW"),
provider
)
const workspace = {
program,
}
return (
<WorkspaceContext.Provider value={workspace}>
{children}
</WorkspaceContext.Provider>
)
}
export const useWorkspace = (): Workspace => {
return useContext(WorkspaceContext) as Workspace
}
2.3 更新布局组件
import { WalletContextProvider } from '@/context/WalletContextProvider'
import { WorkspaceProvider } from '@/context/WorkspaceProvider'
import './globals.css'
export default function RootLayout({
children,
}: {
children: React.ReactNode
}) {
return (
<html lang="en">
<body>
<WalletContextProvider>
<WorkspaceProvider>
{children}
</WorkspaceProvider>
</WalletContextProvider>
</body>
</html>
)
}
2.4 创建主页面组件
'use client'
import { useWallet } from '@solana/wallet-adapter-react'
import { WalletMultiButton } from '@solana/wallet-adapter-react-ui'
import { FC, useState } from 'react'
import { useWorkspace } from '@/context/WorkspaceProvider'
const Home: FC = () => {
const { publicKey } = useWallet()
const { program } = useWorkspace()
const [loading, setLoading] = useState(false)
const sayHello = async () => {
if (!publicKey || !program) {
alert("Please connect your wallet!")
return
}
setLoading(true)
try {
const tx = await program.methods
.sayHello()
.accounts({})
.rpc()
alert(`Transaction successful! Signature: ${tx}`)
} catch (error) {
console.error(error)
alert(`Error: ${error instanceof Error ? error.message : String(error)}`)
} finally {
setLoading(false)
}
}
return (
<main className="flex min-h-screen flex-col items-center justify-between p-24">
<div className="z-10 max-w-5xl w-full items-center justify-between font-mono text-sm">
<div className="flex flex-col items-center gap-8">
<h1 className="text-4xl font-bold">Solana Hello World (Anchor)</h1>
<WalletMultiButton />
{publicKey && (
<button
onClick={sayHello}
disabled={loading}
className="bg-blue-500 hover:bg-blue-700 text-white font-bold py-2 px-4 rounded"
>
{loading ? "Processing..." : "Say Hello"}
</button>
)}
</div>
</div>
</main>
)
}
export default Home
2.5 tsconfig.json 配置
为了正确使用 @ 路径别名,需要配置 tsconfig.json 文件:
{
"compilerOptions": {
"target": "ES2017",
"lib": ["dom", "dom.iterable", "esnext"],
"allowJs": true,
"skipLibCheck": true,
"strict": true,
"noEmit": true,
"esModuleInterop": true,
"module": "esnext",
"moduleResolution": "bundler",
"resolveJsonModule": true,
"isolatedModules": true,
"jsx": "preserve",
"incremental": true,
"plugins": [
{
"name": "next"
}
],
"paths": {
"@/*": ["./*"],
"@/idl/*": ["./app/idl/*"],
"@/context/*": ["./app/context/*"]
}
},
"include": ["next-env.d.ts", "**/*.ts", "**/*.tsx", ".next/types/**/*.ts"],
"exclude": ["node_modules"]
}
这个配置文件增加了 @/idl/* 和 @/context/* 的别名,以便在代码中使用这些路径。
2.6 运行项目
运行:
pnpm dev
点击 Say Hello 按钮通过 phantom wallet 发送交易,交易成功之后,可以在 explorer 上看到交易详情:
https://explorer.solana.com/tx/5dustfzfhSopVKrDiL3CoXAg35jimMBs3oFkxDsiBqM1xQ6t4JnsonbdZirzYdR5i5HGsUKmfhKZb3NQunWDbWiw?cluster=devnet
两种方法的主要区别
- 不使用 Anchor:
- 直接使用
@solana/web3.js创建交易和指令 - 手动构建交易结构
- 更底层的控制
- 使用 Anchor:
- 使用 Anchor IDL 类型定义
- 更高级的抽象和类型安全
- 更简洁的程序调用方式
- 更好的开发体验
选择哪种方法取决于你的需求:
- 如果需要更多底层控制或项目较小,可以选择不使用 Anchor
- 如果需要更好的开发体验和类型安全,建议使用 Anchor
下一步
至此,我们已经完成了一个最基础的 Solana 程序的开发和部署。虽然这个程序只是简单地打印 "Hello, world!",但它包含了 Solana 程序开发的基本要素:
- 程序入口点的定义
- 基本的参数结构
- 构建和部署流程
在接下来的内容中,我们将学习:
- 如何使用 Anchor 框架开发程序
- 如何处理账户数据
- 如何实现更复杂的指令逻辑
- 如何进行程序测试
- 如何确保程序安全性
敬请期待吧!
Refs
关于 cargo-build-sbf 解释 https://github.com/solana-labs/solana/issues/34987#issuecomment-1913538260
https://solana.stackexchange.com/questions/16443/error-function-stack-offset-of-7256-exceeded-max-offset-of-4096-by-3160-bytes
安装 solana cli tool suites(注意不要安装 edge 版本,会发现部署不成功问题) https://solana.com/docs/intro/installation
https://github.com/solana-labs/solana/issues/34987#issuecomment-1914665002 https://github.com/anza-xyz/agave/issues/1572
在 solana 编写一个 helloworld https://solana.com/developers/guides/getstarted/local-rust-hello-world#create-a-new-rust-library-with-cargo
solana wallet nextjs setup https://solana.com/developers/guides/wallets/add-solana-wallet-adapter-to-nextjs
https://solana.com/developers/cookbook/wallets/connect-wallet-react https://www.anza.xyz/blog/solana-web3-js-2-release
https://solana.stackexchange.com/questions/1723/anchor-useanchorwallet-vs-solanas-usewallet
anchor client side development https://solana.com/developers/courses/onchain-development/intro-to-anchor-frontend
Client invoke Program
- Introduction
- Solana Program Review
- A client-side script to invoke a program
- A NextJS frontend application to invoke the program
- React Query Basics
- Refs
Introduction
In this article, we will learn how to interact with Solana programs from both client-side scripts and frontend applications like React. We'll explore different approaches to sending transactions and invoking program instructions, with a focus on building user-friendly interfaces for your decentralized applications.
First, let's start by going over the basic structure of Anchor's TypeScript library. The primary object you'll be using is the Program object. A Program instance represents a specific Solana program and provides a custom API for reading and writing to the program.
To create an instance of Program, you'll need the following:
IDL- file representing the structure of a programConnection- the cluster connectionWallet- default keypair used to pay for and sign transactionsProvider- encapsulates theConnectionto a Solana cluster and aWallet
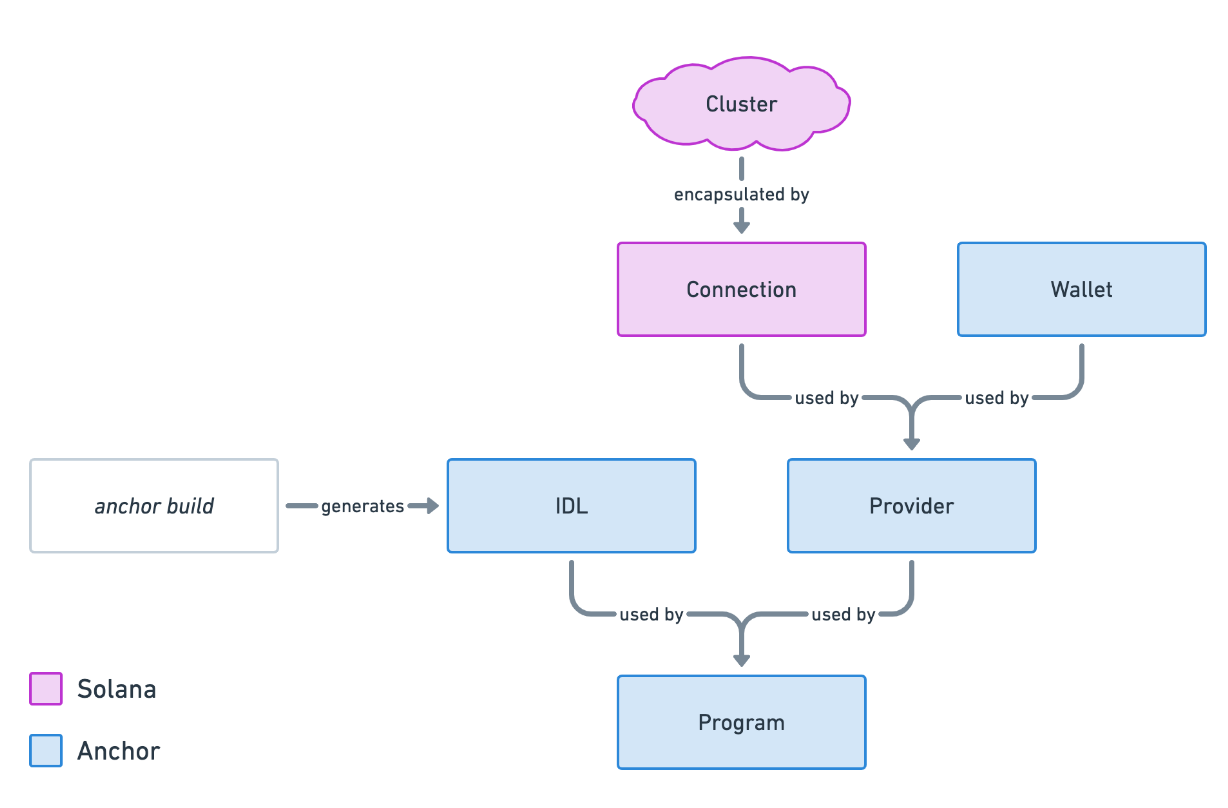
When building applications on Solana, there are several approaches to invoke a program and interact with the blockchain:
- Use the
@solana/web3.jslibrary to directly create transactions and instructions - Use the
anchor-clientlibrary to invoke the program - In frontend applications like React, use the
useAnchorWallethook from@solana/wallet-adapter-reactto connect to a wallet and invoke the program
Now, let's see how to invoke a program in frontend applications like React.
Solana Program Review
Before we start, let's review the program code.
#![allow(unused)] fn main() { #[program] pub mod solanapda { use anchor_lang::solana_program::entrypoint::ProgramResult; use super::*; pub fn create(ctx: Context<Create>, name: String) -> ProgramResult { let bank = &mut ctx.accounts.bank; // set the name of the bank to the one passed in bank.name = name; // set the balance to 0 bank.balance = 0; // set the owner to the user, who pay for the creation of the bank account bank.owner = ctx.accounts.user.key(); msg!("Bank ({:?}) account ({:?}) created", bank.name, bank.key()); Ok(()) } #[derive(Accounts)] #[instruction(name: String)] pub struct Create<'info> { // #[account(init, payer = user, space = 8 + 32, seeds = [b"bank".as_ref()], bump)] #[account( init, payer = user, space = 8 + Bank::INIT_SPACE, seeds = [ b"bankaccount".as_ref(), user.key().as_ref(), name.as_bytes() ], bump) ] pub bank: Account<'info, Bank>, // the user need to be mutable, so that he can pay for the creation, its wallet balance will be reduced #[account(mut)] // NOTE: user should be mutable // otherwise you will get an error // error: the payer specified for an init constraint must be mutable. // // NOTE: When annotating an account with #[account()], which is not mutable, you will get an error // #[account()] pub user: Signer<'info>, pub system_program: Program<'info, System>, } #[account] #[derive(InitSpace)] pub struct Bank { #[max_len(64)] pub name: String, pub owner: Pubkey, pub balance: u64, } }
The create instruction is the instruction to create a bank account for specific user.
The Create struct is the context of the instruction.
The Create struct defines the accounts required for the create instruction:
-
bank: The bank account to be createdinit- Initialize a new account owned by the programpayer = user- The user pays for account creationspace = 8 + Bank::INIT_SPACE- Allocate space for account data (8 bytes for discriminator + space for Bank struct)seeds = [...]- PDA seeds to derive the account address:- "bankaccount" prefix
- User's public key
- Bank name
bump- Store bump seed for PDA
-
user: The user creating the bank account- Must be mutable (
mut) since they pay for account creation - Must sign the transaction (
Signer)
- Must be mutable (
-
system_program: Required for creating new accounts
The Bank struct is the account of the bank.
The Bank struct represents the data stored in a bank account. It contains:
-
name: A String field with maximum length of 64 bytes- Stores the name of the bank account
- Uses
#[max_len(64)]attribute to limit the string length
-
owner: A Pubkey field- Stores the public key of the account owner
- Set to the user's public key when account is created
-
balance: A u64 field- Tracks the account balance in lamports
- Initialized to 0 when account is created
- Updated by deposit and withdraw instructions
The struct uses #[account] attribute to mark it as an account that can store data on-chain.
The #[derive(InitSpace)] attribute automatically calculates the required space for the account based on its fields.
Ok, now let's start to build a client-side script to invoke the bank program to create a bank account.
A client-side script to invoke a program
1. Create a client-side script
Below is a client-side script to invoke the bank program to create a bank account.
import { Connection, Keypair, PublicKey, SystemProgram } from "@solana/web3.js";
import { Program, AnchorProvider, Wallet, utils } from "@coral-xyz/anchor";
import { homedir } from "os";
import { readFileSync } from "fs";
import path from "path";
import { Command } from "commander";
import type { Solanapda } from "./idl/solanapda"; // 你的类型定义
import idl from "./idl/solanapda.json";
import { getKeypairFromFile } from "@solana-developers/helpers";
// configure command line options
const program = new Command();
program
.name("create-bank")
.description("Create a new bank account")
.option("-n, --name <string>", "bank name", "CLI Bank")
.option(
"-N, --network <string>",
"solana network (devnet or localhost)",
"localhost"
)
.parse(process.argv);
const options = program.opts();
// helper function to load keypair from file
const loadKeypairFromFile = (filePath: string): Keypair => {
const expanded = filePath.replace("~", homedir());
const secretKey = new Uint8Array(JSON.parse(readFileSync(expanded, "utf-8")));
return Keypair.fromSecretKey(secretKey);
};
async function initializeConnection() {
const endpoint =
options.network === "devnet"
? "https://api.devnet.solana.com"
: "http://localhost:8899";
const connection = new Connection(endpoint, "confirmed");
// NOTE: We can use custom function to load keypair from file or use build in
// function to load keypair from file
//
// const wallet = loadKeypairFromFile("~/.config/solana/id.json");
// use build int function to load keypair from file
// Source: https://github.com/solana-developers/helpers/blob/main/src/lib/keypair.ts
// Source: https://github.com/solana-developers/helpers/blob/af00163b866c44cc93a1fa64e2f8189366d39dce/src/lib/keypair.ts#L11
const wallet = await getKeypairFromFile();
console.log("Using wallet:", wallet.publicKey.toString());
console.log("Network:", options.network);
const provider = new AnchorProvider(
connection,
new Wallet(wallet),
AnchorProvider.defaultOptions()
);
return { provider, wallet };
}
async function createBank(
program: Program<Solanapda>,
wallet: Keypair,
name: string
) {
// Generate PDA
// The seeds of PDA is a combination of the program id, the user's public key, and the bank name
const [bankPDA] = PublicKey.findProgramAddressSync(
[
utils.bytes.utf8.encode("bankaccount"),
wallet.publicKey.toBytes(),
utils.bytes.utf8.encode(name), // Add bank name as seed
],
program.programId
);
console.log("Bank PDA:", bankPDA.toString());
// Send create transaction
console.log(`Creating bank with name: ${name} ...`);
const tx = await program.methods
.create(name)
.accounts({
user: wallet.publicKey,
})
.rpc();
// Wait for transaction confirmation
const latestBlockhash =
await program.provider.connection.getLatestBlockhash();
await program.provider.connection.confirmTransaction({
signature: tx,
blockhash: latestBlockhash.blockhash,
lastValidBlockHeight: latestBlockhash.lastValidBlockHeight,
});
console.log("Success! Transaction signature:", tx);
// You can also add a short delay to ensure the account data is available
// await new Promise((resolve) => setTimeout(resolve, 2000));
return bankPDA;
}
async function fetchBankInfo(program: Program<Solanapda>, bankPDA: PublicKey) {
const bankAccount = await program.account.bank.fetch(bankPDA);
console.log("Bank account data:", {
name: bankAccount.name,
balance: bankAccount.balance.toString(),
owner: bankAccount.owner.toString(),
});
return bankAccount;
}
async function main() {
try {
// 1. Initialize connection
const { provider, wallet } = await initializeConnection();
const program = new Program(idl as Solanapda, provider);
// 2. Create bank account
const bankPDA = await createBank(program, wallet, options.name);
// 3. Fetch bank account info
await fetchBankInfo(program, bankPDA);
} catch (error) {
console.error("Error:", error);
process.exit(1);
}
}
main();
2. Explain the code
Let's explain the code step by step based on the solana program review.
Let's break down the key components of this client code:
-
createBankfunction:- Takes a program instance, wallet keypair, and bank name as parameters
- Generates a PDA (Program Derived Address) using 3 seeds:
- "bankaccount" string
- User's public key
- Bank name
- Matches the seeds used in the program's
Createstruct:#![allow(unused)] fn main() { #[account( init, payer = user, space = 8 + Bank::INIT_SPACE, seeds = [ b"bankaccount".as_ref(), user.key().as_ref(), name.as_bytes() ], bump) ] } - Calls the program's
createinstruction with the bank name - Waits for transaction confirmation
- Returns the bank PDA for later use
-
fetchBankInfofunction:- Fetches the bank account data using the PDA
- Displays the bank's:
- Name (String)
- Balance (u64)
- Owner (Pubkey)
- These fields match the program's
Bankstruct:#![allow(unused)] fn main() { pub struct Bank { pub name: String, pub owner: Pubkey, pub balance: u64, } }
-
mainfunction flow:- Initializes connection and gets wallet
- Creates program instance with IDL
- Creates new bank account with specified name
- Fetches and displays the bank account info
The client code directly interacts with the on-chain program's instructions and account structures defined in Rust. The PDA generation and account structure in TypeScript must exactly match what's defined in the program for successful interaction.
3. Setup a nodejs environment to run the script
We can setup a nodejs environment to run the script.
#!/bin/bash
# Colors for output
GREEN='\033[0;32m'
RED='\033[0;31m'
NC='\033[0m' # No Color
echo -e "${GREEN}Setting up Node.js environment...${NC}"
# Check if Node.js is installed
if ! command -v node &> /dev/null; then
echo -e "${RED}Node.js is not installed. Please install Node.js first.${NC}"
exit 1
fi
# Create project directory if it doesn't exist
mkdir -p solana-bank-client
cd solana-bank-client
# Initialize npm project if package.json doesn't exist
if [ ! -f package.json ]; then
echo -e "${GREEN}Initializing npm project...${NC}"
pnpm init -y
fi
# Install dependencies
echo -e "${GREEN}Installing dependencies...${NC}"
pnpm install --save \
@solana/web3.js \
@coral-xyz/anchor \
@solana-developers/helpers \
typescript \
ts-node \
commander \
@types/node
# Create tsconfig.json if it doesn't exist
if [ ! -f tsconfig.json ]; then
echo -e "${GREEN}Creating TypeScript configuration...${NC}"
cat > tsconfig.json << EOF
{
"compilerOptions": {
"target": "es2020",
"module": "commonjs",
"strict": true,
"esModuleInterop": true,
"skipLibCheck": true,
"forceConsistentCasingInFileNames": true,
"resolveJsonModule": true
}
}
EOF
fi
# Check if create-bank.ts exists in the current directory
if [ ! -f create-bank.ts ]; then
echo -e "${RED}Please create create-bank.ts file with your code first${NC}"
exit 1
fi
# Run the code
echo -e "${GREEN}Running the code...${NC}"
npx ts-node create-bank.ts
3. Prepare the IDL and type files
The script needs the IDL and type files which are generated when building the Anchor program. Make sure you've run anchor build in your program directory first. This will generate:
- The IDL file at
target/idl/your_program.json - TypeScript types at
target/types/your_program.ts
You'll need to copy or reference these files in your client directory to interact with the program.
In our case, the IDL file is target/idl/solanapda.json and the type file is target/types/solanapda.ts.
4. Run the script
Now, save the code to a file, for example, create-bank.ts, and run the script.
npx ts-node create-banks.ts --name "Rich Bank"
(node:82552) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead.
(Use `node --trace-deprecation ...` to show where the warning was created)
Using wallet: FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH
Network: localhost
Bank PDA: EYxqs3ZHCG5j8DYaZvYKtwDSxbkCn2jgLYvK7cpksimq
Creating bank with name: Rich Bank ...
Success! Transaction signature: 5qcf5Puu6Vw3kVNDsqKSqVjanYwBqxcD6qVk6BzrnzVgvwecdjGPYvJeLrLPhkaCzUoMTdBii47XXtL8edpDu8i7
Bank account data: {
name: 'Rich Bank',
balance: '0',
owner: 'FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH'
}
Great! We can see that the bank account is created successfully.
A NextJS frontend application to invoke the program
Although we can setup a nextjs project and use the @solana/wallet-adapter-react to invoke the program, but it's not the best way to do it.
We can leverage npx create-solana-dapp to create a nextjs project and use the @solana/wallet-adapter-react to invoke the program. This will skip the tedious steps of scaffolding the project(like creating the layout, components, especially wallet adapter, etc.) and focus on the core logic.
npx create-solana-dapp@latest solana-dapp-example -t next-tailwind-counter --pnpm
# Available templates:
# next-tailwind-counter
# next-tailwind-basic
# next-tailwind
#
# NOTE: There's no --typescript/--eslint/--tailwind option in the latest version of create-solana-dapp
# npx create-solana-dapp@latest --typescript --eslint --tailwind --pnpm
# add dependencies
pnpm install \
@coral-xyz/anchor \
@solana/web3.js \
@solana/wallet-adapter-react \
@solana/wallet-adapter-react-ui \
@solana/wallet-adapter-base \
@solana/wallet-adapter-wallets
After creating the project, we need to replace all solanadappexample with bank in the project.
We can add a new tab called Bank in the navigation bar.
If you are lazy like me, you can use a script to replace all solanadappexample with bank in the project.
function copy() {
# Use rsync to properly sync directories
rsync -a --delete ./src/components/solanadappexample/ ./src/components/bank
rsync -a --delete ./src/app/solanadappexample/ ./src/app/bank
cp -f ./anchor/src/solanadappexample-exports.ts ./anchor/src/bank-exports.ts
}
function copy_using_cp() {
# NOTE: This is not a good idea to use cp to copy directories.
# If you run it multiple times, it will create new bank folder in existing bank folder.
cp -rf ./src/components/solanadappexample ./src/components/bank
cp -rf ./src/app/solanadappexample ./src/app/bank
cp ./anchor/src/solanadappexample-exports.ts ./anchor/src/bank-exports.ts
}
# replace all solanadappexample with bank in components
function replace_in_components() {
cd ./src/components/bank
rg Solanadappexample --files-with-matches | xargs sed -i '' "s/Solanadappexample/Bank/g"
rg solanadappexample --files-with-matches | xargs sed -i '' "s/solanadappexample/bank/g"
rg SOLANADAPPEXAMPLE --files-with-matches | xargs sed -i '' "s/SOLANADAPPEXAMPLE/BANK/g"
cd -
}
# replace
function replace_in_exports() {
bank_export_file="./anchor/src/bank-exports.ts"
# cp ./anchor/src/solanadappexample-exports.ts $bank_export_file
rg Solanadappexample --files-with-matches $bank_export_file | xargs sed -i '' "s/Solanadappexample/Bank/g"
rg solanadappexample --files-with-matches $bank_export_file | xargs sed -i '' "s/solanadappexample/bank/g"
rg SOLANADAPPEXAMPLE --files-with-matches $bank_export_file | xargs sed -i '' "s/SOLANADAPPEXAMPLE/BANK/g"
}
# replace all solanadappexample with bank in components
function replace_in_pages() {
cd ./src/app/bank
rg Solanadappexample --files-with-matches | xargs sed -i '' "s/Solanadappexample/Bank/g"
rg solanadappexample --files-with-matches | xargs sed -i '' "s/solanadappexample/bank/g"
rg SOLANADAPPEXAMPLE --files-with-matches | xargs sed -i '' "s/SOLANADAPPEXAMPLE/BANK/g"
cd -
}
# rename all files in solanadappexample to bank in the IDL file
function rename_files_in_components() {
# rename all files names in src/components/solanadappexample begins with solanadappexample to bank
cd ./src/components/bank
# rename all files names in src/components/solanadappexample begins with solanadappexample to bank
# not file contents!!!
# NOTE: This does not work in fish shell. You have to use bash.
for file in solanadappexample*; do mv "$file" "${file/solanadappexample/bank}"; done
# For fish shell
# for file in solanadappexample*; mv "$file" "${file/solanadappexample/bank}"; end
cd -
}
# add export * from './bank' in the index.ts file
function add_export_in_index_ts() {
# Check if the export line already exists to make it idempotent
if ! grep -q "export \* from './bank-exports'" ./anchor/src/index.ts; then
echo "export * from './bank-exports'" >> ./anchor/src/index.ts
fi
}
copy
replace_in_components
replace_in_exports
replace_in_pages
rename_files_in_components
add_export_in_index_ts
Next, open src/app/layout.tsx and add a /bank link to the links array.
import "./globals.css";
import { ClusterProvider } from "@/components/cluster/cluster-data-access";
import { SolanaProvider } from "@/components/solana/solana-provider";
import { UiLayout } from "@/components/ui/ui-layout";
import { ReactQueryProvider } from "./react-query-provider";
export const metadata = {
title: "solana-dapp-example",
description: "Generated by create-solana-dapp",
};
const links: { label: string; path: string }[] = [
{ label: "Account", path: "/account" },
{ label: "Clusters", path: "/clusters" },
{ label: "Solanadappexample Program", path: "/solanadappexample" },
{ label: "Bank Program", path: "/bank" }, // 🙋🙋🙋🙋🙋, This is the new link
];
export default function RootLayout({
children,
}: {
children: React.ReactNode;
}) {
return (
<html lang="en">
<body>
<ReactQueryProvider>
<ClusterProvider>
<SolanaProvider>
<UiLayout links={links}>{children}</UiLayout>
</SolanaProvider>
</ClusterProvider>
</ReactQueryProvider>
</body>
</html>
);
}
As anchor needs the IDL file and the type file, we can copy the IDL file to target/idl and the type file to target/types. We can obtain them by running anchor build in your program directory first.
In our case, the IDL file is target/idl/solanapda.json and the type file is target/types/solanapda.ts.
We also need to replace the program id in function getBankProgramId with our program id (i.e E5U58NJgCMwtyv3TPaZtoZPmnxUY9vCGrXDMjPpbxm4z).
// Here we export some useful types and functions for interacting with the Anchor program.
import { AnchorProvider, Program } from "@coral-xyz/anchor";
import { Cluster, PublicKey } from "@solana/web3.js";
import BankIDL from "../target/idl/bank.json";
import type { Solanapda as Bank } from "../target/types/bank";
// Re-export the generated IDL and type
export { Bank, BankIDL };
// The programId is imported from the program IDL.
export const BANK_PROGRAM_ID = new PublicKey(BankIDL.address);
// This is a helper function to get the Bank Anchor program.
export function getBankProgram(provider: AnchorProvider, address?: PublicKey) {
return new Program(
{
...BankIDL,
address: address ? address.toBase58() : BankIDL.address,
} as Bank,
provider
);
}
// This is a helper function to get the program ID for the Bank program depending on the cluster.
export function getBankProgramId(cluster: Cluster) {
switch (cluster) {
case "devnet":
case "testnet":
// This is the program ID for the Bank program on devnet and testnet.
return new PublicKey("E5U58NJgCMwtyv3TPaZtoZPmnxUY9vCGrXDMjPpbxm4z");
case "mainnet-beta":
default:
return BANK_PROGRAM_ID;
}
}
Next, let's look at the UI implementation where we'll create components to interact with our Solana program. As we are using @solana/wallet-adapter-react, we can use the WalletMultiButton to connect their wallet.
Luckily, create-solana-dapp has already created the WalletMultiButton for us. We can focus on the logic part.
Let's examine our bank components, which are organized into the following key files:
bank-feature.tsxbank-ui.tsxbank-data-access.tsx
This project structure follows a modular pattern commonly used in create-solana-dapp, with components organized into three main types:
-
*-feature.tsx: The top-level component that serves as the main page or feature. It handles the overall layout and composition of UI components while managing high-level application state. For example,bank-feature.tsxcombines wallet connection state with bank-specific components. -
*-ui.tsx: Contains the presentational components that render the actual UI elements. These components focus purely on display logic and user interactions, receiving data and callbacks as props. For example,bank-ui.tsxhas components likeBankListandBankCreatethat render the bank interface. -
*-data-access.tsx: Manages data fetching, state management, and program interactions. This layer abstracts away the complexity of working with Solana programs and provides clean hooks/interfaces for the UI layer. For example,bank-data-access.tsxwould contain hooks likeuseBankProgramto interact with the on-chain program.
The data-access layer uses React Query to efficiently manage server state and program interactions. Here's how it's structured:
-
Custom hooks that wrap React Query's useQuery and useMutation:
- useQuery for fetching data like account info and balances
- useMutation for program instructions like deposit/withdraw
-
Program account queries:
- Fetch program metadata
- Get list of all bank accounts
- Get individual account details
-
Transaction mutations:
- Create new bank account
- Deposit funds
- Withdraw funds
- Close account
React Query handles important features like:
- Automatic background refreshing
- Cache management
- Loading/error states
- Optimistic updates
- Request deduplication
This pattern keeps program interaction logic isolated from UI components while providing a clean, reactive interface for accessing on-chain data.
This separation of concerns makes the code more maintainable and testable, while keeping the program interaction logic cleanly separated from the UI implementation.
bank-feature.tsx
Let me walk you through the main Bank feature component that brings everything together. This is where all our UI pieces and program interactions come together to create the full banking experience. Take a look at the code in bank-feature.tsx, I'll explain what's happening:
"use client";
import { useWallet } from "@solana/wallet-adapter-react";
import { WalletButton } from "../solana/solana-provider";
import { AppHero, ellipsify } from "../ui/ui-layout";
import { ExplorerLink } from "../cluster/cluster-ui";
import { useBankProgram } from "./bank-data-access";
import { BankCreate, BankList } from "./bank-ui";
export default function BankFeature() {
const { publicKey } = useWallet();
const { programId } = useBankProgram();
return publicKey ? (
<div>
<AppHero
title="Bank"
subtitle={
'Create a new account by clicking the "Create" button. The state of a account is stored on-chain and can be manipulated by calling the program\'s methods (increment, decrement, set, and close).'
}
>
<p className="mb-6">
<ExplorerLink
path={`account/${programId}`}
label={ellipsify(programId.toString())}
/>
</p>
<BankCreate />
</AppHero>
<BankList />
</div>
) : (
<div className="max-w-4xl mx-auto">
<div className="hero py-[64px]">
<div className="hero-content text-center">
<WalletButton />
</div>
</div>
</div>
);
}
The code is straightforward, using the useWallet() hook to check if a wallet is connected. If no wallet is connected, it shows a wallet connect button. Once connected, it displays the main bank interface with the program ID, a create account button, and list of existing bank accounts. The useBankProgram() hook provides access to the program ID and other program-related functionality that we defined earlier.
The component is organized into two main sections:
- The hero section with program info and account creation
- The list of existing bank accounts
This clean separation makes the code easy to understand and maintain. Each piece handles a specific responsibility - wallet connection, program interaction, or UI display.
bank-ui.tsx
Next, let's look at the BankCreate BankCard and BankList components, which are located in bank-ui.tsx.
"use client";
import { Keypair, PublicKey } from "@solana/web3.js";
import { useMemo, useState } from "react";
import { ellipsify } from "../ui/ui-layout";
import { ExplorerLink } from "../cluster/cluster-ui";
import { useBankProgram, useBankProgramAccount } from "./bank-data-access";
import toast from "react-hot-toast";
import { useWallet } from "@solana/wallet-adapter-react";
export function BankCreate() {
const { initialize } = useBankProgram();
const [bankName, setBankName] = useState("");
const { publicKey } = useWallet();
return (
<div className="flex gap-2 items-center justify-center">
<input
type="text"
placeholder="Enter bank name"
className="input input-bordered"
value={bankName}
onChange={(e) => setBankName(e.target.value)}
/>
<button
className="btn btn-xs lg:btn-md btn-primary"
onClick={() => {
if (!publicKey) {
toast.error("Please connect your wallet");
return;
}
if (!bankName.trim()) {
toast.error("Please enter a bank name");
return;
}
initialize
.mutateAsync({ name: bankName.trim(), owner: publicKey })
.then(() => setBankName(""));
}}
disabled={initialize.isPending || !publicKey}
>
Create {initialize.isPending && "..."}
</button>
</div>
);
}
function BankCard({
account,
timestamp,
}: {
account: PublicKey;
timestamp: number;
}) {
const { accountQuery } = useBankProgramAccount({ account });
const balance = useMemo(
() => accountQuery.data?.balance ?? 0,
[accountQuery.data?.balance]
);
const name = useMemo(
() => accountQuery.data?.name ?? "Unnamed Bank",
[accountQuery.data?.name]
);
return accountQuery.isLoading ? (
<span className="loading loading-spinner loading-lg"></span>
) : (
<div className="card card-bordered border-base-300 border-4 text-neutral-content">
<div className="card-body items-center text-center">
<div className="space-y-6">
<h2 className="card-title justify-center text-3xl">{name}</h2>
<p className="text-2xl">Balance: {balance.toString()} lamports</p>
<div className="card-actions justify-around">
<button className="btn btn-xs lg:btn-md btn-outline">
Deposit
</button>
<button
className="btn btn-xs lg:btn-md btn-outline"
onClick={() => {
const value = window.prompt(
"Set balance to:",
balance.toString() ?? "0"
);
if (
!value ||
parseInt(value) === balance ||
isNaN(parseInt(value))
) {
return;
}
}}
>
Set
</button>
<button className="btn btn-xs lg:btn-md btn-outline">
Withdraw
</button>
</div>
<div className="flex justify-between items-center gap-2">
<ExplorerLink
path={`account/${account}`}
label={ellipsify(account.toString())}
/>
<button className="btn btn-xs lg:btn-md btn-outline btn-error">
Close
</button>
</div>
</div>
</div>
</div>
);
}
export function BankList() {
const { accounts, getProgramAccount } = useBankProgram();
if (getProgramAccount.isLoading) {
return <span className="loading loading-spinner loading-lg"></span>;
}
if (!getProgramAccount.data?.value) {
return (
<div className="alert alert-info flex justify-center">
<span>
Program account not found. Make sure you have deployed the program and
are on the correct cluster.
</span>
</div>
);
}
return (
<div className={"space-y-6"}>
{accounts.isLoading ? (
<span className="loading loading-spinner loading-lg"></span>
) : accounts.data?.length ? (
<div className="grid md:grid-cols-2 gap-4">
{accounts.data
?.sort((a, b) => b.timestamp - a.timestamp)
.map((account) => (
<BankCard
key={account.publicKey.toString()}
account={account.publicKey}
timestamp={account.timestamp}
/>
))}
</div>
) : (
<div className="text-center">
<h2 className={"text-2xl"}>No accounts</h2>
No accounts found. Create one above to get started.
</div>
)}
</div>
);
}
The code above shows three React components that interact with a Solana program using Anchor:
BankCreate - A form component that allows users to create new bank accounts by invoking the program's create instruction. It handles user input and transaction submission.
BankCard - A component that displays details for a single bank account, showing information like the public key and timestamp. It receives account data as props.
BankList - The main component that fetches and displays all bank accounts. It:
- Uses the
useBankProgramhook to access program accounts - Shows loading states while data is being fetched
- Displays an info message if the program isn't found
- Renders a grid of
BankCardcomponents for each account - Shows a message when no accounts exist
- Sorts accounts by timestamp
Together these components provide a full UI for interacting with the Solana program - creating new accounts and viewing existing ones.
bank-data-access.tsx
Finally, let's look at the data access layer, which is located in bank-data-access.tsx.
"use client";
import { getBankProgram, getBankProgramId } from "@project/anchor";
import { useConnection } from "@solana/wallet-adapter-react";
import { Cluster, Keypair, PublicKey } from "@solana/web3.js";
import { useMutation, useQuery } from "@tanstack/react-query";
import { useMemo } from "react";
import toast from "react-hot-toast";
import { useCluster } from "../cluster/cluster-data-access";
import { useAnchorProvider } from "../solana/solana-provider";
import { useTransactionToast } from "../ui/ui-layout";
export function useBankProgram() {
const { connection } = useConnection();
const { cluster } = useCluster();
const transactionToast = useTransactionToast();
const provider = useAnchorProvider();
const programId = useMemo(
() => getBankProgramId(cluster.network as Cluster),
[cluster]
);
const program = useMemo(
() => getBankProgram(provider, programId),
[provider, programId]
);
const accounts = useQuery({
queryKey: ["bank", "all", { cluster }],
// queryFn: () => program.account.bank.all(),
queryFn: async () => {
const accounts = await program.account.bank.all();
const accountsWithTimestamp = await Promise.all(
accounts.map(async (account) => {
const signatures = await connection.getSignaturesForAddress(
account.publicKey,
{ limit: 1 }
);
return {
...account,
timestamp: signatures[0]?.blockTime || 0,
};
})
);
return accountsWithTimestamp.sort((a, b) => b.timestamp - a.timestamp);
},
});
const getProgramAccount = useQuery({
queryKey: ["get-program-account", { cluster }],
queryFn: () => connection.getParsedAccountInfo(programId),
});
const initialize = useMutation({
mutationKey: ["bank", "initialize", { cluster }],
// mutationFn: ({ keypair, name }: { keypair: Keypair; name: string }) =>
mutationFn: async ({ name, owner }: { name: string; owner: PublicKey }) =>
program.methods
.create(name)
.accounts({
user: owner,
})
// .signers([keypair])
.rpc(),
onSuccess: (signature) => {
transactionToast(signature);
return accounts.refetch();
},
onError: () => toast.error("Failed to initialize account"),
});
return {
program,
programId,
accounts,
getProgramAccount,
initialize,
};
}
export function useBankProgramAccount({ account }: { account: PublicKey }) {
const { cluster } = useCluster();
const transactionToast = useTransactionToast();
const { program, accounts } = useBankProgram();
const accountQuery = useQuery({
queryKey: ["bank", "fetch", { cluster, account }],
queryFn: () => program.account.bank.fetch(account),
});
return {
accountQuery,
};
}
Let me explain the bank-data-access.tsx file in detail:
- Main Hook: useBankProgram
export function useBankProgram() {
// Get necessary context and tools
const { connection } = useConnection(); // Solana connection
const { cluster } = useCluster(); // Current network cluster
const provider = useAnchorProvider(); // Anchor provider
const transactionToast = useTransactionToast(); // Transaction notification tool
// Get program ID and program instance
const programId = useMemo(() => getBankProgramId(cluster.network), [cluster]);
const program = useMemo(() => getBankProgram(provider, programId), [provider, programId]);
- Account Query Functionality
// Query all bank accounts
const accounts = useQuery({
queryKey: ["bank", "all", { cluster }],
queryFn: async () => {
// 1. Get all accounts
const accounts = await program.account.bank.all();
// 2. Add timestamp for each account
const accountsWithTimestamp = await Promise.all(
accounts.map(async (account) => {
const signatures = await connection.getSignaturesForAddress(
account.publicKey,
{ limit: 1 }
);
return {
...account,
timestamp: signatures[0]?.blockTime || 0,
};
})
);
// 3. Sort by timestamp
return accountsWithTimestamp.sort((a, b) => b.timestamp - a.timestamp);
},
});
// Query program account info
const getProgramAccount = useQuery({
queryKey: ["get-program-account", { cluster }],
queryFn: () => connection.getParsedAccountInfo(programId),
});
- Account Creation Functionality
// Mutation for initializing new bank account
const initialize = useMutation({
mutationKey: ["bank", "initialize", { cluster }],
mutationFn: async ({ name, owner }) =>
program.methods.create(name).accounts({ user: owner }).rpc(),
onSuccess: (signature) => {
transactionToast(signature); // Show success notification
return accounts.refetch(); // Refresh account list
},
onError: () => toast.error("Failed to initialize account"),
});
- Single Account Query Hook
export function useBankProgramAccount({ account }: { account: PublicKey }) {
// ... context getters omitted ...
// Query single account data
const accountQuery = useQuery({
queryKey: ["bank", "fetch", { cluster, account }],
queryFn: () => program.account.bank.fetch(account),
});
return { accountQuery };
}
Key Features of this file:
-
Data Access Layer Abstraction
- Encapsulates all Solana program interaction logic
- Provides clean interfaces for UI components
-
React Query Integration
- Uses
useQueryfor read operations (querying accounts) - Uses
useMutationfor write operations (creating accounts) - Automatic handling of caching, loading states, and error handling
- Uses
-
Performance Optimizations
- Uses
useMemoto cache program instances - Implements account timestamp and sorting functionality
- Automatic data refetching to keep UI in sync
- Uses
-
Error Handling
- Integrated toast notification system
- Provides feedback for transaction success and failure
-
Modular Design
- Separates program interaction logic from UI logic
- Provides reusable hooks
- Easy to test and maintain
This design pattern ensures:
- UI components can focus on presentation logic
- Program interaction logic is centrally managed
- Data fetching and caching is unified
- Error handling and user feedback is standardized
React Query Basics
Let me explain React Query and how it's used in this code:
React Query is a powerful library for managing server state in React applications. Think of it as a combination of:
- Data fetching
- Caching
- State management
- Error handling
Key Concepts
- useQuery - For fetching/reading data
// Basic example
const { data, isLoading, error } = useQuery({
queryKey: ['todos'], // Unique identifier for this query
queryFn: fetchTodoList, // Function that returns a promise
});
// Real example from our code
const accounts = useQuery({
queryKey: ["bank", "all", { cluster }],
queryFn: async () => {
const accounts = await program.account.bank.all();
// Add timestamps and sort...
return accountsWithTimestamp;
},
});
// You can then use the data like:
if (accounts.isLoading) return <Loading />;
if (accounts.error) return <Error />;
return <div>{accounts.data.map(account => ...)}</div>;
- useMutation - For updating/writing data
// Basic example
const mutation = useMutation({
mutationFn: (newTodo) => axios.post("/todos", newTodo),
onSuccess: () => {
// Do something after successful mutation
},
});
// Real example from our code
const initialize = useMutation({
mutationFn: async ({ name, owner }) =>
program.methods.create(name).accounts({ user: owner }).rpc(),
onSuccess: (signature) => {
transactionToast(signature); // Show success message
return accounts.refetch(); // Refresh the account list
},
});
// You can then use it like:
<button onClick={() => initialize.mutate({ name: "New Bank", owner })}>
{initialize.isPending ? "Creating..." : "Create Bank"}
</button>;
Key Features
- Automatic Caching
// Data is cached by queryKey
const { data: account } = useQuery({
queryKey: ["bank", "fetch", { cluster, account }],
queryFn: () => program.account.bank.fetch(account),
});
// Second component using same query will use cached data
- Automatic Background Refreshing
const accounts = useQuery({
queryKey: ["bank", "all"],
queryFn: fetchAccounts,
// Optional configuration
refetchInterval: 5000, // Refetch every 5 seconds
staleTime: 30000, // Consider data stale after 30 seconds
});
- Loading & Error States
const { data, isLoading, error } = useQuery({...});
if (isLoading) return <span>Loading...</span>;
if (error) return <span>Error: {error.message}</span>;
return <div>{data.map(item => ...)}</div>;
- Automatic Retries
const query = useQuery({
queryKey: ["data"],
queryFn: fetchData,
retry: 3, // Retry failed requests 3 times
retryDelay: 1000, // Wait 1 second between retries
});
In Our Bank Application
Here's how React Query helps in our bank application:
- Account Listing
// Fetches and caches all bank accounts
const accounts = useQuery({
queryKey: ["bank", "all", { cluster }],
queryFn: async () => {
const accounts = await program.account.bank.all();
// Add timestamps...
return accountsWithTimestamp;
},
});
// Usage in UI
if (accounts.isLoading) return <Loading />;
return (
<div>
{accounts.data?.map((account) => (
<BankCard key={account.publicKey} account={account} />
))}
</div>
);
- Creating New Accounts
// Mutation for creating new accounts
const initialize = useMutation({
mutationFn: async ({ name, owner }) => program.methods.create(name)...,
onSuccess: () => {
accounts.refetch(); // Automatically refresh the account list
},
});
// Usage in UI
<button
onClick={() => initialize.mutate({ name, owner })}
disabled={initialize.isPending}
>
Create Account
</button>
The benefits in our application:
- Automatic caching of account data
- Loading states handled automatically
- Error handling built-in
- Automatic background refreshing
- Optimistic updates
- Consistent data across components
This makes our code much cleaner and more maintainable compared to managing all this state manually with useState and useEffect.
Refs
https://solana.com/docs/programs/anchor/client-typescript
https://lorisleiva.com/create-a-solana-dapp-from-scratch/integrating-with-solana-wallets
https://solana.com/developers/courses/onchain-development/intro-to-anchor-frontend
Deploy Solana Dapp to vercel
Introduction
In this tutorial, we'll walk through the process of deploying a Solana dapp to Vercel. We'll cover everything from setting up your project to deploying your application and configuring the build process.
Project structure
Before we can deploy our Solana dapp to Vercel, we need to understand the project structure and build process.
Let's examine the project root directory to get an overview of our application's structure.
(base) dylankyc@smoltown ~/Code/solana/projects/bank (master)> l
drwxrwxr-x - dylankyc 5 Jan 15:49 anchor
.rw-r--r-- 124 dylankyc 1 Jan 04:41 Makefile
.rw-r--r-- 201 dylankyc 1 Jan 04:52 next-env.d.ts
.rw-r--r-- 92 dylankyc 6 Dec 2024 next.config.mjs
drwxr-xr-x - dylankyc 5 Jan 16:04 node_modules
.rw-r--r-- 1.5k dylankyc 1 Jan 05:06 package.json
.rw-r--r-- 358k dylankyc 1 Jan 05:06 pnpm-lock.yaml
.rw-r--r-- 135 dylankyc 6 Dec 2024 postcss.config.mjs
drwxrwxr-x - dylankyc 31 Dec 2024 public
.rw-r--r-- 2.0k dylankyc 1 Jan 12:16 README.md
drwxrwxr-x - dylankyc 31 Dec 2024 src
.rw-r--r-- 311 dylankyc 6 Dec 2024 tailwind.config.ts
.rw-r--r-- 728 dylankyc 6 Dec 2024 tsconfig.json
Setup
First, we need to install the Vercel CLI:
npm install -g vercel
Then, we can deploy the project to Vercel:
vercel
The output will look something like this:
Vercel CLI 39.1.3
? Set up and deploy “~/Code/solana/projects/bank”? yes
? Which scope should contain your project? dylankyc's projects
? Link to existing project? no
? What’s your project’s name? bank
? In which directory is your code located? ./
Local settings detected in vercel.json:
No framework detected. Default Project Settings:
- Build Command: `npm run vercel-build` or `npm run build`
- Development Command: None
- Install Command: `yarn install`, `pnpm install`, `npm install`, or `bun install`
- Output Directory: `public` if it exists, or `.`
? Want to modify these settings? no
🔗 Linked to dylankycs-projects/swap (created .vercel and added it to .gitignore)
🔍 Inspect: https://vercel.com/dylankycs-projects/bank/5TMVYeZkKmvmt9FeTZE7B6KT7C63 [4s]
✅ Production: https://bank-382d3cupz-dylankycs-projects.vercel.app [4s]
📝 Deployed to production. Run `vercel --prod` to overwrite later (https://vercel.link/2F).
💡 To change the domain or build command, go to https://vercel.com/dylankycs-projects/bank/settings
Build
Build and deploy the project using vercel build and vercel deploy. This will compile your Next.js application and prepare it for deployment:
(base) dylankyc@smoltown ~/Code/solana/projects/bank (master)> vercel build && vercel deploy
Vercel CLI 39.1.3
Detected `pnpm-lock.yaml` version 9 generated by pnpm@9.x
WARNING: You should not upload the `.next` directory.
Installing dependencies...
Lockfile is up to date, resolution step is skipped
Already up to date
Done in 1.3s
Detected Next.js version: 14.2.5
Running "pnpm run build"
> template-next-tailwind-counter@0.1.0 build /Users/dylankyc/Code/solana/projects/bank
> next build
▲ Next.js 14.2.5
Creating an optimized production build ...
✓ Compiled successfully
./src/components/ui/ui-layout.tsx
21:13 Warning: Using `<img>` could result in slower LCP and higher bandwidth. Consider using `<Image />` from `next/image` to automatically optimize images. This may incur additional usage or cost from your provider. See: https://nextjs.org/docs/messages/no-img-element @next/next/no-img-element
info - Need to disable some ESLint rules? Learn more here: https://nextjs.org/docs/basic-features/eslint#disabling-rules
✓ Linting and checking validity of types
✓ Collecting page data
Generating static pages (2/9) [= ]bigint: Failed to load bindings, pure JS will be used (try npm run rebuild?)
(node:74320) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead.
(Use `node --trace-deprecation ...` to show where the warning was created)
bigint: Failed to load bindings, pure JS will be used (try npm run rebuild?)
(node:74319) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead.
(Use `node --trace-deprecation ...` to show where the warning was created)
bigint: Failed to load bindings, pure JS will be used (try npm run rebuild?)
(node:74326) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead.
(Use `node --trace-deprecation ...` to show where the warning was created)
bigint: Failed to load bindings, pure JS will be used (try npm run rebuild?)
(node:74318) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead.
(Use `node --trace-deprecation ...` to show where the warning was created)
Generating static pages (2/9) [== ]bigint: Failed to load bindings, pure JS will be used (try npm run rebuild?)
(node:74321) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead.
(Use `node --trace-deprecation ...` to show where the warning was created)
✓ Generating static pages (9/9)
✓ Collecting build traces
✓ Finalizing page optimization
Route (app) Size First Load JS
┌ ○ / 610 B 254 kB
├ ○ /_not-found 876 B 88.1 kB
├ ○ /account 1.33 kB 234 kB
├ ƒ /account/[address] 553 B 254 kB
├ ○ /api/hello 0 B 0 B
├ ○ /bank 4.3 kB 258 kB
└ ○ /clusters 444 B 254 kB
+ First Load JS shared by all 87.2 kB
├ chunks/601-23baffd8957944ab.js 31.5 kB
├ chunks/9ae566a6-41100044c803629e.js 53.7 kB
└ other shared chunks (total) 2.03 kB
○ (Static) prerendered as static content
ƒ (Dynamic) server-rendered on demand
Traced Next.js server files in: 207.115ms
Created all serverless functions in: 80.291ms
Collected static files (public/, static/, .next/static): 3.828ms
✅ Build Completed in .vercel/output [26s]
Deploy
Now, let's deploy it using the vercel deploy command. This will create a preview deployment that we can test before pushing to production.
Vercel CLI 39.1.3
🔍 Inspect: https://vercel.com/dylankycs-projects/bank/9zB7J9gBtVcWGdeJhkF1xueKLrkg [4s]
✅ Preview: https://bank-4gds13j1s-dylankycs-projects.vercel.app [4s]
📝 To deploy to production (bank-solana.vercel.app), run `vercel --prod`
Deploy to production
Once we've verified the preview deployment works as expected, we can deploy to production using vercel --prod. This will update our main production URL with the latest changes:
(base) dylankyc@smoltown ~/Code/solana/projects/bank (master)> vercel --prod
Vercel CLI 39.1.3
🔍 Inspect: https://vercel.com/dylankycs-projects/bank/J8UCMJ9U87SbvidTemwg5YYr9Bq8 [2s]
✅ Production: https://bank-9qk44c3o2-dylankycs-projects.vercel.app [2s]
Access Your dApp
You can now access your Solana dapp at the URL provided in the output. For example, if the output was:
https://bank-solana.vercel.app
You can access your dapp at https://bank-solana.vercel.app.
Create solana token
- Create token(Token Mint)
- Check the supply
- Decode Account - MintAccount
- Decode Account - Token Account
- Mint token
- Transfer
- Transfer if token account is not exist
- Create token metadata
- spl-token cli source code
- Refs
Create token(Token Mint)
Use spl-token create-token to create a new token. See https://solana.com/docs/core/tokens
Creating token 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY under program TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA
Address: 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY
Decimals: 9
Signature: 3oGeH3iY45PwcBet5A6x2oGUkpN3EK3cGXKsrTg9ui587ucH2BX6uLQhG1z4nCHUn5RiMKGc4maG7VEA2phPNStL
Remember the Address: 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY, which is the address of the new token.
Below is the help message of spl-token create-token.
spl-token create-token --help
spl-token-create-token
Create a new token
USAGE:
spl-token create-token [FLAGS] [OPTIONS] [TOKEN_KEYPAIR]
FLAGS:
--enable-close Enable the mint authority to close this mint
--enable-freeze Enable the mint authority to freeze token accounts for this mint
--enable-group Enables group configurations in the mint. The mint authority must initialize the
group.
--enable-member Enables group member configurations in the mint. The mint authority must
initialize the member.
--enable-metadata Enables metadata in the mint. The mint authority must initialize the metadata.
--enable-non-transferable Permanently force tokens to be non-transferable. They may still be burned.
--enable-permanent-delegate Enable the mint authority to be permanent delegate for this mint
-h, --help Prints help information
-V, --version Prints version information
-v, --verbose Show additional information
OPTIONS:
--with-compute-unit-limit <COMPUTE-UNIT-LIMIT> Set compute unit limit for transaction, in compute units.
--with-compute-unit-price <COMPUTE-UNIT-PRICE>
Set compute unit price for transaction, in increments of 0.000001 lamports per compute unit.
-C, --config <PATH> Configuration file to use
--decimals <DECIMALS>
Number of base 10 digits to the right of the decimal place [default: 9]
--default-account-state <default_account_state>
Specify that accounts have a default state. Note: specifying "initialized" adds an extension, which gives
the option of specifying default frozen accounts in the future. This behavior
Create token with custom keypair
First, let's create a custom keypair for the token.
solana-keygen new -o mint-token-keypair.json
Output:
Generating a new keypair
For added security, enter a BIP39 passphrase
NOTE! This passphrase improves security of the recovery seed phrase NOT the
keypair file itself, which is stored as insecure plain text
BIP39 Passphrase (empty for none):
Wrote new keypair to mint-token-keypair.json
===========================================================================
pubkey: 7QtePN3WrDHK3q4bvwb3Qf6JhCSWbh9orRz397TFTV3z
===========================================================================
Save this seed phrase and your BIP39 passphrase to recover your new keypair:
key pool shallow divide limit derive explain boring brief merge include fox
===========================================================================
The content of the keypair is:
> cat mint-token-keypair.json
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
[92,210,46,10,118,80,241,238,26,161,95,110,122,34,166,248,130,235,232,105,62,135,225,239,163,245,199,37,76,92,227,133,95,68,223,248,3,243,16,22,78,44,214,186,120,128,176,204,180,172,17,84,137,168,2
19,33,214,163,251,37,71,236,79,77]
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Next, let's create the token with the custom keypair.
> spl-token create-token mint-token-keypair.json
Creating token 7QtePN3WrDHK3q4bvwb3Qf6JhCSWbh9orRz397TFTV3z under program TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA
Address: 7QtePN3WrDHK3q4bvwb3Qf6JhCSWbh9orRz397TFTV3z
Decimals: 9
Signature: 45sfrobQ8koMYTdABqeZTLfdU6WS3Qc4Kpi8dkP1oNrYr8BfwvUs6ZHa5DMxZ6eB27bBgSN3CnTc2GTjJZgZ93Gt
Notice, the address of the token is 7QtePN3WrDHK3q4bvwb3Qf6JhCSWbh9orRz397TFTV3z, which is the address of the custom keypair.
Check the transaction on the explorer:
https://explorer.solana.com/tx/45sfrobQ8koMYTdABqeZTLfdU6WS3Qc4Kpi8dkP1oNrYr8BfwvUs6ZHa5DMxZ6eB27bBgSN3CnTc2GTjJZgZ93Gt?cluster=devnet
From the Program Instruction Logs we can see that Token Program(TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA) is invoked and InitializeMint instruction is called to create the mint token.
[
"Program 11111111111111111111111111111111 invoke [1]",
"Program 11111111111111111111111111111111 success",
"Program TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA invoke [1]",
"Program log: Instruction: InitializeMint",
"Program TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA consumed 2919 of 3069 compute units",
"Program TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA success",
"Program ComputeBudget111111111111111111111111111111 invoke [1]",
"Program ComputeBudget111111111111111111111111111111 success"
]
Check the supply
New tokens initially have no supply. Let's check the supply.
spl-token supply 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY
The output is:
0
Decode Account - MintAccount
Decode Token Account using spl-token display
You can use spl-token display to decode the mint account. It will query the details of an SPL token mint account.
Here is the help message of spl-token display.
spl-token display -h
spl-token-display
Query details of an SPL Token mint, account, or multisig by address
USAGE:
spl-token display [FLAGS] [OPTIONS] <TOKEN_ADDRESS>
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
-v, --verbose Show additional information
OPTIONS:
--with-compute-unit-limit <COMPUTE-UNIT-LIMIT> Set compute unit limit for transaction, in compute units.
--with-compute-unit-price <COMPUTE-UNIT-PRICE>
Set compute unit price for transaction, in increments of 0.000001 lamports per compute unit.
-C, --config <PATH> Configuration file to use
--fee-payer <KEYPAIR>
Specify the fee-payer account. This may be a keypair file, the ASK keyword
or the pubkey of an offline signer, provided an appropriate --signer argument
is also passed. Defaults to the client keypair.
-u, --url <URL_OR_MONIKER>
URL for Solana's JSON RPC or moniker (or their first letter): [mainnet-beta, testnet, devnet, localhost]
Default from the configuration file.
--output <FORMAT>
Return information in specified output format [possible values: json, json-compact]
-p, --program-id <ADDRESS> SPL Token program id
ARGS:
<TOKEN_ADDRESS> The address of the SPL Token mint, account, or multisig to query
Let's decode the mint account 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY.
spl-token display 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY
SPL Token Mint
Address: 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY
Program: TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA
Supply: 0
Decimals: 9
Mint authority: 7HjK9uvhowd7JZyq2fH5LAhCzELTuBq5oWHEBtB9SMwn
Freeze authority: (not set)
From the output, we can see that the mint account is initialized with the following fields:
Address:23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUYProgram:TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DASupply:0Decimals:9Mint authority:7HjK9uvhowd7JZyq2fH5LAhCzELTuBq5oWHEBtB9SMwnFreeze authority:(not set)
Decode Token Account using MintLayout.decode
We can use MintLayout.decode to decode the mint account.
import { Connection, PublicKey } from "@solana/web3.js";
import bs58 from "bs58";
import { AccountLayout, MintLayout, TOKEN_PROGRAM_ID } from "@solana/spl-token";
import yargs from "yargs";
const NETWORK_URLS = {
devnet: "https://api.devnet.solana.com",
mainnet: "https://api.mainnet-beta.solana.com",
localnet: "http://127.0.0.1:8899",
} as const;
type NetworkType = keyof typeof NETWORK_URLS;
const argv = yargs
.option("account", {
alias: "a",
description: "Account address to query",
type: "string",
demandOption: true,
})
.option("network", {
alias: "n",
description: "Solana network to use",
choices: ["devnet", "mainnet", "localnet"] as const,
type: "string",
default: "devnet",
})
.help()
.parseSync();
async function decodeAccount(accountAddress: string, network: NetworkType) {
try {
console.log(`Network: ${network}`);
console.log(`Account Address: ${accountAddress}`);
const connection = new Connection(NETWORK_URLS[network]);
const publicKey = new PublicKey(accountAddress);
const accountInfo = await connection.getAccountInfo(publicKey);
if (!accountInfo) {
console.log("❌ Account not found");
return;
}
console.log("\nAccount Basic Info:");
console.log("------------------");
console.log(`Owner: ${accountInfo.owner.toString()}`);
console.log(`Data length: ${accountInfo.data.length} bytes`);
console.log(`Executable: ${accountInfo.executable}`);
console.log(`Lamports: ${accountInfo.lamports / 1e9} SOL`);
// Check if it's an executable program
if (accountInfo.executable) {
console.log("\n✅ This is an Executable Program Account");
// Decode first 8 bytes of program data (often contains a discriminator)
const programData = accountInfo.data.slice(0, 8);
console.log(`Program Discriminator: ${bs58.encode(programData)}`);
return;
}
// Check if it's a Token Program account
if (accountInfo.owner.equals(TOKEN_PROGRAM_ID)) {
// Token Mint Account (82 bytes)
if (accountInfo.data.length === MintLayout.span) {
console.log("\n✅ This is a Token Mint Account");
const mintInfo = MintLayout.decode(accountInfo.data);
console.log("\nDecoded Mint Info:", {
mintAuthority: mintInfo.mintAuthority?.toString(),
supply: mintInfo.supply.toString(),
decimals: mintInfo.decimals,
isInitialized: mintInfo.isInitialized,
freezeAuthority: mintInfo.freezeAuthority?.toString(),
});
return;
}
// Token Account (165 bytes)
if (accountInfo.data.length === AccountLayout.span) {
console.log("\n✅ This is a Token Account");
const tokenInfo = AccountLayout.decode(accountInfo.data);
console.log("\nDecoded Token Info:", {
mint: tokenInfo.mint.toString(),
owner: tokenInfo.owner.toString(),
amount: tokenInfo.amount.toString(),
delegateOption: tokenInfo.delegateOption,
delegate: tokenInfo.delegate.toString(),
state: tokenInfo.state,
isNativeOption: tokenInfo.isNativeOption,
isNative: tokenInfo.isNative,
delegatedAmount: tokenInfo.delegatedAmount.toString(),
closeAuthorityOption: tokenInfo.closeAuthorityOption,
closeAuthority: tokenInfo.closeAuthority.toString(),
});
return;
}
}
// Regular account with data
if (accountInfo.data.length > 0) {
console.log(
"\n✅ This is a Program-Owned Account (PDA) or Custom Account"
);
console.log("\nRaw Data:");
console.log("Base58:", bs58.encode(accountInfo.data));
console.log("Hex:", Buffer.from(accountInfo.data).toString("hex"));
// Try to decode as UTF-8 in case it contains readable text
try {
const textDecoder = new TextDecoder();
const text = textDecoder.decode(accountInfo.data);
if (text.match(/^[\x00-\x7F]*$/)) {
// Check if ASCII
console.log("UTF-8:", text);
}
} catch (e) {
// Ignore UTF-8 decode errors
}
return;
}
// System account (just lamports, no data)
console.log("\n✅ This is a System Account (only holds SOL)");
} catch (error) {
console.error("Error decoding account:", error;
## Create token account(Token Account)
Let's create a token account to hold units of the token specified in the create-account command.
From `spl-token create-account --help` command, to create a token account, we need to provide the token mint address `<TOKEN_MINT_ADDRESS>`(created in the previous step via `spl-token create-token`) and the account keypair.
```bash
spl-token-create-account
Create a new token account
USAGE:
spl-token create-account [FLAGS] [OPTIONS] <TOKEN_MINT_ADDRESS> [ACCOUNT_KEYPAIR]
ARGS:
<TOKEN_MINT_ADDRESS> The token that the account will hold
<ACCOUNT_KEYPAIR> Specify the account keypair. This may be a keypair file or the ASK
keyword. [default: associated token account for --owner]
Let's create a token account for the token mint address 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY.
spl-token create-account 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY
The output:
Creating account 7HSevHURThjhH4BeygaaBxyT7BSYruysmcRjoUPsUzLP
Signature: 4HJ2uZBV32CLaxAvML6hZe49qhcXatzUTnN7r7t1fYrYYSQDb4kwh4kVdvhfBmRVLU3wN37ETjm9XF1nKKrtKhQD
NOTE: You cannot create a token account if it's already exists.
spl-token create-account 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY
Creating account 7HSevHURThjhH4BeygaaBxyT7BSYruysmcRjoUPsUzLP
Error: "Error: Account already exists: 7HSevHURThjhH4BeygaaBxyT7BSYruysmcRjoUPsUzLP"
You can pass create-account --owner <owner address> to create token account for specified user.
Decode Account - Token Account
Decode Token Account using spl-token display
Let's run spl-token display to decode this token account.
spl-token di
splay 7HSevHURThjhH4BeygaaBxyT7BSYruysmcRjoUPsUzLP
SPL Token Account
Address: 7HSevHURThjhH4BeygaaBxyT7BSYruysmcRjoUPsUzLP
Program: TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA
Balance: 0
Decimals: 9
Mint: 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY
Owner: 7HjK9uvhowd7JZyq2fH5LAhCzELTuBq5oWHEBtB9SMwn
State: Initialized
Delegation: (not set)
Close authority: (not set)
Decode Token Account using AccountLayout.decode
Let's use AccountLayout.decode to decode this token account.
npx ts-node
decode-account.ts -a 7HSevHURThjhH4BeygaaBxyT7BSYruysmcRjoUPsUzLP
Network: devnet
Account Address: 7HSevHURThjhH4BeygaaBxyT7BSYruysmcRjoUPsUzLP
(node:34568) [DEP0040] DeprecationWarning: The `punycode` module is deprecated. Please use a userland alternative instead.
(Use `node --trace-deprecation ...` to show where the warning was created)
Account Basic Info:
------------------
Owner: TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA
Data length: 165 bytes
Executable: false
Lamports: 0.00203928 SOL
✅ This is a Token Account
Decoded Token Info: {
mint: '23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY',
owner: '7HjK9uvhowd7JZyq2fH5LAhCzELTuBq5oWHEBtB9SMwn',
amount: '0',
delegateOption: 0,
delegate: '11111111111111111111111111111111',
state: 1,
isNativeOption: 0,
isNative: 0n,
delegatedAmount: '0',
closeAuthorityOption: 0,
closeAuthority: '11111111111111111111111111111111'
}
As there's no balance in new token account, the balance in decoded token info is 0.
Mint token
To mint tokens, use spl-token mint <token address> <amount>.
spl-token mint 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY 10000000
Output:
Minting 10000000 tokens
Token: 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY
Recipient: 7HSevHURThjhH4BeygaaBxyT7BSYruysmcRjoUPsUzLP
Recipient is the address of your wallet's token account. You can check the balance at https://solana.fm/address/7HSevHURThjhH4BeygaaBxyT7BSYruysmcRjoUPsUzLP/tokens?cluster=devnet-alpha
Also note that minting tokens will fail if the recipient token account has not been created first. You must create a token account before you can mint tokens to it.
spl-token mint 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY 10000000
Error: "Account 7HSevHURThjhH4BeygaaBxyT7BSYruysmcRjoUPsUzLP not found"
Transfer
First, let's mint token for another wallet Cw8N9C5eWfxJe6nNoYYL6Q4xNfH5BpCpFuPU6hPPkv4C.
spl-token create-account --owner Cw8N9C5eWfxJe6nNoYYL6Q4xNfH5BpCpFuPU6hPPkv4C 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY --fee-payer ~/.config/solana/id.json
NOTE: --fee-payer must be provided.
Output:
Creating account 6XVWmgPnpvLom7MSjvgvuUhNh1yzSdktpK8PTapRYkXd
Signature: 67GJs35AWa2zqBo5kqJmae7x4s9vZCa8hinxizZz3Ac7ZwWUeamEdsjTbUskhVpgTBd1cDPdsCRYFoUJeCwauCL1
The account 6XVWmgPnpvLom7MSjvgvuUhNh1yzSdktpK8PTapRYkXd is the token account for another wallet Cw8N9C5eWfxJe6nNoYYL6Q4xNfH5BpCpFuPU6hPPkv4C.
Next, we'll mint token for another token account 6XVWmgPnpvLom7MSjvgvuUhNh1yzSdktpK8PTapRYkXd.
spl-token mint 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY 987654321 -- 6XVWmgPnpvLom7MSjvgvuUhNh1yzSdktpK8PTapRYkXd
Minting 987654321 tokens
Token: 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY
Recipient: 6XVWmgPnpvLom7MSjvgvuUhNh1yzSdktpK8PTapRYkXd
Signature: 4KreanW6ftnE85JXhXf1phS9KhFoL7Dhru9JE8cP3ui3sfCtJ5oa3cTstkguBpbqs9843owCZsU91HoHk4rWZRzG
💰 Check the balance at https://solana.fm/address/6XVWmgPnpvLom7MSjvgvuUhNh1yzSdktpK8PTapRYkXd/tokens?cluster=devnet-alpha
Finally, let's transfer 777777 tokens to another token account 6XVWmgPnpvLom7MSjvgvuUhNh1yzSdktpK8PTapRYkXd.
spl-token transfer 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY 777777 6XVWmgPnpvLom7MSjvgvuUhNh1yzSdktpK8PTapRYkXd
Output:
spl-token transfer 23b9PTjuFNRrobSTmydcf4bWrei2bRdLfpwRAR8RtAUY 777777 6XVWmgPnpvLom7MSjvgvuUhNh1yzSdktpK8PTapRYkXd
Transfer 777777 tokens
Sender: 7HSevHURThjhH4BeygaaBxyT7BSYruysmcRjoUPsUzLP
Recipient: 6XVWmgPnpvLom7MSjvgvuUhNh1yzSdktpK8PTapRYkXd
Signature: 5Eni3GJGBiLFJYAigPYd5hTk4zXMHDLpVseBLVNQF2SVyunUfq3Wewpo5FoKWLdJYHK45D49m7K2K5iPYqHE5yQ4
The transaction is here https://solana.fm/tx/4Md3ycC6a2rU2gKXV9rY1eRdL36xULBN36aNkK6TFqKjDPKTa6GoaBzQfjMVe955HdZpRGPizhNdBEEsmc2GmZs6?cluster=devnet-alpha%3Fcluster%3Ddevnet-alpha
Transfer if token account is not exist
If the token account is not existed, we can specify --fund-recipient option to fund the receiver's associated token account, at the sender's expense.
Let's create a new keypair using solana-keygen. The public key is 7VNq6ixbLWTz85vQLqwuUUSV66LYhhhCUMKZ13uQmuhx.
solana-keygen new -o account-1.json
Generating a new keypair
For added security, enter a BIP39 passphrase
NOTE! This passphrase improves security of the recovery seed phrase NOT the
keypair file itself, which is stored as insecure plain text
BIP39 Passphrase (empty for none):
Wrote new keypair to account-1.json
=============================================================================
pubkey: 7VNq6ixbLWTz85vQLqwuUUSV66LYhhhCUMKZ13uQmuhx
=============================================================================
Save this seed phrase and your BIP39 passphrase to recover your new keypair:
odor talk orchard cable real assault common artefact example castle idle wall
=============================================================================
Let's create a mint token and a token account to hold the token.
spl-token create-token
Creating token J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm under program TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA
Address: J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm
Decimals: 9
Signature: 2xb99CCpA7nCxjYLjGrY7aYjV4VUk4h9ox7qSnTamN4Cm4QbW6xA9PwDXoWKUFQpPicY495DvoSXNdFv8fs28yWo
Create a token account to hold mint token J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm.
spl-token create-account J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm
Creating account AB7baqsAgkfjwQtekTuvzT5amuM1xrRSUxRpqdnkWngJ
Signature: 5YYX9XWdUwCanBzUc1sbX7XH7fqwcckrFCZQNL1AZXvsN9kjuTUCeG1uP9hWuftT5PFn4mSWNFKBEwyTBjU6LHvV
We'll mint 100 tokens to token account AB7baqsAgkfjwQtekTuvzT5amuM1xrRSUxRpqdnkWngJ.
spl-token mint J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm 100
Minting 100 tokens
Token: J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm
Recipient: AB7baqsAgkfjwQtekTuvzT5amuM1xrRSUxRpqdnkWngJ
Signature: 2AQNdA8yzLRwwNHMhdgk4nJEgqXZKnrHCNuXqGgUYBhTomq6rSwMUuk8RARC16eRSoBZDkS2Xnyc5a6CkH3tEMFG
Now, let's transfer 20 tokens to account 7VNq6ixbLWTz85vQLqwuUUSV66LYhhhCUMKZ13uQmuhx (created by solana-keygen).
spl-token transfer J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm 20 7VNq6ixbLWTz85vQLqwuUUSV66LYhhhCUMKZ13uQmuhx
Transfer 20 tokens
Sender: AB7baqsAgkfjwQtekTuvzT5amuM1xrRSUxRpqdnkWngJ
Recipient: 7VNq6ixbLWTz85vQLqwuUUSV66LYhhhCUMKZ13uQmuhx
Error: "Error: The recipient address is not funded. Add `--allow-unfunded-recipient` to complete the transfer."
We encounter an error. Let's pass --allow-unfunded-recipient option to transfer subcommand.
spl-token transfer --allow-unfunded-recipient J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm 20 7VNq6ixbLWTz85vQLqwuUUSV66LYhhhCUMKZ13uQmuhx
Transfer 20 tokens
Sender: AB7baqsAgkfjwQtekTuvzT5amuM1xrRSUxRpqdnkWngJ
Recipient: 7VNq6ixbLWTz85vQLqwuUUSV66LYhhhCUMKZ13uQmuhx
Recipient associated token account: 7Q3GEiV3E9ccjP8Wyo6kyLi68QaSev1LfpRsyeQFQnyk
Error: "Error: Recipient's associated token account does not exist. Add `--fund-recipient` to fund their account"
Another error occurred. Let's pass --fund-recipient option to transfer subcommand.
Let's transfer tokens using --fund-recipient option.
spl-token transfer --allow-unfunded-recipient --fund-recipient J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm 20 7VNq6ixbLWTz85vQLqwuUUSV66LYhhhCUMKZ13uQmuhx
Transfer 20 tokens
Sender: AB7baqsAgkfjwQtekTuvzT5amuM1xrRSUxRpqdnkWngJ
Recipient: 7VNq6ixbLWTz85vQLqwuUUSV66LYhhhCUMKZ13uQmuhx
Recipient associated token account: 7Q3GEiV3E9ccjP8Wyo6kyLi68QaSev1LfpRsyeQFQnyk
Funding recipient: 7Q3GEiV3E9ccjP8Wyo6kyLi68QaSev1LfpRsyeQFQnyk
Signature: 2YvAX3J256pWVb2GqguqbAepLaGxXyGHST2yUZk4z7ojNcGkyLNMMAE7UdGt3vmkUzj8WcCSHUWsBvgYCM1oJtpm
We'll see we have 80 tokens in balance, with 20 tokens transfered.
spl-token accounts
Token Balance
--------------------------------------------------------
So11111111111111111111111111111111111111112 0.99796072
J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm 80
We can check token account balance for 7Q3GEiV3E9ccjP8Wyo6kyLi68QaSev1LfpRsyeQFQnyk(sender funded token account through --fund-recipient option).
spl-token balance --address 7Q3GEiV3E9ccjP8Wyo6kyLi68QaSev1LfpRsyeQFQnyk
20
Create token metadata
To create a token with metadata, you can pass the --enable-metadata option.
If you don't use the token 2022 program ID, you'll get a IncorrectProgramId error.
spl-token create-token --enable-metadata
Creating token ATsFvKCKSibNTsUNodjgpsFw52DTvf3qFtXaWtnVp35Z under program TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA
Error: Program(IncorrectProgramId)
To avoid this error, use the token 2022 program ID:
spl-token create-token --program-id TokenzQdBNbLqP5VEhdkAS6EPFLC1PHnBqCXEpPxuEb --enable-metadata
NOTE: TokenzQdBNbLqP5VEhdkAS6EPFLC1PHnBqCXEpPxuEb is a token-2022 program address in spl github repo.
See https://spl.solana.com/token-2022 for more details.
The source code is located in https://github.com/solana-labs/solana-program-library/tree/master/token/program-2022
Output:
Creating token xpJkcpUuL4gxmqfZXBXnH15sUUNRtFgrB41rSYu5mnF under program TokenzQdBNbLqP5VEhdkAS6EPFLC1PHnBqCXEpPxuEb
To initialize metadata inside the mint, please run `spl-token initialize-metadata xpJkcpUuL4gxmqfZXBXnH15sUUNRtFgrB41rSYu5mnF <YOUR_TOKEN_NAME> <YOUR_TOKEN_SYMBOL> <YOUR_TOKEN_URI>`, and sign with the mint authority.
Address: xpJkcpUuL4gxmqfZXBXnH15sUUNRtFgrB41rSYu5mnF
Decimals: 9
Signature: 5QErL4ZfNfgoRuc2JyS76TYPw9W8vmj6EM6mcy2KAMToGRaHHJ7nHijqoSgN8ZRFfwKXBQUs6BGoy1W3bcHoTgDj
Now, a new token is created, we can initialize token with metadata.
spl-token initialize-metadata <TOKEN_MINT_ADDRESS> <YOUR_TOKEN_NAME> <YOUR_TOKEN_SYMBOL> <YOUR_TOKEN_URI>
Run:
spl-token initialize-metadata xpJkcpUuL4gxmqfZXBXnH15sUUNRtFgrB41rSYu5mnF "Helloworld" "HelloWorld" "https://raw.githubusercontent.com/solana-developers/opos-asset/main/assets/DeveloperPortal/metadata.json"
Signature: 4mT6j4Smy6tnrEEBdmKpWvgbVoP9nc8q3uPY1rtn2LyTw5EepYdp5ctdmcL7vKSw22LC9h9J3xp8aRXd2RLqH95S
We use metadata in this url: https://raw.githubusercontent.com/solana-developers/opos-asset/main/assets/DeveloperPortal/metadata.json
{
"name": "OPOS",
"symbol": "OPOS",
"description": "Only Possible On Solana",
"image": "https://raw.githubusercontent.com/solana-developers/opos-asset/main/assets/DeveloperPortal/image.png",
"attributes": [
{
"trait_type": "Item",
"value": "Developer Portal"
}
]
}
Check token metadata: https://solana.fm/address/xpJkcpUuL4gxmqfZXBXnH15sUUNRtFgrB41rSYu5mnF/tokens?cluster=devnet-alpha
There are two transactions involved:
-
https://explorer.solana.com/tx/5QErL4ZfNfgoRuc2JyS76TYPw9W8vmj6EM6mcy2KAMToGRaHHJ7nHijqoSgN8ZRFfwKXBQUs6BGoy1W3bcHoTgDj?cluster=devnet
-
https://explorer.solana.com/tx/4mT6j4Smy6tnrEEBdmKpWvgbVoP9nc8q3uPY1rtn2LyTw5EepYdp5ctdmcL7vKSw22LC9h9J3xp8aRXd2RLqH95S?cluster=devnet
Transaction beginning with 5QEr...: called MetadataPointerInstruction::Initialize and Instruction: InitializeMint to create a token mint account with metadata.
Program 11111111111111111111111111111111 invoke [1] Program 11111111111111111111111111111111 success Program TokenzQdBNbLqP5VEhdkAS6EPFLC1PHnBqCXEpPxuEb invoke [1] Program log: MetadataPointerInstruction::Initialize Program TokenzQdBNbLqP5VEhdkAS6EPFLC1PHnBqCXEpPxuEb consumed 2441 of 6591 compute units Program TokenzQdBNbLqP5VEhdkAS6EPFLC1PHnBqCXEpPxuEb success Program TokenzQdBNbLqP5VEhdkAS6EPFLC1PHnBqCXEpPxuEb invoke [1] Program log: Instruction: InitializeMint Program TokenzQdBNbLqP5VEhdkAS6EPFLC1PHnBqCXEpPxuEb consumed 4000 of 4150 compute units Program TokenzQdBNbLqP5VEhdkAS6EPFLC1PHnBqCXEpPxuEb success Program ComputeBudget111111111111111111111111111111 invoke [1] Program ComputeBudget111111111111111111111111111111 success
Transaction beginning with 4mT6... called TokenMetadataInstruction: Initialize to initialize the metadata.
Program 11111111111111111111111111111111 invoke [1] Program 11111111111111111111111111111111 success Program TokenzQdBNbLqP5VEhdkAS6EPFLC1PHnBqCXEpPxuEb invoke [1] Program log: TokenMetadataInstruction: Initialize Program TokenzQdBNbLqP5VEhdkAS6EPFLC1PHnBqCXEpPxuEb consumed 9669 of 9819 compute units Program TokenzQdBNbLqP5VEhdkAS6EPFLC1PHnBqCXEpPxuEb success Program ComputeBudget111111111111111111111111111111 invoke [1] Program ComputeBudget111111111111111111111111111111 success
You can examine the source code in detail to understand what happens. DYOR :)
spl-token cli source code
spl-token cli main function structure
The source code of spl-token is located in https://github.com/solana-labs/solana-program-library/blob/2dff12b0e5b08393999d843f52733098f398ce44/token/cli/src/main.rs#L8
The main function is the entry point of the spl-token command.
It uses the clap crate to parse the command line arguments and subcommands.
use { solana_sdk::signer::Signer, spl_token_cli::{clap_app::*, command::process_command, config::Config}, std::{str::FromStr, sync::Arc}, }; #[tokio::main] async fn main() -> Result<(), Error> { let default_decimals = format!("{}", spl_token_2022::native_mint::DECIMALS); let minimum_signers_help = minimum_signers_help_string(); let multisig_member_help = multisig_member_help_string(); let app_matches = app( &default_decimals, &minimum_signers_help, &multisig_member_help, ) .get_matches(); let mut wallet_manager = None; let mut bulk_signers: Vec<Arc<dyn Signer>> = Vec::new(); let (sub_command, matches) = app_matches.subcommand().unwrap(); let sub_command = CommandName::from_str(sub_command).unwrap(); let mut multisigner_ids = Vec::new(); let config = Config::new( matches, &mut wallet_manager, &mut bulk_signers, &mut multisigner_ids, ) .await; solana_logger::setup_with_default("solana=info"); let result = process_command(&sub_command, matches, &config, wallet_manager, bulk_signers).await?; println!("{}", result); Ok(()) }
The process_command function is the entry point of the spl-token command. Basically, it matches the subcommand and then calls the corresponding function to handle the command. In this case, it matches the CommandName::CreateToken subcommand and then calls the command_create_token function to handle the command.
#![allow(unused)] fn main() { pub async fn process_command<'a>( sub_command: &CommandName, sub_matches: &ArgMatches, config: &Config<'a>, mut wallet_manager: Option<Rc<RemoteWalletManager>>, mut bulk_signers: Vec<Arc<dyn Signer>>, ) -> CommandResult { match (sub_command, sub_matches) { (CommandName::Bench, arg_matches) => {} (CommandName::CreateToken, arg_matches) => {} (CommandName::SetInterestRate, arg_matches) => {} (CommandName::SetTransferHook, arg_matches) => {} (CommandName::InitializeMetadata, arg_matches) => {} (CommandName::UpdateMetadata, arg_matches) => {} (CommandName::InitializeGroup, arg_matches) => {} (CommandName::UpdateGroupMaxSize, arg_matches) => {} (CommandName::InitializeMember, arg_matches) => {} (CommandName::CreateAccount, arg_matches) => {} (CommandName::CreateMultisig, arg_matches) => {} (CommandName::Authorize, arg_matches) => {} (CommandName::Transfer, arg_matches) => {} (CommandName::Burn, arg_matches) => {} (CommandName::Mint, arg_matches) => {} (CommandName::Freeze, arg_matches) => {} (CommandName::Thaw, arg_matches) => {} (CommandName::Wrap, arg_matches) => {} (CommandName::Unwrap, arg_matches) => {} (CommandName::Approve, arg_matches) => {} (CommandName::Revoke, arg_matches) => {} (CommandName::Close, arg_matches) => {} (CommandName::CloseMint, arg_matches) => {} (CommandName::Balance, arg_matches) => {} (CommandName::Supply, arg_matches) => {} (CommandName::Accounts, arg_matches) => {} (CommandName::Address, arg_matches) => {} (CommandName::AccountInfo, arg_matches) => {} (CommandName::MultisigInfo, arg_matches) => {} (CommandName::Display, arg_matches) => {} (CommandName::Gc, arg_matches) => {} (CommandName::SyncNative, arg_matches) => {} (CommandName::EnableRequiredTransferMemos, arg_matches) => {} (CommandName::DisableRequiredTransferMemos, arg_matches) => {} (CommandName::EnableCpiGuard, arg_matches) => {} (CommandName::DisableCpiGuard, arg_matches) => {} (CommandName::UpdateDefaultAccountState, arg_matches) => {} (CommandName::UpdateMetadataAddress, arg_matches) => {} (CommandName::UpdateGroupAddress, arg_matches) => {} (CommandName::UpdateMemberAddress, arg_matches) => {} (CommandName::WithdrawWithheldTokens, arg_matches) => {} (CommandName::SetTransferFee, arg_matches) => {} (CommandName::WithdrawExcessLamports, arg_matches) => {} (CommandName::UpdateConfidentialTransferSettings, arg_matches) => {} (CommandName::ConfigureConfidentialTransferAccount, arg_matches) => {} (c @ CommandName::EnableConfidentialCredits, arg_matches) | (c @ CommandName::DisableConfidentialCredits, arg_matches) | (c @ CommandName::EnableNonConfidentialCredits, arg_matches) | (c @ CommandName::DisableNonConfidentialCredits, arg_matches) => {} (c @ CommandName::DepositConfidentialTokens, arg_matches) | (c @ CommandName::WithdrawConfidentialTokens, arg_matches) => {} (CommandName::ApplyPendingBalance, arg_matches) => {} } } }
CommandName::CreateToken
Let's examine the CommandName::CreateToken case. In this match arm, the code extracts several arguments from arg_matches:
decimals: The number of decimal places for the token (u8)mint_authority: The public key that will have permission to mint new tokensmemo: An optional string memorate_bps: An optional interest rate in basis points (i16)metadata_address: An optional Pubkey for token metadatagroup_address: An optional Pubkey for token groupmember_address: An optional Pubkey for token member
It also handles transfer fee configuration in two ways:
- Via deprecated
transfer_feeargument that takes two values:- Transfer fee basis points
- Maximum fee amount
- Via newer separate arguments:
transfer_fee_basis_points: Fee rate in basis pointstransfer_fee_maximum_fee: Maximum fee amount with UI parsing
Finally, it sets up the token signer and public key, either from provided keypair or generates new ones, before calling command_create_token to create the token.
#![allow(unused)] fn main() { pub async fn process_command<'a>( sub_command: &CommandName, sub_matches: &ArgMatches, config: &Config<'a>, mut wallet_manager: Option<Rc<RemoteWalletManager>>, mut bulk_signers: Vec<Arc<dyn Signer>>, ) -> CommandResult { match (sub_command, sub_matches) { // ... (CommandName::CreateToken, arg_matches) => { let decimals = *arg_matches.get_one::<u8>("decimals").unwrap(); let mint_authority = config.pubkey_or_default(arg_matches, "mint_authority", &mut wallet_manager)?; let memo = value_t!(arg_matches, "memo", String).ok(); let rate_bps = value_t!(arg_matches, "interest_rate", i16).ok(); let metadata_address = value_t!(arg_matches, "metadata_address", Pubkey).ok(); let group_address = value_t!(arg_matches, "group_address", Pubkey).ok(); let member_address = value_t!(arg_matches, "member_address", Pubkey).ok(); let transfer_fee = arg_matches.values_of("transfer_fee").map(|mut v| { println_display(config,"transfer-fee has been deprecated and will be removed in a future release. Please specify --transfer-fee-basis-points and --transfer-fee-maximum-fee with a UI amount".to_string()); ( v.next() .unwrap() .parse::<u16>() .unwrap_or_else(print_error_and_exit), v.next() .unwrap() .parse::<u64>() .unwrap_or_else(print_error_and_exit), ) }); let transfer_fee_basis_point = arg_matches.get_one::<u16>("transfer_fee_basis_points"); let transfer_fee_maximum_fee = arg_matches .get_one::<Amount>("transfer_fee_maximum_fee") .map(|v| amount_to_raw_amount(*v, decimals, None, "MAXIMUM_FEE")); let transfer_fee = transfer_fee_basis_point .map(|v| (*v, transfer_fee_maximum_fee.unwrap())) .or(transfer_fee); let (token_signer, token) = get_signer(arg_matches, "token_keypair", &mut wallet_manager) .unwrap_or_else(new_throwaway_signer); push_signer_with_dedup(token_signer, &mut bulk_signers); let default_account_state = arg_matches .value_of("default_account_state") .map(|s| match s { "initialized" => AccountState::Initialized, "frozen" => AccountState::Frozen, _ => unreachable!(), }); let transfer_hook_program_id = pubkey_of_signer(arg_matches, "transfer_hook", &mut wallet_manager).unwrap(); let confidential_transfer_auto_approve = arg_matches .value_of("enable_confidential_transfers") .map(|b| b == "auto"); // The code above prepares all the necessary variables and parameters that will be passed to // the command_create_token function, including: // - Token decimals and authority // - Various enable flags (freeze, close, non-transferable, etc.) // - Optional parameters like memo, metadata address, group/member addresses // - Transfer fee configuration // - Account state and confidential transfer settings // 👀 👀 👀 👀 👀 👀 👀 👀 // This is the dirty work. // 👀 👀 👀 👀 👀 👀 👀 👀 command_create_token( config, decimals, token, mint_authority, arg_matches.is_present("enable_freeze"), arg_matches.is_present("enable_close"), arg_matches.is_present("enable_non_transferable"), arg_matches.is_present("enable_permanent_delegate"), memo, metadata_address, group_address, member_address, rate_bps, default_account_state, transfer_fee, confidential_transfer_auto_approve, transfer_hook_program_id, arg_matches.is_present("enable_metadata"), arg_matches.is_present("enable_group"), arg_matches.is_present("enable_member"), bulk_signers, ) .await } } } }
Let's focus on the command_create_token function, which will do the dirty work. It uses #[allow(clippy::too_many_arguments)] to suppress the warning about having too many arguments. While this is not ideal from a code design perspective, it's sometimes necessary when dealing with complex token creation parameters.
#![allow(unused)] fn main() { #[allow(clippy::too_many_arguments)] async fn command_create_token( config: &Config<'_>, decimals: u8, token_pubkey: Pubkey, authority: Pubkey, enable_freeze: bool, enable_close: bool, enable_non_transferable: bool, enable_permanent_delegate: bool, memo: Option<String>, metadata_address: Option<Pubkey>, group_address: Option<Pubkey>, member_address: Option<Pubkey>, rate_bps: Option<i16>, default_account_state: Option<AccountState>, transfer_fee: Option<(u16, u64)>, confidential_transfer_auto_approve: Option<bool>, transfer_hook_program_id: Option<Pubkey>, enable_metadata: bool, enable_group: bool, enable_member: bool, bulk_signers: Vec<Arc<dyn Signer>>, ) -> CommandResult { println_display( config, format!( "Creating token {} under program {}", token_pubkey, config.program_id ), ); let token = token_client_from_config(config, &token_pubkey, Some(decimals))?; let freeze_authority = if enable_freeze { Some(authority) } else { None }; let mut extensions = vec![]; if enable_close { extensions.push(ExtensionInitializationParams::MintCloseAuthority { close_authority: Some(authority), }); } if enable_permanent_delegate { extensions.push(ExtensionInitializationParams::PermanentDelegate { delegate: authority, }); } if let Some(rate_bps) = rate_bps { extensions.push(ExtensionInitializationParams::InterestBearingConfig { rate_authority: Some(authority), rate: rate_bps, }) } if enable_non_transferable { extensions.push(ExtensionInitializationParams::NonTransferable); } if let Some(state) = default_account_state { assert!( enable_freeze, "Token requires a freeze authority to default to frozen accounts" ); extensions.push(ExtensionInitializationParams::DefaultAccountState { state }) } if let Some((transfer_fee_basis_points, maximum_fee)) = transfer_fee { extensions.push(ExtensionInitializationParams::TransferFeeConfig { transfer_fee_config_authority: Some(authority), withdraw_withheld_authority: Some(authority), transfer_fee_basis_points, maximum_fee, }); } if let Some(auto_approve) = confidential_transfer_auto_approve { extensions.push(ExtensionInitializationParams::ConfidentialTransferMint { authority: Some(authority), auto_approve_new_accounts: auto_approve, auditor_elgamal_pubkey: None, }); if transfer_fee.is_some() { // Deriving ElGamal key from default signer. Custom ElGamal keys // will be supported in the future once upgrading to clap-v3. // // NOTE: Seed bytes are hardcoded to be empty bytes for now. They // will be updated once custom ElGamal keys are supported. let elgamal_keypair = ElGamalKeypair::new_from_signer(config.default_signer()?.as_ref(), b"").unwrap(); extensions.push( ExtensionInitializationParams::ConfidentialTransferFeeConfig { authority: Some(authority), withdraw_withheld_authority_elgamal_pubkey: (*elgamal_keypair.pubkey()).into(), }, ); } } if let Some(program_id) = transfer_hook_program_id { extensions.push(ExtensionInitializationParams::TransferHook { authority: Some(authority), program_id: Some(program_id), }); } if let Some(text) = memo { token.with_memo(text, vec![config.default_signer()?.pubkey()]); } // CLI checks that only one is set if metadata_address.is_some() || enable_metadata { let metadata_address = if enable_metadata { Some(token_pubkey) } else { metadata_address }; extensions.push(ExtensionInitializationParams::MetadataPointer { authority: Some(authority), metadata_address, }); } if group_address.is_some() || enable_group { let group_address = if enable_group { Some(token_pubkey) } else { group_address }; extensions.push(ExtensionInitializationParams::GroupPointer { authority: Some(authority), group_address, }); } if member_address.is_some() || enable_member { let member_address = if enable_member { Some(token_pubkey) } else { member_address }; extensions.push(ExtensionInitializationParams::GroupMemberPointer { authority: Some(authority), member_address, }); } let res = token .create_mint( &authority, freeze_authority.as_ref(), extensions, &bulk_signers, ) .await?; let tx_return = finish_tx(config, &res, false).await?; if enable_metadata { println_display( config, format!( "To initialize metadata inside the mint, please run \ `spl-token initialize-metadata {token_pubkey} <YOUR_TOKEN_NAME> <YOUR_TOKEN_SYMBOL> <YOUR_TOKEN_URI>`, \ and sign with the mint authority.", ), ); } if enable_group { println_display( config, format!( "To initialize group configurations inside the mint, please run `spl-token initialize-group {token_pubkey} <MAX_SIZE>`, and sign with the mint authority.", ), ); } if enable_member { println_display( config, format!( "To initialize group member configurations inside the mint, please run `spl-token initialize-member {token_pubkey}`, and sign with the mint authority and the group's update authority.", ), ); } Ok(match tx_return { TransactionReturnData::CliSignature(cli_signature) => format_output( CliCreateToken { address: token_pubkey.to_string(), decimals, transaction_data: cli_signature, }, &CommandName::CreateToken, config, ), TransactionReturnData::CliSignOnlyData(cli_sign_only_data) => { format_output(cli_sign_only_data, &CommandName::CreateToken, config) } }) } }
This function creates a new SPL Token with the specified parameters. It first initializes a token client with the given token public key and decimals. Then it calls create_mint to create the actual token on-chain, passing in:
- The mint authority that can mint new tokens
- An optional freeze authority that can freeze token accounts
- Any token extensions enabled (like metadata, groups, etc)
- The bulk signers needed to authorize the transaction
The create_mint call returns a transaction signature that is processed and returned to the caller.
We can briefly summarize the command_create_token function as follows:
#![allow(unused)] fn main() { // 1) create the token client let token = token_client_from_config(config, &token_pubkey, Some(decimals))?; // 2) create the mint let res = token .create_mint( &authority, freeze_authority.as_ref(), extensions, &bulk_signers, ) .await?; // 3) return the transaction signature let tx_return = finish_tx(config, &res, false).await?; }
Let's take a look at the first part: creating token client via token_client_from_config function.
The token_client_from_config function is used to create a token client with the given configuration. It first calls base_token_client to create a basic token client, then calls config_token_client to apply any additional configuration settings from the config object.
#![allow(unused)] fn main() { fn token_client_from_config( config: &Config<'_>, token_pubkey: &Pubkey, decimals: Option<u8>, ) -> Result<Token<ProgramRpcClientSendTransaction>, Error> { let token = base_token_client(config, token_pubkey, decimals)?; config_token_client(token, config) } }
The base_token_client function is used to create a basic token client. It takes the config, token_pubkey, and decimals as arguments and returns a Result<Token<ProgramRpcClientSendTransaction>, Error>.
#![allow(unused)] fn main() { fn base_token_client( config: &Config<'_>, token_pubkey: &Pubkey, decimals: Option<u8>, ) -> Result<Token<ProgramRpcClientSendTransaction>, Error> { Ok(Token::new( config.program_client.clone(), &config.program_id, token_pubkey, decimals, config.fee_payer()?.clone(), )) } }
After token client is created, the config_token_client function is used to apply any additional configuration settings from the config object to the token client. It sets the compute unit limit, compute unit price, and nonce account if they are provided in the config object.
#![allow(unused)] fn main() { fn config_token_client( token: Token<ProgramRpcClientSendTransaction>, config: &Config<'_>, ) -> Result<Token<ProgramRpcClientSendTransaction>, Error> { let token = token.with_compute_unit_limit(config.compute_unit_limit.clone()); let token = if let Some(compute_unit_price) = config.compute_unit_price { token.with_compute_unit_price(compute_unit_price) } else { token }; if let (Some(nonce_account), Some(nonce_authority), Some(nonce_blockhash)) = ( config.nonce_account, &config.nonce_authority, config.nonce_blockhash, ) { Ok(token.with_nonce( &nonce_account, Arc::clone(nonce_authority), &nonce_blockhash, )) } else { Ok(token) } } }
The Token::new function is used to create a new Token instance. It takes the client, program_id, address, decimals, and payer as arguments and returns a Token instance.
#![allow(unused)] fn main() { impl<T> Token<T> where T: SendTransaction + SimulateTransaction, { pub fn new( client: Arc<dyn ProgramClient<T>>, program_id: &Pubkey, address: &Pubkey, decimals: Option<u8>, payer: Arc<dyn Signer>, ) -> Self { Token { client, pubkey: *address, decimals, payer, program_id: *program_id, nonce_account: None, nonce_authority: None, nonce_blockhash: None, memo: Arc::new(RwLock::new(None)), transfer_hook_accounts: None, compute_unit_price: None, compute_unit_limit: ComputeUnitLimit::Default, } } } }
The Token struct is defined as follows:
#![allow(unused)] fn main() { pub struct Token<T> { client: Arc<dyn ProgramClient<T>>, pubkey: Pubkey, /* token mint */ decimals: Option<u8>, payer: Arc<dyn Signer>, program_id: Pubkey, nonce_account: Option<Pubkey>, nonce_authority: Option<Arc<dyn Signer>>, nonce_blockhash: Option<Hash>, memo: Arc<RwLock<Option<TokenMemo>>>, transfer_hook_accounts: Option<Vec<AccountMeta>>, compute_unit_price: Option<u64>, compute_unit_limit: ComputeUnitLimit, } }
It is a generic struct that represents an SPL Token. It contains various fields that store information about the token, such as its client, pubkey, decimals, payer, program_id, nonce_account, nonce_authority, nonce_blockhash, memo, transfer_hook_accounts, compute_unit_price, and compute_unit_limit.
You may notice that the client field is an Arc<dyn ProgramClient<T>>. This is a generic type that implements the ProgramClient trait. It's used to send transactions to the network.
It's actually an instance of ProgramRpcClient that implements ProgramClient trait. It's created in Config::new function in fn main. It wraps RpcClient and provides additional features for programmatic use. We'll talk about it later.
#![allow(unused)] fn main() { impl<'a> Config<'a> { pub async fn new( matches: &ArgMatches, wallet_manager: &mut Option<Rc<RemoteWalletManager>>, bulk_signers: &mut Vec<Arc<dyn Signer>>, multisigner_ids: &'a mut Vec<Pubkey>, ) -> Config<'a> { let rpc_client = Arc::new(RpcClient::new_with_timeouts_and_commitment( json_rpc_url, DEFAULT_RPC_TIMEOUT, commitment_config, DEFAULT_CONFIRM_TX_TIMEOUT, )); Arc::new(ProgramRpcClient::new( rpc_client.clone(), ProgramRpcClientSendTransaction, )) } } }
create_mint
The create_mint function is a public method for Token struct that creates a new SPL Token. It takes the mint_authority, freeze_authority, extension_initialization_params, and signing_keypairs as arguments and returns a TokenResult<T::Output>.
Let's how create_mint function works:
#![allow(unused)] fn main() { impl<T> Token<T> where T: SendTransaction + SimulateTransaction, { #[allow(clippy::too_many_arguments)] pub async fn create_mint<'a, S: Signers>( &self, mint_authority: &'a Pubkey, freeze_authority: Option<&'a Pubkey>, extension_initialization_params: Vec<ExtensionInitializationParams>, signing_keypairs: &S, ) -> TokenResult<T::Output> { let decimals = self.decimals.ok_or(TokenError::MissingDecimals)?; let extension_types = extension_initialization_params .iter() .map(|e| e.extension()) .collect::<Vec<_>>(); let space = ExtensionType::try_calculate_account_len::<Mint>(&extension_types)?; let mut instructions = vec![system_instruction::create_account( &self.payer.pubkey(), &self.pubkey, self.client .get_minimum_balance_for_rent_exemption(space) .await .map_err(TokenError::Client)?, space as u64, &self.program_id, )]; for params in extension_initialization_params { instructions.push(params.instruction(&self.program_id, &self.pubkey)?); } instructions.push(instruction::initialize_mint( &self.program_id, &self.pubkey, mint_authority, freeze_authority, decimals, )?); self.process_ixs(&instructions, signing_keypairs).await } } }
Let's see how these arguments are used in the process_command function.
First, mint_authority is set to the pubkey of the signer. It is defaulted to the pubkey of the signer if not provided.
#![allow(unused)] fn main() { pub async fn process_command<'a>( sub_command: &CommandName, sub_matches: &ArgMatches, config: &Config<'a>, mut wallet_manager: Option<Rc<RemoteWalletManager>>, mut bulk_signers: Vec<Arc<dyn Signer>>, ) -> CommandResult { match (sub_command, sub_matches) { (CommandName::CreateToken, arg_matches) => { let mint_authority = config.pubkey_or_default(arg_matches, "mint_authority", &mut wallet_manager)?; } } } }
The pubkey_or_default function is used to get the pubkey of the signer. It takes the arg_matches, address_name, and wallet_manager as arguments and returns a Result<Pubkey, Error>. If an explicit address is provided, it returns the address. Otherwise, it returns the default address: self.default_signer()?.pubkey().
#![allow(unused)] fn main() { // Checks if an explicit address was provided, otherwise return the default // address if there is one pub(crate) fn pubkey_or_default( &self, arg_matches: &ArgMatches, address_name: &str, wallet_manager: &mut Option<Rc<RemoteWalletManager>>, ) -> Result<Pubkey, Error> { if let Some(address) = pubkey_of_signer(arg_matches, address_name, wallet_manager) .map_err(|e| -> Error { e.to_string().into() })? { return Ok(address); } Ok(self.default_signer()?.pubkey()) } }
The default_signer function will load the default signer from the config file. It is defaulted to ~/.config/solana/cli/config.yml.
#![allow(unused)] fn main() { impl<'a> Config<'a> { // Returns Ok(default signer), or Err if there is no default signer configured pub(crate) fn default_signer(&self) -> Result<Arc<dyn Signer>, Error> { if let Some(default_signer) = &self.default_signer { Ok(default_signer.clone()) } else { Err("default signer is required, please specify a valid default signer by identifying a \ valid configuration file using the --config argument, or by creating a valid config \ at the default location of ~/.config/solana/cli/config.yml using the solana config \ command".to_string().into()) } } pub async fn new_with_clients_and_ws_url( matches: &ArgMatches, wallet_manager: &mut Option<Rc<RemoteWalletManager>>, bulk_signers: &mut Vec<Arc<dyn Signer>>, multisigner_ids: &'a mut Vec<Pubkey>, rpc_client: Arc<RpcClient>, program_client: Arc<dyn ProgramClient<ProgramRpcClientSendTransaction>>, websocket_url: String, ) -> Config<'a> { let cli_config = if let Some(config_file) = matches.value_of("config_file") { solana_cli_config::Config::load(config_file).unwrap_or_else(|_| { eprintln!("error: Could not find config file `{}`", config_file); exit(1); }) } else if let Some(config_file) = &*solana_cli_config::CONFIG_FILE { solana_cli_config::Config::load(config_file).unwrap_or_default() } else { solana_cli_config::Config::default() }; let multisigner_pubkeys = Self::extract_multisig_signers(matches, wallet_manager, bulk_signers, multisigner_ids); let config = SignerFromPathConfig { allow_null_signer: !multisigner_pubkeys.is_empty(), }; let default_keypair = cli_config.keypair_path.clone(); let default_signer: Option<Arc<dyn Signer>> = { if let Some(owner_path) = matches.try_get_one::<String>("owner").ok().flatten() { signer_from_path_with_config(matches, owner_path, "owner", wallet_manager, &config) .ok() } else { signer_from_path_with_config( matches, &default_keypair, "default", wallet_manager, &config, ) .map_err(|e| { if std::fs::metadata(&default_keypair).is_ok() { eprintln!("error: {}", e); exit(1); } else { e } }) .ok() } } .map(Arc::from); } } }
Let's go back to the process_command function.
freeze_authority is set to authority if enable_freeze is true, otherwise it is set to None. This means that if freezing is enabled, the authority (signer) will have the ability to freeze token accounts, preventing any transfers of tokens from those accounts. If freezing is disabled, no one will have the authority to freeze token accounts.
#![allow(unused)] fn main() { #[allow(clippy::too_many_arguments)] async fn command_create_token( config: &Config<'_>, decimals: u8, token_pubkey: Pubkey, authority: Pubkey, enable_freeze: bool, // omit... ) -> CommandResult { let token = token_client_from_config(config, &token_pubkey, Some(decimals))?; let freeze_authority = if enable_freeze { Some(authority) } else { None }; // omit... } }
Then, we'll prepare instructions for creating the token. There are three instructions involved:
system_instruction::create_account- extension initialization instructions(optional)
instruction::initialize_mint
The system_instruction::create_account instruction is used to create a new account with the given parameters.
#![allow(unused)] fn main() { let mut instructions = vec![system_instruction::create_account( &self.payer.pubkey(), &self.pubkey, self.client .get_minimum_balance_for_rent_exemption(space) .await .map_err(TokenError::Client)?, space as u64, &self.program_id, )]; }
If extension parameters exist, we'll push their corresponding initialization instructions to the instructions vector. These extensions can add additional functionality to the token, such as transfer fees or interest-bearing capabilities.
#![allow(unused)] fn main() { for params in extension_initialization_params { instructions.push(params.instruction(&self.program_id, &self.pubkey)?); } }
Next, we'll push the instruction::initialize_mint instruction to the instructions vector.
#![allow(unused)] fn main() { instructions.push(instruction::initialize_mint( &self.program_id, &self.pubkey, mint_authority, freeze_authority, decimals, )); }
Finally, we'll call process_ixs to process the instructions.
#![allow(unused)] fn main() { self.process_ixs(&instructions, signing_keypairs).await }
Below is the implementation of process_ixs function for Token struct.
#![allow(unused)] fn main() { impl<T> Token<T> where T: SendTransaction + SimulateTransaction, { pub async fn process_ixs<S: Signers>( &self, token_instructions: &[Instruction], signing_keypairs: &S, ) -> TokenResult<T::Output> { let transaction = self .construct_tx(token_instructions, signing_keypairs) .await?; self.client .send_transaction(&transaction) .await .map_err(TokenError::Client) } } }
The process_ixs function builds the transaction using construct_tx and submits it to the Solana network via the client's send_transaction method.
If you are interested in the signing part, you can check the construct_tx function.
#![allow(unused)] fn main() { async fn construct_tx<S: Signers>( &self, token_instructions: &[Instruction], signing_keypairs: &S, ) -> TokenResult<Transaction> { let mut instructions = vec![]; let payer_key = self.payer.pubkey(); let fee_payer = Some(&payer_key); { let mut w_memo = self.memo.write().unwrap(); if let Some(memo) = w_memo.take() { let signing_pubkeys = signing_keypairs.pubkeys(); if !memo .signers .iter() .all(|signer| signing_pubkeys.contains(signer)) { return Err(TokenError::MissingMemoSigner); } instructions.push(memo.to_instruction()); } } instructions.extend_from_slice(token_instructions); let blockhash = if let (Some(nonce_account), Some(nonce_authority), Some(nonce_blockhash)) = ( self.nonce_account, &self.nonce_authority, self.nonce_blockhash, ) { let nonce_instruction = system_instruction::advance_nonce_account( &nonce_account, &nonce_authority.pubkey(), ); instructions.insert(0, nonce_instruction); nonce_blockhash } else { self.client .get_latest_blockhash() .await .map_err(TokenError::Client)? }; if let Some(compute_unit_price) = self.compute_unit_price { instructions.push(ComputeBudgetInstruction::set_compute_unit_price( compute_unit_price, )); } // The simulation to find out the compute unit usage must be run after // all instructions have been added to the transaction, so be sure to // keep this instruction as the last one before creating and sending the // transaction. match self.compute_unit_limit { ComputeUnitLimit::Default => {} ComputeUnitLimit::Simulated => { self.add_compute_unit_limit_from_simulation(&mut instructions, &blockhash) .await?; } ComputeUnitLimit::Static(compute_unit_limit) => { instructions.push(ComputeBudgetInstruction::set_compute_unit_limit( compute_unit_limit, )); } } let message = Message::new_with_blockhash(&instructions, fee_payer, &blockhash); let mut transaction = Transaction::new_unsigned(message); let signing_pubkeys = signing_keypairs.pubkeys(); if !signing_pubkeys.contains(&self.payer.pubkey()) { transaction .try_partial_sign(&vec![self.payer.clone()], blockhash) .map_err(|error| TokenError::Client(error.into()))?; } if let Some(nonce_authority) = &self.nonce_authority { let nonce_authority_pubkey = nonce_authority.pubkey(); if nonce_authority_pubkey != self.payer.pubkey() && !signing_pubkeys.contains(&nonce_authority_pubkey) { transaction .try_partial_sign(&vec![nonce_authority.clone()], blockhash) .map_err(|error| TokenError::Client(error.into()))?; } } transaction .try_partial_sign(signing_keypairs, blockhash) .map_err(|error| TokenError::Client(error.into()))?; Ok(transaction) } } }
The transaction is sent through the send_transaction method via ProgramRpcClient, which is a wrapper around RpcClient.
As the documentation of RpcClient says, it communicates with a Solana node over JSON-RPC protocol to submit transactions to the network.
RpcClientcommunicates with a Solana node over [JSON-RPC], with the [Solana JSON-RPC protocol][jsonprot]. It is the primary Rust interface for querying and transacting with the network from external programs.
#![allow(unused)] fn main() { /// A client of a remote Solana node. /// /// `RpcClient` communicates with a Solana node over [JSON-RPC], with the /// [Solana JSON-RPC protocol][jsonprot]. It is the primary Rust interface for /// querying and transacting with the network from external programs. /// /// This type builds on the underlying RPC protocol, adding extra features such /// as timeout handling, retries, and waiting on transaction [commitment levels][cl]. /// Some methods simply pass through to the underlying RPC protocol. Not all RPC /// methods are encapsulated by this type, but `RpcClient` does expose a generic /// [`send`](RpcClient::send) method for making any [`RpcRequest`]. /// /// The documentation for most `RpcClient` methods contains an "RPC Reference" /// section that links to the documentation for the underlying JSON-RPC method. /// The documentation for `RpcClient` does not reproduce the documentation for /// the underlying JSON-RPC methods. Thus reading both is necessary for complete /// understanding. /// /// `RpcClient`s generally communicate over HTTP on port 8899, a typical server /// URL being "http://localhost:8899". /// /// Methods that query information from recent [slots], including those that /// confirm transactions, decide the most recent slot to query based on a /// [commitment level][cl], which determines how committed or finalized a slot /// must be to be considered for the query. Unless specified otherwise, the /// commitment level is [`Finalized`], meaning the slot is definitely /// permanently committed. The default commitment level can be configured by /// creating `RpcClient` with an explicit [`CommitmentConfig`], and that default /// configured commitment level can be overridden by calling the various /// `_with_commitment` methods, like /// [`RpcClient::confirm_transaction_with_commitment`]. In some cases the /// configured commitment level is ignored and `Finalized` is used instead, as /// in [`RpcClient::get_blocks`], where it would be invalid to use the /// [`Processed`] commitment level. These exceptions are noted in the method /// documentation. pub struct RpcClient { sender: Box<dyn RpcSender + Send + Sync + 'static>, config: RpcClientConfig, } }
The ProgramRpcClient is created in the new function of Config struct, which wraps RpcClient and provides additional features for programmatic use.
#![allow(unused)] fn main() { impl<'a> Config<'a> { pub async fn new( matches: &ArgMatches, wallet_manager: &mut Option<Rc<RemoteWalletManager>>, bulk_signers: &mut Vec<Arc<dyn Signer>>, multisigner_ids: &'a mut Vec<Pubkey>, ) -> Config<'a> { let rpc_client = Arc::new(RpcClient::new_with_timeouts_and_commitment( json_rpc_url, DEFAULT_RPC_TIMEOUT, commitment_config, DEFAULT_CONFIRM_TX_TIMEOUT, )); let program_client: Arc<dyn ProgramClient<ProgramRpcClientSendTransaction>> = if sign_only { let blockhash = matches .get_one::<Hash>(BLOCKHASH_ARG.name) .copied() .unwrap_or_default(); Arc::new(ProgramOfflineClient::new( blockhash, ProgramRpcClientSendTransaction, )) } else { Arc::new(ProgramRpcClient::new( rpc_client.clone(), ProgramRpcClientSendTransaction, )) }; } } }
Once the transaction is created and signed, it is sent to the client through the send_transaction method.
#![allow(unused)] fn main() { impl<T> Token<T> where T: SendTransaction + SimulateTransaction, { pub async fn process_ixs<S: Signers>( &self, token_instructions: &[Instruction], signing_keypairs: &S, ) -> TokenResult<T::Output> { // build the transaction let transaction = self .construct_tx(token_instructions, signing_keypairs) .await?; // submit the transaction self.client .send_transaction(&transaction) .await .map_err(TokenError::Client) } } }
Notice we initialized a ProgramRpcClient in the new function of Config struct.
#![allow(unused)] fn main() { impl<'a> Config<'a> { pub async fn new( matches: &ArgMatches, wallet_manager: &mut Option<Rc<RemoteWalletManager>>, bulk_signers: &mut Vec<Arc<dyn Signer>>, multisigner_ids: &'a mut Vec<Pubkey>, ) -> Config<'a> { // Create an RpcClient with the given parameters // This is the client that will be used to send the transaction to the network let rpc_client = Arc::new(RpcClient::new_with_timeouts_and_commitment( json_rpc_url, DEFAULT_RPC_TIMEOUT, commitment_config, DEFAULT_CONFIRM_TX_TIMEOUT, )); // Create a ProgramRpcClient with the RpcClient and the ProgramRpcClientSendTransaction instance let program_client: Arc<dyn ProgramClient<ProgramRpcClientSendTransaction>> = if sign_only { let blockhash = matches .get_one::<Hash>(BLOCKHASH_ARG.name) .copied() .unwrap_or_default(); Arc::new(ProgramOfflineClient::new( blockhash, ProgramRpcClientSendTransaction, )) } else { // Create a ProgramRpcClient with the RpcClient and the ProgramRpcClientSendTransaction instance Arc::new(ProgramRpcClient::new( rpc_client.clone(), ProgramRpcClientSendTransaction, )) }; } } }
And the ProgramRpcClient implements the ProgramClient trait. The SendTransactionRpc trait contains the send method.
#![allow(unused)] fn main() { /// Extends basic `SendTransaction` trait with function `send` where client is /// `&RpcClient`. Required for `ProgramRpcClient`. pub trait SendTransactionRpc: SendTransaction { fn send<'a>( &self, client: &'a RpcClient, transaction: &'a Transaction, ) -> BoxFuture<'a, ProgramClientResult<Self::Output>>; } }
In the implementation of ProgramRpcClient, the send_transaction method will call the send method of the SendTransactionRpc trait, as there is a trait bound ST: SendTransactionRpc in the ProgramClient trait, meaning that ST must implement the SendTransactionRpc trait, so that we can call the send method.
In other words, the send_transaction method is delegated to the send method of the SendTransactionRpc trait. Because ProgramRpcClientSendTransaction struct implements the SendTransactionRpc trait, so the send_transaction method is delegated to the send method of the ProgramRpcClientSendTransaction struct.
#![allow(unused)] fn main() { #[async_trait] impl<ST> ProgramClient<ST> for ProgramRpcClient<ST> where ST: SendTransactionRpc + SimulateTransactionRpc + Send + Sync, { // Delegate the send_transaction business logic to the send method of the // SendTransactionRpc trait // The send method is implemented in the ProgramRpcClientSendTransaction struct, // which implements the SendTransactionRpc trait async fn send_transaction(&self, transaction: &Transaction) -> ProgramClientResult<ST::Output> { self.send.send(&self.client, transaction).await } } }
Below is the definition of the ProgramRpcClientSendTransaction struct, which implements the SendTransaction trait. This struct is the instance of the generic type ST in the generic type ProgramRpcClient.
#![allow(unused)] fn main() { #[derive(Debug, Clone, Copy, Default)] pub struct ProgramRpcClientSendTransaction; #[derive(Debug, Clone, PartialEq, Eq)] pub enum RpcClientResponse { Signature(Signature), Transaction(Transaction), Simulation(RpcSimulateTransactionResult), } // Because the trait bound `ST: SendTransactionRpc + SimulateTransactionRpc + Send + Sync` is required in the `ProgramClient` trait, and SendTransactionRpc trait extends SendTransaction trait, // so the `ProgramRpcClientSendTransaction` struct implements the `SendTransaction` and `SendTransactionRpc` traits. impl SendTransaction for ProgramRpcClientSendTransaction { type Output = RpcClientResponse; } impl SendTransactionRpc for ProgramRpcClientSendTransaction { fn send<'a>( &self, client: &'a RpcClient, transaction: &'a Transaction, ) -> BoxFuture<'a, ProgramClientResult<Self::Output>> { Box::pin(async move { if !transaction.is_signed() { return Err("Cannot send transaction: not fully signed".into()); } // Notice this client is saved in the `ProgramRpcClient` struct client .send_and_confirm_transaction(transaction) .await .map(RpcClientResponse::Signature) .map_err(Into::into) }) } } }
The interesting part is that the send method of the ProgramRpcClientSendTransaction struct is implemented to call the send_and_confirm_transaction method of the RpcClient struct. This is the method that actually sends the transaction to the network.
Conclusion:
The ProgramRpcClient is a client that sends transactions to the network using the RpcClient struct. The ProgramRpcClientSendTransaction struct is the instance of the generic type ST in the generic type ProgramRpcClient. The send method of the ProgramRpcClientSendTransaction struct is implemented to call the send_and_confirm_transaction method of the RpcClient struct. This is the method that actually sends the transaction to the network.
We can create different clients in different environments, such as ProgramRpcClient for production environment, ProgramBanksClient for testing environment, and ProgramOfflineClient for offline environment. That's why we have three different clients defination in the client module.
CommandName::CreateAccount
Let's examine the CommandName::CreateAccount case. In this match arm, the code extracts several arguments from arg_matches:
token: The public key of the token to create an associated token account forowner: The public key of the owner of the associated token accountimmutable: A boolean flag indicating if the associated token account is immutablebulk_signers: A vector of signers to use for the transaction
#![allow(unused)] fn main() { pub async fn process_command<'a>( sub_command: &CommandName, sub_matches: &ArgMatches, config: &Config<'a>, mut wallet_manager: Option<Rc<RemoteWalletManager>>, mut bulk_signers: Vec<Arc<dyn Signer>>, ) -> CommandResult { match (sub_command, sub_matches) { // ... (CommandName::CreateAccount, arg_matches) => { let token = pubkey_of_signer(arg_matches, "token", &mut wallet_manager) .unwrap() .unwrap(); // No need to add a signer when creating an associated token account let account = get_signer(arg_matches, "account_keypair", &mut wallet_manager).map( |(signer, account)| { push_signer_with_dedup(signer, &mut bulk_signers); account }, ); let owner = config.pubkey_or_default(arg_matches, "owner", &mut wallet_manager)?; command_create_account( config, token, owner, account, arg_matches.is_present("immutable"), bulk_signers, ) .await } } } }
Let's look at the command_create_account function.
#![allow(unused)] fn main() { async fn command_create_account( config: &Config<'_>, token_pubkey: Pubkey, owner: Pubkey, maybe_account: Option<Pubkey>, immutable_owner: bool, bulk_signers: Vec<Arc<dyn Signer>>, ) -> CommandResult { let token = token_client_from_config(config, &token_pubkey, None)?; let mut extensions = vec![]; let (account, is_associated) = if let Some(account) = maybe_account { ( account, token.get_associated_token_address(&owner) == account, ) } else { (token.get_associated_token_address(&owner), true) }; println_display(config, format!("Creating account {}", account)); if !config.sign_only { if let Some(account_data) = config.program_client.get_account(account).await? { if account_data.owner != system_program::id() || !is_associated { return Err(format!("Error: Account already exists: {}", account).into()); } } } if immutable_owner { if config.program_id == spl_token::id() { return Err(format!( "Specified --immutable, but token program {} does not support the extension", config.program_id ) .into()); } else if is_associated { println_display( config, "Note: --immutable specified, but Token-2022 ATAs are always immutable, ignoring" .to_string(), ); } else { extensions.push(ExtensionType::ImmutableOwner); } } let res = if is_associated { println!("🌈🌈🌈 is_associated"); token.create_associated_token_account(&owner).await } else { let signer = bulk_signers .iter() .find(|signer| signer.pubkey() == account) .unwrap_or_else(|| panic!("No signer provided for account {}", account)); token .create_auxiliary_token_account_with_extension_space(&**signer, &owner, extensions) .await }?; let tx_return = finish_tx(config, &res, false).await?; Ok(match tx_return { TransactionReturnData::CliSignature(signature) => { config.output_format.formatted_string(&signature) } TransactionReturnData::CliSignOnlyData(sign_only_data) => { config.output_format.formatted_string(&sign_only_data) } }) } }
This function is the core logic of the CommandName::CreateAccount command. It creates an associated token account for the given token and owner.
The token.create_associated_token_account(&owner).await method is the method that actually creates the associated token account.
Let's look at the create_associated_token_account method of the Token struct. It is implemented as follows:
#![allow(unused)] fn main() { impl<T> Token<T> where T: SendTransaction + SimulateTransaction, { /// Create and initialize the associated account. pub async fn create_associated_token_account(&self, owner: &Pubkey) -> TokenResult<T::Output> { self.process_ixs::<[&dyn Signer; 0]>( &[create_associated_token_account( &self.payer.pubkey(), owner, &self.pubkey, &self.program_id, )], &[], ) .await } } }
It uses create_associated_token_account function to create an instruction to create an associated token account. This function will call get_associated_token_address_and_bump_seed_internal, which is an internal function to generate PDA(See Pubkey::find_program_address and Pubkey::try_find_program_address method).
#![allow(unused)] fn main() { /// Creates Create instruction pub fn create_associated_token_account( funding_address: &Pubkey, wallet_address: &Pubkey, token_mint_address: &Pubkey, token_program_id: &Pubkey, ) -> Instruction { build_associated_token_account_instruction( funding_address, wallet_address, token_mint_address, token_program_id, 0, // AssociatedTokenAccountInstruction::Create ) } fn build_associated_token_account_instruction( funding_address: &Pubkey, wallet_address: &Pubkey, token_mint_address: &Pubkey, token_program_id: &Pubkey, instruction: u8, ) -> Instruction { let associated_account_address = get_associated_token_address_with_program_id( wallet_address, token_mint_address, token_program_id, ); // safety check, assert if not a creation instruction, which is only 0 or 1 assert!(instruction <= 1); Instruction { program_id: id(), accounts: vec![ AccountMeta::new(*funding_address, true), AccountMeta::new(associated_account_address, false), AccountMeta::new_readonly(*wallet_address, false), AccountMeta::new_readonly(*token_mint_address, false), AccountMeta::new_readonly(SYSTEM_PROGRAM_ID, false), AccountMeta::new_readonly(*token_program_id, false), ], data: vec![instruction], } } /// Derives the associated token account address for the given wallet address, /// token mint and token program id pub fn get_associated_token_address_with_program_id( wallet_address: &Pubkey, token_mint_address: &Pubkey, token_program_id: &Pubkey, ) -> Pubkey { get_associated_token_address_and_bump_seed( wallet_address, token_mint_address, // NOTICE: This is the SPL Associated token program id: // ATokenGPvbdGVxr1b2hvZbsiqW5xWH25efTNsLJA8knL &crate::program::id(), token_program_id, ) .0 } /// Derives the associated token account address and bump seed /// for the given wallet address, token mint and token program id pub fn get_associated_token_address_and_bump_seed( wallet_address: &Pubkey, token_mint_address: &Pubkey, program_id: &Pubkey, token_program_id: &Pubkey, ) -> (Pubkey, u8) { get_associated_token_address_and_bump_seed_internal( wallet_address, token_mint_address, program_id, token_program_id, ) } /// For internal use only. #[doc(hidden)] pub fn get_associated_token_address_and_bump_seed_internal( wallet_address: &Pubkey, token_mint_address: &Pubkey, program_id: &Pubkey, token_program_id: &Pubkey, ) -> (Pubkey, u8) { Pubkey::find_program_address( &[ &wallet_address.to_bytes(), &token_program_id.to_bytes(), &token_mint_address.to_bytes(), ], program_id, ) } impl Pubkey { /// Find a valid [program derived address][pda] and its corresponding bump seed. /// /// [pda]: https://solana.com/docs/core/cpi#program-derived-addresses /// /// Program derived addresses (PDAs) are account keys that only the program, /// `program_id`, has the authority to sign. The address is of the same form /// as a Solana `Pubkey`, except they are ensured to not be on the ed25519 /// curve and thus have no associated private key. When performing /// cross-program invocations the program can "sign" for the key by calling /// [`invoke_signed`] and passing the same seeds used to generate the /// address, along with the calculated _bump seed_, which this function /// returns as the second tuple element. The runtime will verify that the /// program associated with this address is the caller and thus authorized /// to be the signer. #[cfg(any(target_os = "solana", feature = "curve25519"))] pub fn find_program_address(seeds: &[&[u8]], program_id: &Pubkey) -> (Pubkey, u8) { Self::try_find_program_address(seeds, program_id) .unwrap_or_else(|| panic!("Unable to find a viable program address bump seed")) } /// Find a valid [program derived address][pda] and its corresponding bump seed. /// /// [pda]: https://solana.com/docs/core/cpi#program-derived-addresses /// /// The only difference between this method and [`find_program_address`] /// is that this one returns `None` in the statistically improbable event /// that a bump seed cannot be found; or if any of `find_program_address`'s /// preconditions are violated. /// /// See the documentation for [`find_program_address`] for a full description. /// /// [`find_program_address`]: Pubkey::find_program_address // If target_os = "solana", then the function will use // syscalls which bring no dependencies. // When target_os != "solana", this should be opt-in so users // don't need the curve25519 dependency. #[cfg(any(target_os = "solana", feature = "curve25519"))] #[allow(clippy::same_item_push)] pub fn try_find_program_address(seeds: &[&[u8]], program_id: &Pubkey) -> Option<(Pubkey, u8)> { // Perform the calculation inline, calling this from within a program is // not supported #[cfg(not(target_os = "solana"))] { let mut bump_seed = [u8::MAX]; for _ in 0..u8::MAX { { let mut seeds_with_bump = seeds.to_vec(); seeds_with_bump.push(&bump_seed); match Self::create_program_address(&seeds_with_bump, program_id) { Ok(address) => return Some((address, bump_seed[0])), Err(PubkeyError::InvalidSeeds) => (), _ => break, } } bump_seed[0] -= 1; } None } // Call via a system call to perform the calculation #[cfg(target_os = "solana")] { let mut bytes = [0; 32]; let mut bump_seed = u8::MAX; let result = unsafe { crate::syscalls::sol_try_find_program_address( seeds as *const _ as *const u8, seeds.len() as u64, program_id as *const _ as *const u8, &mut bytes as *mut _ as *mut u8, &mut bump_seed as *mut _ as *mut u8, ) }; match result { SUCCESS => Some((Pubkey::from(bytes), bump_seed)), _ => None, } } } } }
Now we know an ATA is a PDA. We can verify it using PublicKey.findProgramAddress in typescript.
import {
TOKEN_PROGRAM_ID,
ASSOCIATED_TOKEN_PROGRAM_ID,
} from "@solana/spl-token";
import { PublicKey } from "@solana/web3.js";
import yargs from "yargs";
const argv = yargs
.option("account", {
alias: "a",
description: "Account address to query",
type: "string",
demandOption: true,
})
.option("token", {
alias: "t",
description: "Token address to use",
type: "string",
demandOption: true,
})
.help()
.parseSync();
//PubKey of Associated Token Program https://explorer.solana.com/address/ATokenGPvbdGVxr1b2hvZbsiqW5xWH25efTNsLJA8knL
let SPL_ASSOCIATED_TOKEN_ACCOUNT_PROGRAM_ID = ASSOCIATED_TOKEN_PROGRAM_ID,
YOUR_DEFAULT_SOL_ADDRESS = argv.account,
TOKEN_ADDRESS = argv.token;
// The rust code for the function is:
//
// /// For internal use only.
// #[doc(hidden)]
// pub fn get_associated_token_address_and_bump_seed_internal(
// wallet_address: &Pubkey,
// token_mint_address: &Pubkey,
// program_id: &Pubkey,
// token_program_id: &Pubkey,
// ) -> (Pubkey, u8) {
// Pubkey::find_program_address(
// &[
// &wallet_address.to_bytes(),
// &token_program_id.to_bytes(),
// &token_mint_address.to_bytes(),
// ],
// program_id,
// )
// }
async function findAssociatedTokenAddress(
address: string,
tokenAddress: string
) {
// NOTE: This async version is deprecated, use sync version
const result = await PublicKey.findProgramAddress(
[
// wallet address, your default Solana address to transform to Associated token address(ATA)
new PublicKey(address).toBuffer(),
// address of SPL token program: TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA
TOKEN_PROGRAM_ID.toBuffer(),
// token mint address
new PublicKey(tokenAddress).toBuffer(),
],
// address of SPL Associated Token Account program: ATokenGPvbdGVxr1b2hvZbsiqW5xWH25efTNsLJA8knL
SPL_ASSOCIATED_TOKEN_ACCOUNT_PROGRAM_ID
).then((result) => result[0]);
return result;
}
function findAssociatedTokenAddressSync(address: string, tokenAddress: string) {
const result = PublicKey.findProgramAddressSync(
[
// wallet address, your default Solana address to transform to Associated token address(ATA)
new PublicKey(address).toBuffer(),
// address of SPL token program: TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA
TOKEN_PROGRAM_ID.toBuffer(),
// token mint address
new PublicKey(tokenAddress).toBuffer(),
],
// address of SPL Associated Token Account program: ATokenGPvbdGVxr1b2hvZbsiqW5xWH25efTNsLJA8knL
SPL_ASSOCIATED_TOKEN_ACCOUNT_PROGRAM_ID
);
return result;
}
async function main() {
// const result = await findAssociatedTokenAddress(
// YOUR_DEFAULT_SOL_ADDRESS,
// TOKEN_ADDRESS
// );
// console.log(result);
const result = findAssociatedTokenAddressSync(
YOUR_DEFAULT_SOL_ADDRESS,
TOKEN_ADDRESS
);
console.log(result);
}
main();
Run get-ata.ts to generate ATA.
npx ts-node get-ata.ts -a FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH -t J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm
[
PublicKey [PublicKey(AB7baqsAgkfjwQtekTuvzT5amuM1xrRSUxRpqdnkWngJ)] {
_bn: <BN: 885072e7e485040c628343c0a78ce7297c66741518186e76b894ae7ede4f4993>
},
253
]
Notice the seeds for the ATA(PDA) is:
- Wallet address:
FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH - TOKEN PROGRAM ID:
TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA - Token mint address:
J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm
And as we're generating PDA for ATA Program, whose program id is ATokenGPvbdGVxr1b2hvZbsiqW5xWH25efTNsLJA8knL.
That's why we call findProgramAddressSync like this:
const result = PublicKey.findProgramAddressSync(
[
// wallet address, your default Solana address to transform to Associated token address(ATA)
new PublicKey(address).toBuffer(),
// address of SPL token program: TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA
TOKEN_PROGRAM_ID.toBuffer(),
// token mint address
new PublicKey(tokenAddress).toBuffer(),
],
// address of SPL Associated Token Account program: ATokenGPvbdGVxr1b2hvZbsiqW5xWH25efTNsLJA8knL
SPL_ASSOCIATED_TOKEN_ACCOUNT_PROGRAM_ID
);
Also notice beside pass TOKEN_PROGRAM_ID to findProgramAddressSync, we can also pass TokenzQdBNbLqP5VEhdkAS6EPFLC1PHnBqCXEpPxuEb to create a token 2022 associated token account. This address is also exported in constant.ts from spl-token.
import { PublicKey } from "@solana/web3.js";
/** Address of the SPL Token program */
export const TOKEN_PROGRAM_ID = new PublicKey(
"TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA"
);
/** Address of the SPL Token 2022 program */
export const TOKEN_2022_PROGRAM_ID = new PublicKey(
"TokenzQdBNbLqP5VEhdkAS6EPFLC1PHnBqCXEpPxuEb"
);
/** Address of the SPL Associated Token Account program */
export const ASSOCIATED_TOKEN_PROGRAM_ID = new PublicKey(
"ATokenGPvbdGVxr1b2hvZbsiqW5xWH25efTNsLJA8knL"
);
/** Address of the special mint for wrapped native SOL in spl-token */
export const NATIVE_MINT = new PublicKey(
"So11111111111111111111111111111111111111112"
);
/** Address of the special mint for wrapped native SOL in spl-token-2022 */
export const NATIVE_MINT_2022 = new PublicKey(
"9pan9bMn5HatX4EJdBwg9VgCa7Uz5HL8N1m5D3NdXejP"
);
/** Check that the token program provided is not `Tokenkeg...`, useful when using extensions */
export function programSupportsExtensions(programId: PublicKey): boolean {
if (programId.equals(TOKEN_PROGRAM_ID)) {
return false;
} else {
return true;
}
}
Refs
https://solana.com/docs/core/tokens#create-token-metadata
Change Token Mint Owner
Introduction
In this guide, we will learn how to change the mint authority for a token mint account using the spl-token authorize command.
Use spl-token authorize to change the mint authority for a token mint account.
# display the current mint authority for mint token
(base) dylankyc@smoltown ~/Documents/solana> spl-token display J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm
SPL Token Mint
Address: J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm
Program: TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA
Supply: 100000000000
Decimals: 9
Mint authority: FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH
Freeze authority: (not set)
# Current wallet address
(base) dylankyc@smoltown ~/Documents/solana> solana address
FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH
# Show another wallet address
(base) dylankyc@smoltown ~/Documents/solana [1]> solana address -k account-2.json
DyfxCDkNAWWmPxqmeZnA6K3bwanrPLZAofD64HXdfvYf
# Change the mint authority
(base) dylankyc@smoltown ~/Documents/solana> spl-token authorize J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm mint DyfxCDkNAWWmPxqmeZnA6K3bwanrPLZAofD64HXdfvYf
Updating J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm
Current mint: FCxBXdduz9HqTEPvEBSuFLLAjbVYh9a5ZgEnZwKyN2ZH
New mint: DyfxCDkNAWWmPxqmeZnA6K3bwanrPLZAofD64HXdfvYf
Signature: 4KHkfxTn6f6PX45iDRaEyew2EGDYbTZYyy8WcZDtD3fABFig8nVeTZGNCMo1PMtchJ9AgHaincnwVbqz4gNmxGn1
# Display the mint authority after change
# Notice the mint authority has changed to DyfxCDkNAWWmPxqmeZnA6K3bwanrPLZAofD64HXdfvYf
(base) dylankyc@smoltown ~/Documents/solana> spl-token display J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm
SPL Token Mint
Address: J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm
Program: TokenkegQfeZyiNwAJbNbGKPFXCWuBvf9Ss623VQ5DA
Supply: 100000000000
Decimals: 9
Mint authority: DyfxCDkNAWWmPxqmeZnA6K3bwanrPLZAofD64HXdfvYf
Freeze authority: (not set)
spl-token authorize help
For a full list of options, use spl-token authorize -h.
(base) dylankyc@smoltown ~/Documents/solana [1]> spl-token authorize J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm -h
spl-token-authorize
Authorize a new signing keypair to a token or token account
USAGE:
spl-token authorize [FLAGS] [OPTIONS] <TOKEN_ADDRESS> <AUTHORITY_TYPE> <AUTHORITY_ADDRESS>
FLAGS:
--disable Disable mint, freeze, or close functionality by setting authority to None.
--dump-transaction-message Display the base64 encoded binary transaction message in sign-only mode
-h, --help Prints help information
--sign-only Sign the transaction offline
-V, --version Prints version information
-v, --verbose Show additional information
OPTIONS:
--authority <KEYPAIR>
Specify the current authority keypair. Defaults to the client keypair.
--blockhash <BLOCKHASH> Use the supplied blockhash
--with-compute-unit-limit <COMPUTE-UNIT-LIMIT> Set compute unit limit for transaction, in compute units.
--with-compute-unit-price <COMPUTE-UNIT-PRICE>
Set compute unit price for transaction, in increments of 0.000001 lamports per compute unit.
-C, --config <PATH> Configuration file to use
--fee-payer <KEYPAIR>
Specify the fee-payer account. This may be a keypair file, the ASK keyword
or the pubkey of an offline signer, provided an appropriate --signer argument
is also passed. Defaults to the client keypair.
-u, --url <URL_OR_MONIKER>
URL for Solana's JSON RPC or moniker (or their first letter): [mainnet-beta, testnet, devnet, localhost]
Default from the configuration file.
--multisig-signer <MULTISIG_SIGNER>... Member signer of a multisig account
--nonce <PUBKEY>
Provide the nonce account to use when creating a nonced
transaction. Nonced transactions are useful when a transaction
requires a lengthy signing process. Learn more about nonced
transactions at https://docs.solanalabs.com/cli/examples/durable-nonce
--nonce-authority <KEYPAIR>
Provide the nonce authority keypair to use when signing a nonced transaction
--output <FORMAT>
Return information in specified output format [possible values: json, json-compact]
-p, --program-id <ADDRESS> SPL Token program id
--signer <PUBKEY=SIGNATURE>... Provide a public-key/signature pair for the transaction
ARGS:
<TOKEN_ADDRESS> The address of the token mint or account
<AUTHORITY_TYPE> The new authority type. Token mints support `mint`, `freeze`, and mint extension
authorities; Token accounts support `owner`, `close`, and account extension authorities.
[possible values: mint, freeze, owner, close, close-mint, transfer-fee-config, withheld-
withdraw, interest-rate, permanent-delegate, confidential-transfer-mint,
transfer-hook-program-id, confidential-transfer-fee, metadata-pointer, metadata, group-
pointer, group-member-pointer, group]
<AUTHORITY_ADDRESS> The address of the new authority
(base) dylankyc@smoltown ~/Documents/solana> spl-token authorize J4qKh7nmJ5a9xWY13jdyEjdYo7HoSWU5H1pRanyu3dJm owner
error: The following required arguments were not provided:
<AUTHORITY_ADDRESS>
USAGE:
spl-token authorize [FLAGS] [OPTIONS] <TOKEN_ADDRESS> <AUTHORITY_TYPE> <AUTHORITY_ADDRESS>
For more information try --help
Design Pattern for Program Clients
- Understanding Solana's Client Architecture: A Deep Dive into Rust Type System Usage
Understanding Solana's Client Architecture: A Deep Dive into Rust Type System Usage
Introduction
Solana's client architecture provides an excellent example of leveraging Rust's type system to create a flexible, type-safe, and maintainable design.
In this post, we'll explore how Solana implements different client types for various use cases while maintaining a unified interface.
The Three Client Types
The solana-program-library crate implements three main client types:
ProgramRpcClient: For production RPC interactionsProgramBanksClient: For testing and simulationProgramOfflineClient: For offline transaction signing
Let's take a look at each of these client types.
1. ProgramBanksClient
ProgramBanksClient has two fields:
context: AProgramBanksClientContextenum that can be eitherClientorContextsend: This is of generic typeST, which implements theSendTransactionBanksClientandSimulateTransactionBanksClienttraits to send transactions(seesendmethod) and simulate transactions(seesimulatemethod).
#![allow(unused)] fn main() { pub struct ProgramBanksClient<ST> { context: ProgramBanksClientContext, send: ST, } enum ProgramBanksClientContext { Client(Arc<Mutex<BanksClient>>), Context(Arc<Mutex<ProgramTestContext>>), } #[async_trait] impl<ST> ProgramClient<ST> for ProgramBanksClient<ST> where ST: SendTransactionBanksClient + SimulateTransactionBanksClient + Send + Sync, {} /// Extends basic `SendTransaction` trait with function `send` where client is /// `&mut BanksClient`. Required for `ProgramBanksClient`. pub trait SendTransactionBanksClient: SendTransaction { fn send<'a>( &self, client: &'a mut BanksClient, transaction: Transaction, ) -> BoxFuture<'a, ProgramClientResult<Self::Output>>; } /// Extends basic `SimulateTransaction` trait with function `simulation` where /// client is `&mut BanksClient`. Required for `ProgramBanksClient`. pub trait SimulateTransactionBanksClient: SimulateTransaction { fn simulate<'a>( &self, client: &'a mut BanksClient, transaction: Transaction, ) -> BoxFuture<'a, ProgramClientResult<Self::SimulationOutput>>; } /// Basic trait for sending transactions to validator. pub trait SendTransaction { type Output; } }
ProgramBanksClient is primarily used for:
- Testing Solana Programs: It enables developers to simulate and send transactions to a Solana program while running tests, allowing for verification of program behavior without the need for an actual on-chain deployment.
- Encapsulation of Client Logic: The client encapsulates the logic required to send and simulate transactions, making it easier to manage and modify as testing needs evolve.
There are two variants of ProgramBanksClientContext:
Client(Arc<Mutex<BanksClient>>): Provides streamlined access for basic transaction processing and simple unit tests. It's lightweight and ideal for single transaction validation and basic program interaction testing.Context(Arc<Mutex<ProgramTestContext>>): Offers a comprehensive testing environment with advanced features like custom genesis configuration, block management, fee payer accounts, and program deployment capabilities. This makes it suitable for integration testing, multi-transaction scenarios, and complex state management testing where full lifecycle control is needed.
According to the documentation, BanksClient is a client for the ledger state, from the perspective of an arbitrary validator. It serves as a client interface for interacting with the Solana blockchain's in-memory state during testing.
2. ProgramRpcClient
The ProgramRpcClient<ST> struct is designed to serve as a client for interacting with the Solana blockchain through the RpcClient.
#![allow(unused)] fn main() { pub struct ProgramRpcClient<ST> { client: Arc<RpcClient>, send: ST, } #[async_trait] impl<ST> ProgramClient<ST> for ProgramRpcClient<ST> where ST: SendTransactionRpc + SimulateTransactionRpc + Send + Sync, {} /// Extends basic `SendTransaction` trait with function `send` where client is /// `&RpcClient`. Required for `ProgramRpcClient`. pub trait SendTransactionRpc: SendTransaction { fn send<'a>( &self, client: &'a RpcClient, transaction: &'a Transaction, ) -> BoxFuture<'a, ProgramClientResult<Self::Output>>; } /// Extends basic `SimulateTransaction` trait with function `simulate` where /// client is `&RpcClient`. Required for `ProgramRpcClient`. pub trait SimulateTransactionRpc: SimulateTransaction { fn simulate<'a>( &self, client: &'a RpcClient, transaction: &'a Transaction, ) -> BoxFuture<'a, ProgramClientResult<Self::SimulationOutput>>; } }
- Used for regular RPC interactions with Solana nodes
- Wraps the standard
RpcClientfrom solana-client - Communicates with Solana nodes over JSON-RPC protocol
- Suitable for standard production environments
3. ProgramOfflineClient
#![allow(unused)] fn main() { pub struct ProgramOfflineClient<ST> { blockhash: Hash, _send: ST, } #[async_trait] impl<ST> ProgramClient<ST> for ProgramOfflineClient<ST> where ST: SendTransaction<Output = RpcClientResponse> + SimulateTransaction<SimulationOutput = RpcClientResponse> + Send + Sync, {} }
- Designed for offline transaction signing
- Doesn't require network connection
- Limited functionality (can't fetch accounts or rent)
- Useful for cold wallet scenarios
Type System Design
1. Unified Interface Through Traits
The ProgramClient trait serves as the foundational interface that all client implementations must adhere to, defining the core functionality for interacting with Solana programs:
#![allow(unused)] fn main() { #[async_trait] pub trait ProgramClient<ST> where ST: SendTransaction + SimulateTransaction, { async fn get_minimum_balance_for_rent_exemption(&self, data_len: usize) -> ProgramClientResult<u64>; async fn get_latest_blockhash(&self) -> ProgramClientResult<Hash>; async fn send_transaction(&self, transaction: &Transaction) -> ProgramClientResult<ST::Output>; async fn get_account(&self, address: Pubkey) -> ProgramClientResult<Option<Account>>; async fn simulate_transaction(&self, transaction: &Transaction) -> ProgramClientResult<ST::SimulationOutput>; } }
It contains 5 methods:
get_minimum_balance_for_rent_exemption: Get the minimum balance required for rent exemption.get_latest_blockhash: Get the latest blockhash.send_transaction: Send a transaction.get_account: Get an account.simulate_transaction: Simulate a transaction.
2. Transaction Handling Traits
In Solana's client architecture, there are base traits (SendTransaction and SimulateTransaction) that define what operations like sending and simulating transactions are possible.
#![allow(unused)] fn main() { /// Basic trait for sending transactions to validator. pub trait SendTransaction { type Output; } /// Basic trait for simulating transactions in a validator. pub trait SimulateTransaction { type SimulationOutput: SimulationResult; } /// Trait for the output of a simulation pub trait SimulationResult { fn get_compute_units_consumed(&self) -> ProgramClientResult<u64>; } }
However, there are different client types, i.e. Banks(ProgramBanksClient), RPC(ProgramRpcClient), Offline(ProgramOfflineClient). How do they implement these operations differently?
We can define different traits to extend the basic SendTransaction and SimulateTransaction traits and add trait bounds to the generic parameter ST of ProgramClient to ensure that the concrete type ST implements these operations differently.
Here are the extended traits:
SendTransactionBanksClient: ExtendsSendTransactionwith asendmethod that takes a&mut BanksClientand aTransaction.SimulateTransactionBanksClient: ExtendsSimulateTransactionwith asimulatemethod that takes a&mut BanksClientand aTransaction.SendTransactionRpc: ExtendsSendTransactionwith asendmethod that takes a&RpcClientand a&Transaction.SimulateTransactionRpc: ExtendsSimulateTransactionwith asimulatemethod that takes a&RpcClientand a&Transaction.
#![allow(unused)] fn main() { /// Extends basic `SendTransaction` trait with function `send` where client is /// `&RpcClient`. Required for `ProgramRpcClient`. pub trait SendTransactionRpc: SendTransaction { fn send<'a>( &self, client: &'a RpcClient, transaction: &'a Transaction, ) -> BoxFuture<'a, ProgramClientResult<Self::Output>>; } // Extends basic `SendTransaction` trait with function `send` where client is /// `&mut BanksClient`. Required for `ProgramBanksClient`. pub trait SendTransactionBanksClient: SendTransaction { fn send<'a>( &self, client: &'a mut BanksClient, transaction: Transaction, ) -> BoxFuture<'a, ProgramClientResult<Self::Output>>; } /// Extends basic `SimulateTransaction` trait with function `simulate` where /// client is `&RpcClient`. Required for `ProgramRpcClient`. pub trait SimulateTransactionRpc: SimulateTransaction { fn simulate<'a>( &self, client: &'a RpcClient, transaction: &'a Transaction, ) -> BoxFuture<'a, ProgramClientResult<Self::SimulationOutput>>; } /// Extends basic `SimulateTransaction` trait with function `simulation` where /// client is `&mut BanksClient`. Required for `ProgramBanksClient`. pub trait SimulateTransactionBanksClient: SimulateTransaction { fn simulate<'a>( &self, client: &'a mut BanksClient, transaction: Transaction, ) -> BoxFuture<'a, ProgramClientResult<Self::SimulationOutput>>; } }
So when implementing ProgramClient for ProgramRpcClient, we add trait bounds to the generic parameter ST to ensure that the concrete type ST implements the SendTransactionRpc and SimulateTransactionRpc traits.
#![allow(unused)] fn main() { impl<ST> ProgramClient<ST> for ProgramRpcClient<ST> where ST: SendTransactionRpc + SimulateTransactionRpc + Send + Sync, {} }
Similarly, when implementing ProgramClient for ProgramBanksClient, we add trait bounds to the generic parameter ST to ensure that the concrete type ST implements the SendTransactionBanksClient and SimulateTransactionBanksClient traits.
#![allow(unused)] fn main() { impl<ST> ProgramClient<ST> for ProgramBanksClient<ST> where ST: SendTransactionBanksClient + SimulateTransactionBanksClient + Send + Sync, {} }
And when implementing ProgramClient for ProgramOfflineClient, we add trait bounds to the generic parameter ST to ensure that the concrete type ST implements the SendTransaction and SimulateTransaction traits.
#![allow(unused)] fn main() { impl<ST> ProgramClient<ST> for ProgramOfflineClient<ST> where ST: SendTransaction<Output = RpcClientResponse> + SimulateTransaction<SimulationOutput = RpcClientResponse> + Send + Sync, {} }
So how to initialize these client types?
For ProgramRpcClient, we can initialize it like this:
#![allow(unused)] fn main() { let rpc_client = Arc::new(RpcClient::new("http://api.mainnet-beta.solana.com")); let program_client = ProgramRpcClient::new( rpc_client, ProgramRpcClientSendTransaction ); }
ProgramRpcClientSendTransaction is a concrete type that implements the SendTransactionRpc trait.
#![allow(unused)] fn main() { #[derive(Debug, Clone, Copy, Default)] pub struct ProgramRpcClientSendTransaction; #[derive(Debug, Clone, PartialEq, Eq)] pub enum RpcClientResponse { Signature(Signature), Transaction(Transaction), Simulation(RpcSimulateTransactionResult), } impl SendTransaction for ProgramRpcClientSendTransaction { type Output = RpcClientResponse; } impl SendTransactionRpc for ProgramRpcClientSendTransaction { fn send<'a>( &self, client: &'a RpcClient, transaction: &'a Transaction, ) -> BoxFuture<'a, ProgramClientResult<Self::Output>> { Box::pin(async move { if !transaction.is_signed() { return Err("Cannot send transaction: not fully signed".into()); } client .send_and_confirm_transaction(transaction) .await .map(RpcClientResponse::Signature) .map_err(Into::into) }) } } }
We can also define another concrete type like ProgramRpcClientSendTransactionCustom that implements both SendTransaction and SimulateTransaction traits, and use it to initialize ProgramRpcClient. This helps us to customize the send behavior of ProgramRpcClient.
In other words, when you instantiate ProgramRpcClient( ProgramBanksClient or ProgramOfflineClient), you provide a concrete type for ST that implements the required traits. The send field will then be used in methods like send_transaction and simulate_transaction to invoke the appropriate logic for handling those operations.
#![allow(unused)] fn main() { let program_client = ProgramRpcClient::new( rpc_client, ProgramRpcClientSendTransactionCustom ); }
Implementing traits for different concrete types and using them to initialize ProgramRpcClient is a good example of the strategy pattern.
Design Patterns
Now, let's take a look at the design patterns used in the ProgramClient trait.
1. Strategy Pattern
The generic parameter ST implements the strategy pattern:
#![allow(unused)] fn main() { pub struct ProgramRpcClient<ST> { client: Arc<RpcClient>, send: ST, // Strategy for sending transactions } }
2. Adapter Pattern
Each client adapts a specific underlying implementation:
#![allow(unused)] fn main() { #[async_trait] impl<ST> ProgramClient<ST> for ProgramRpcClient<ST> where ST: SendTransactionRpc + SimulateTransactionRpc + Send + Sync, { async fn send_transaction(&self, transaction: &Transaction) -> ProgramClientResult<ST::Output> { self.send.send(&self.client, transaction).await } } #[async_trait] impl<ST> ProgramClient<ST> for ProgramBanksClient<ST> where ST: SendTransactionBanksClient + SimulateTransactionBanksClient + Send + Sync, { async fn send_transaction(&self, transaction: &Transaction) -> ProgramClientResult<ST::Output> { self.run_in_lock(|client| { let transaction = transaction.clone(); self.send.send(client, transaction) }) .await } } #[async_trait] impl<ST> ProgramClient<ST> for ProgramOfflineClient<ST> where ST: SendTransaction<Output = RpcClientResponse> + SimulateTransaction<SimulationOutput = RpcClientResponse> + Send + Sync, { async fn send_transaction(&self, transaction: &Transaction) -> ProgramClientResult<ST::Output> { Ok(RpcClientResponse::Transaction(transaction.clone())) } } }
3. Composition Pattern
The design uses composition over inheritance:
#![allow(unused)] fn main() { /// Program client for `BanksClient` from crate `solana-program-test`. pub struct ProgramBanksClient<ST> { context: ProgramBanksClientContext, send: ST, } /// Program client for `RpcClient` from crate `solana-client`. pub struct ProgramRpcClient<ST> { client: Arc<RpcClient>, send: ST, } /// Program client for offline signing. pub struct ProgramOfflineClient<ST> { blockhash: Hash, _send: ST, } }
The ProgramBanksClient struct composes of a context and a send field. The context field is an enum that can be either Client or Context. The send field is a generic type ST that implements the SendTransactionBanksClient and SimulateTransactionBanksClient traits.
The ProgramRpcClient struct composes of a client and a send field. The client field is an Arc<RpcClient>. The send field is a generic type ST that implements the SendTransactionRpc and SimulateTransactionRpc traits.
The ProgramOfflineClient struct composes of a blockhash and a _send field. The blockhash field is a Hash. The _send field is a generic type ST that implements the SendTransaction and SimulateTransaction traits.
Usage Examples
Banks Client for High Performance
#![allow(unused)] fn main() { let banks_client = Arc::new(Mutex::new(BanksClient::new(...))); let program_client = ProgramBanksClient::new_from_client( banks_client, ProgramBanksClientProcessTransaction ); }
RPC Client for Standard Usage
#![allow(unused)] fn main() { let rpc_client = Arc::new(RpcClient::new("http://api.mainnet-beta.solana.com")); let program_client = ProgramRpcClient::new( rpc_client, ProgramRpcClientSendTransaction ); }
Offline Client for Cold Wallets
#![allow(unused)] fn main() { let program_client = ProgramOfflineClient::new( blockhash, ProgramOfflineTransaction ); }
Benefits of This Design
-
Type Safety
- Compile-time guarantees
- No runtime type errors
- Clear interface contracts
-
Flexibility
- Easy to add new client types
- Customizable transaction handling
- Pluggable components
-
Performance
- Zero-cost abstractions
- Direct banking stage access when needed
- RPC interface when appropriate
-
Maintainability
- Clear separation of concerns
- Modular design
- Easy to test
Conclusion
Solana's client architecture demonstrates sophisticated use of Rust's type system to:
- Support different performance requirements
- Ensure type safety and correct usage
- Allow flexibility in transaction handling
- Maintain a consistent interface across implementations
The design shows how to leverage Rust's type system to create a robust and flexible architecture that can handle different use cases while maintaining type safety and a clean interface.
Flink Socket Stream and ClickHouse Sink
Setting Up a Flink Job with ClickHouse Sink
In this blog post, we'll walk through the setup of a Flink job that utilizes a socket stream as the source and sinks the data into ClickHouse. This guide is designed to be straightforward, making it easy for you to follow along.
Introduction
Flink is a powerful stream processing framework, and ClickHouse is a fast open-source columnar database management system. Together, they can handle real-time data processing efficiently.
Flink Job Overview
The code for our Flink job is simple and easy to understand.
First, we create a StreamExecutionEnvironment and set up a socket stream that listens on port 7777.
Next, we initialize global parameters and configure ClickHouse settings, including host, username, and password. Finally, we add a ClickHouse sink to the source using the addSink method.
Here's the complete Java code for the Flink job:
public static void main(String[] args) throws Exception {
// Create execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Set up checkpointing and state backend
env.setStateBackend(new FsStateBackend("file:///tmp/ckp"));
env.enableCheckpointing(10000, CheckpointingMode.EXACTLY_ONCE);
// Initialize global parameters
Map<String, String> globalParameters = new HashMap<>();
globalParameters.put(ClickHouseClusterSettings.CLICKHOUSE_USER, "myuser");
globalParameters.put(ClickHouseClusterSettings.CLICKHOUSE_PASSWORD, "mypassword");
globalParameters.put(ClickHouseClusterSettings.CLICKHOUSE_HOSTS, "<http://127.0.0.1:8123/>");
globalParameters.put(TIMEOUT_SEC, String.valueOf(TIMEOUT_SEC));
globalParameters.put(ClickHouseSinkConst.IGNORING_CLICKHOUSE_SENDING_EXCEPTION_ENABLED, "true");
// ClickHouse cluster properties
// sink common
globalParameters.put(ClickHouseSinkConst.TIMEOUT_SEC, "1");
// globalParameters.put(ClickHouseSinkConst.FAILED_RECORDS_PATH, "/tmp/clickhouse-failed-records");
globalParameters.put(ClickHouseSinkConst.NUM_WRITERS, "2");
globalParameters.put(ClickHouseSinkConst.NUM_RETRIES, "2");
globalParameters.put(ClickHouseSinkConst.QUEUE_MAX_CAPACITY, "2");
globalParameters.put(ClickHouseSinkConst.IGNORING_CLICKHOUSE_SENDING_EXCEPTION_ENABLED, "false");
// Set global parameters
ParameterTool gParameters = ParameterTool.fromMap(globalParameters);
env.getConfig().setGlobalJobParameters(gParameters);
// Create socket stream
DataStream<String> inputStream = env.socketTextStream("localhost", 7777);
// Process the input stream
SingleOutputStreamOperator<String> dataStream = inputStream.map(new MapFunction<String, String>() {
@Override
public String map(String data) throws Exception {
String[] split = data.split(",");
User user = User.of(Integer.parseInt(split[0]), split[1], Integer.parseInt(split[2]));
return User.convertToCsv(user);
}
});
// Set up ClickHouse sink
Properties props = new Properties();
props.put(ClickHouseSinkConst.TARGET_TABLE_NAME, "default.user");
props.put(ClickHouseSinkConst.MAX_BUFFER_SIZE, "10000");
ClickHouseSink sink = new ClickHouseSink(props);
// Add sink to the data stream
dataStream.addSink(sink);
dataStream.print();
}
Building the Flink Job
To build the JAR file for our Flink job, simply run the following Maven command:
mvn package
Deploying the Job
After setting everything up, you can submit the Flink job to your local cluster. However, you might encounter an error during execution:
2022-12-01 14:20:22,595 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Source: Socket Stream -> Map -> (Sink: Unnamed, Sink: Print to Std. Out) (1/1) (63f5fb779bef06be84104994f2834919) switched from INITIALIZING to FAILED on localhost:44615-8508ab @ localhost (dataPort=45279).
java.lang.NullPointerException: null
at com.google.common.base.Preconditions.checkNotNull(Preconditions.java:787) ~[?:?]
at ru.ivi.opensource.flinkclickhousesink.model.ClickHouseSinkCommonParams.<init>(ClickHouseSinkCommonParams.java:33) ~[?:?]
at ru.ivi.opensource.flinkclickhousesink.applied.ClickHouseSinkManager.<init>(ClickHouseSinkManager.java:24) ~[?:?]
at ru.ivi.opensource.flinkclickhousesink.ClickHouseSink.open(ClickHouseSink.java:39) ~[?:?]
at org.apache.flink.api.common.functions.util.FunctionUtils.openFunction(FunctionUtils.java:34) ~[flink-dist-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.open(AbstractUdfStreamOperator.java:100) ~[flink-dist-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.api.operators.StreamSink.open(StreamSink.java:46) ~[flink-dist-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.tasks.RegularOperatorChain.initializeStateAndOpenOperators(RegularOperatorChain.java:107) ~[flink-dist-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.restoreGates(StreamTask.java:700) ~[flink-dist-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$SynchronizedStreamTaskActionExecutor.call(StreamTaskActionExecutor.java:100) ~[flink-dist-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.restoreInternal(StreamTask.java:676) ~[flink-dist-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.restore(StreamTask.java:643) ~[flink-dist-1.15.1.jar:1.15.1]
at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:948) ~[flink-dist-1.15.1.jar:1.15.1]
at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:917) ~[flink-dist-1.15.1.jar:1.15.1]
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:741) ~[flink-dist-1.15.1.jar:1.15.1]
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:563) ~[flink-dist-1.15.1.jar:1.15.1]
at java.lang.Thread.run(Thread.java:829) ~[?:?]
Oops, NPE! What's going wrong with this simple example?
After digging into the source code of flink-clickhouse-sink, particularly these files in error stack: ClickHouseSink.java ClickHouseSinkManager.java ClickHouseSinkCommonParams.java.
I noticed the error occurred because one of the global parameters was not set.
public ClickHouseSinkCommonParams(Map<String, String> params) {
Preconditions.checkNotNull(params.get(IGNORING_CLICKHOUSE_SENDING_EXCEPTION_ENABLED),
"Parameter " + IGNORING_CLICKHOUSE_SENDING_EXCEPTION_ENABLED + " must be initialized");
this.clickHouseClusterSettings = new ClickHouseClusterSettings(params);
this.numWriters = Integer.parseInt(params.get(NUM_WRITERS));
this.queueMaxCapacity = Integer.parseInt(params.get(QUEUE_MAX_CAPACITY));
this.maxRetries = Integer.parseInt(params.get(NUM_RETRIES));
this.timeout = Integer.parseInt(params.get(TIMEOUT_SEC));
this.failedRecordsPath = params.get(FAILED_RECORDS_PATH);
this.ignoringClickHouseSendingExceptionEnabled = Boolean.parseBoolean(params.get(IGNORING_CLICKHOUSE_SENDING_EXCEPTION_ENABLED));
Preconditions.checkNotNull(failedRecordsPath); // 🙋🙋🙋🙋🙋🙋🙋🙋🙋 error because of this not null check
Preconditions.checkArgument(queueMaxCapacity > 0);
Preconditions.checkArgument(numWriters > 0);
Preconditions.checkArgument(timeout > 0);
Preconditions.checkArgument(maxRetries > 0);
}
After commenting out the line with FAILED_RECORDS_PATH and setting the correct path, as follows:
globalParameters.put(ClickHouseSinkConst.FAILED_RECORDS_PATH, "/tmp/clickhouse-failed-records");
I rebuilt the jar file using the mvn clean package command, and submitted the job again. Finally, the job transitioned to the RUNNING state.
==> log/flink-dudu-taskexecutor-2-dudumac15.local.log <==
2022-12-01 14:31:46,521 INFO ru.ivi.opensource.flinkclickhousesink.applied.ClickHouseWriter [] - Building components
2022-12-01 14:31:46,525 INFO ru.ivi.opensource.flinkclickhousesink.applied.ClickHouseWriter$WriterTask [] - Start writer task, id = 0
2022-12-01 14:31:46,525 INFO ru.ivi.opensource.flinkclickhousesink.applied.ClickHouseWriter$WriterTask [] - Start writer task, id = 1
2022-12-01 14:31:46,526 INFO ru.ivi.opensource.flinkclickhousesink.applied.ClickHouseSinkScheduledCheckerAndCleaner [] - Build Sink scheduled checker, timeout (sec) = 1
2022-12-01 14:31:46,526 INFO ru.ivi.opensource.flinkclickhousesink.applied.ClickHouseSinkManager [] - Build sink writer's manager. params = ClickHouseSinkCommonParams{clickHouseClusterSettings=ClickHouseClusterSettings{hostsWithPorts=[<http://127.0.0.1:8123/>], credentials='dXNlcjE6dG9wc2VjcmV0', authorizationRequired=true, currentHostId=0}, failedRecordsPath='/tmp/clickhouse-failed-records', numWriters=2, queueMaxCapacity=2, ignoringClickHouseSendingExceptionEnabled=false, timeout=1, maxRetries=2}
2022-12-01 14:31:46,527 INFO ru.ivi.opensource.flinkclickhousesink.applied.ClickHouseSinkBuffer [] - Instance ClickHouse Sink, target table = default.user, buffer size = 10000
2022-12-01 14:31:46,529 INFO org.apache.flink.runtime.taskmanager.Task [] - Source: Socket Stream -> Map -> (Sink: Unnamed, Sink: Print to Std. Out) (1/1)#0 (1a44fb4fea1b183589b7cb60dd4cbf1e) switched from INITIALIZING to RUNNING.
==> log/flink-dudu-standalonesession-2-dudumac15.local.log <==
2022-12-01 14:31:46,532 INFO org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Source: Socket Stream -> Map -> (Sink: Unnamed, Sink: Print to Std. Out) (1/1) (1a44fb4fea1b183589b7cb60dd4cbf1e) switched from INITIALIZING to RUNNING.
==> log/flink-dudu-taskexecutor-2-dudumac15.local.log <==
2022-12-01 14:31:46,532 INFO org.apache.flink.streaming.api.functions.source.SocketTextStreamFunction [] - Connecting to server socket localhost:7777
==> log/flink-dudu-standalonesession-2-dudumac15.local.log <==
2022-12-01 14:31:49,304 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - Triggering checkpoint 1 (type=CheckpointType{name='Checkpoint', sharingFilesStrategy=FORWARD_BACKWARD}) @ 1669876309294 for job 9f280a1432d17e6cadbf92841fb89a1a.
2022-12-01 14:31:49,348 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - Completed checkpoint 1 for job 9f280a1432d17e6cadbf92841fb89a1a (0 bytes, checkpointDuration=51 ms, finalizationTime=3 ms).
==> log/flink-dudu-taskexecutor-2-dudumac15.local.out <==
(1, 'dudu', 2 )
==> log/flink-dudu-taskexecutor-2-dudumac15.local.log <==
2022-12-01 14:31:57,582 INFO ru.ivi.opensource.flinkclickhousesink.applied.ClickHouseWriter$WriterTask [] - Ready to load data to default.user, size = 1
2022-12-01 14:31:57,773 INFO ru.ivi.opensource.flinkclickhousesink.applied.ClickHouseWriter$WriterTask [] - Successful send data to ClickHouse, batch size = 1, target table = default.user, current attempt = 0
The Flink cluster log displays all processes. After it reaches the RUNNING state, it connects to socket port 7777 on localhost and triggers checkpoints periodically.
Notice that we have set Flink to read data from a socket. To accept user input, we need to run the following nc command.
nc -lk 7777
After entering some input, such as 1,tom,20, you can verify that the data has been successfully written to the ClickHouse table.
Connect to clickHouse and select all records from the user table:
SELECT *
FROM user
Query id: b94d136f-20dc-40bf-97d5-8b7243453b57
┌─id─┬─name─┬─age─┐
│ 1 │ tom │ 20 │
└────┴──────┴─────┘
Great! Flink successfully reads the data from the socket stream and sinks it to the Clickhouse sink.
Extend Disk in ClickHouse Cluster
Disk Extend Progress in ClickHouse Operator
How to Extend Disk Size in a ClickHouse Cluster and Monitor Its Progress
Managing disk resources is a crucial part of maintaining performance as your ClickHouse cluster grows over time. In this post, we'll explore how to extend the disk size when using the ClickHouse Operator. We'll walk through the configuration changes, review operator logs during the process, and even examine Kubernetes events that show how pods are recreated as part of the scaling routine.
Introduction
A common challenge when operating a ClickHouse cluster is ensuring that disk storage grows along with your data needs. In our deployment—with two shards and two replicas—we encountered a situation where the previous 800Gi disk was no longer sufficient. Fortunately, the ClickHouse Operator makes scaling simple by allowing a configuration update.
In this post, we'll explain the step-by-step process for extending disk size, from updating the cluster.yaml to monitoring the results via operator logs and Kubernetes events.
Background: Our ClickHouse Cluster Configuration
For context, here is a simplified version of our ClickHouse cluster configuration. In our deployment, the ClickHouse Operator uses a template that defines various resources, such as the data volume, pod, and service configurations:
apiVersion: "clickhouse.altinity.com/v1"
kind: "ClickHouseInstallation"
metadata:
name: "logs"
spec:
defaults:
templates:
dataVolumeClaimTemplate: data-volumeclaim-template
podTemplate: clickhouse:23.3
serviceTemplate: svc-template
configuration:
users:
# default user should be security to localhost and interhost connections
# operator creates host_regxp expression for that
# default/networks/host_regexp: \.chi-test-011-secure-user-[^.]+-\d+-\d+\.test.svc.cluster.local$
default/profile: default
default/quota: default
default/networks/ip:
- 127.0.0.1
- 127.0.0.2
# user1 with a password
user1/password: topsecret
user1/networks/ip: "::/0"
zookeeper:
nodes:
- host: zookeeper-0.zookeepers.zoo3ns
- host: zookeeper-1.zookeepers.zoo3ns
- host: zookeeper-2.zookeepers.zoo3ns
clusters:
- name: logs
layout:
shardsCount: 2
replicasCount: 2
templates:
volumeClaimTemplates:
- name: data-volumeclaim-template
# NOTE: previous name: default
#- name: default
# NOTE: aws ebs volume not deleted after the cluster is deleted
reclaimPolicy: Retain
spec:
storageClassName: ebs-sc-retain
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 800Gi
serviceTemplates:
- name: svc-template
spec:
ports:
- name: http
port: 8123
- name: tcp
port: 9000
type: ClusterIP
podTemplates:
- name: clickhouse:23.3
# NOTE: ERROR using 👇
# zone:
# values:
# - "clickhouse"
spec:
nodeSelector:
intend: monitoring
kubernetes.io/arch: arm64
containers:
- name: clickhouse-pod
image: 321321321321.dkr.ecr.cn-northwest-1.amazonaws.com.cn/clickhouse/clickhouse-server:23.3
Note: In the above configuration, the primary storage request is set to 800Gi.
Updating the Cluster Configuration
The disk extension process begins by updating the storage allocation in the cluster configuration. To extend the disk from 800Gi to 1200Gi, you simply change the storage request in the configuration file.
Below is an example diff that shows this change:
diff --git a/k8s/clickhouse/chi-logs/logs.yaml b/k8s/clickhouse/chi-logs/logs.yaml
index 7f076d8..69e5786 100644
--- a/k8s/clickhouse/chi-logs/logs.yaml
+++ b/k8s/clickhouse/chi-logs/logs.yaml
@@ -54,7 +54,7 @@ spec:
- ReadWriteOnce
resources:
requests:
- storage: 800Gi
+ storage: 1200Gi
serviceTemplates:
- name: svc-template
spec:
nodeSelector:
intend: monitoring
This small update is all it takes to tell the ClickHouse Operator to scale up the disk size.
Monitoring the Operator Logs
After applying the configuration change, the ClickHouse Operator initiates a rolling update of the pods. The operator logs provide an inside look at the progress.
Normally, all pods will be recreated during the reconcilation process.
In the one of the pod log for clickhouse-operator, we can see pod is recreating.
clickhouse-operator I1017 15:27:41.310739 1 poller.go:330] pollHostContext():clickhouse-operator/0-1-WAIT
clickhouse-operator I1017 15:27:46.311792 1 cluster.go:84] Run query on: chi-logs-logs-0-1.clickhouse-operator.svc.cluster.local of [chi-logs-logs-0-1.clickhouse-operator.svc.cluster.local]
clickhouse-operator E1017 15:29:16.866848 1 poller.go:335] pollHostContext():clickhouse-operator/0-1-TIMEOUT reached
clickhouse-operator I1017 15:29:16.874777 1 worker.go:1011] updateConfigMap():clickhouse-operator/logs/a521fecd-9ecf-4ff4-aebd-3aceaf29b31a:Update ConfigMap clickhouse-operator/chi-logs-deploy-confd-logs-0-1
clickhouse-operator I1017 15:29:16.960523 1 creator.go:542] getPodTemplate():clickhouse-operator/logs/a521fecd-9ecf-4ff4-aebd-3aceaf29b31a:statefulSet chi-logs-logs-0-1 use custom template clickhouse:23.3
clickhouse-operator I1017 15:29:16.961615 1 worker.go:1212] getStatefulSetStatus():clickhouse-operator/chi-logs-logs-0-1:cur and new StatefulSets ARE DIFFERENT based on labels. Reconcile is required for: clickhouse-operator/chi-logs-logs-0-1
clickhouse-operator I1017 15:29:16.961684 1 worker.go:1342] updateStatefulSet():Update StatefulSet(clickhouse-operator/chi-logs-logs-0-1) - started
clickhouse-operator I1017 15:29:17.706860 1 worker.go:1312] waitConfigMapPropagation():Wait for ConfigMap propagation for 9.223177994s 776.822006ms/10s
clickhouse-operator E1017 15:29:26.941945 1 creator.go:78] updateStatefulSet():StatefulSet.apps "chi-logs-logs-0-1" is invalid: spec: Forbidden: updates to statefulset spec for fields other than 'replicas', 'ordinals', 'template', 'updateStrategy', 'persistentVolumeClaimRetentionPolicy' and 'minReadySeconds' are forbidden
clickhouse-operator E1017 15:29:26.942759 1 creator.go:102] updateStatefulSet():NOT EQUAL: AP item start -------------------------
clickhouse-operator modified spec items: 21
clickhouse-operator ap item path [0]:'.Template.Spec.Containers[0].LivenessProbe.TimeoutSeconds'
clickhouse-operator ap item value[0]:'0'
clickhouse-operator ap item path [1]:'.Template.Spec.Containers[0].ReadinessProbe.TimeoutSeconds'
clickhouse-operator ap item value[1]:'0'
clickhouse-operator ap item path [2]:'.Template.Spec.Containers[0].ReadinessProbe.SuccessThreshold'
clickhouse-operator ap item value[2]:'0'
clickhouse-operator ap item path [3]:'.Template.Spec.RestartPolicy'
clickhouse-operator ap item value[3]:'""'
clickhouse-operator ap item path [4]:'.Template.Spec.DNSPolicy'
clickhouse-operator ap item value[4]:'""'
clickhouse-operator ap item path [5]:'.Template.Spec.Containers[0].Ports[0].Protocol'
clickhouse-operator ap item value[5]:'""'
clickhouse-operator ap item path [6]:'.Template.Spec.Containers[0].LivenessProbe.Handler.HTTPGet.Scheme'
clickhouse-operator ap item value[6]:'""'
clickhouse-operator ap item path [7]:'.VolumeClaimTemplates[0].ObjectMeta.Annotations'
clickhouse-operator ap item value[7]:'map[string]string{
clickhouse-operator }'
clickhouse-operator ap item path [8]:'.VolumeClaimTemplates[0].Status.Phase'
clickhouse-operator ap item value[8]:'""'
clickhouse-operator ap item path [9]:'.Template.ObjectMeta.Annotations'
clickhouse-operator ap item value[9]:'map[string]string{
clickhouse-operator }'
clickhouse-operator ap item path [10]:'.Template.Spec.Containers[0].Ports[2].Protocol'
clickhouse-operator ap item value[10]:'""'
clickhouse-operator ap item path [11]:'.Template.Spec.Containers[0].LivenessProbe.SuccessThreshold'
clickhouse-operator ap item value[11]:'0'
clickhouse-operator ap item path [12]:'.Template.Spec.Containers[0].ReadinessProbe.Handler.HTTPGet.Scheme'
clickhouse-operator ap item value[12]:'""'
clickhouse-operator ap item path [13]:'.Template.Spec.Containers[0].ReadinessProbe.FailureThreshold'
clickhouse-operator ap item value[13]:'0'
clickhouse-operator ap item path [14]:'.Template.Spec.Containers[0].TerminationMessagePath'
clickhouse-operator ap item value[14]:'""'
clickhouse-operator ap item path [15]:'.Template.Spec.Containers[0].Ports[1].Protocol'
clickhouse-operator ap item value[15]:'""'
clickhouse-operator ap item path [16]:'.Template.Spec.Containers[0].TerminationMessagePolicy'
clickhouse-operator ap item value[16]:'""'
clickhouse-operator ap item path [17]:'.Template.Spec.Containers[0].ImagePullPolicy'
clickhouse-operator ap item value[17]:'""'
clickhouse-operator ap item path [18]:'.Template.Spec.SecurityContext'
clickhouse-operator ap item value[18]:'nil'
clickhouse-operator ap item path [19]:'.Template.Spec.SchedulerName'
clickhouse-operator ap item value[19]:'""'
clickhouse-operator ap item path [20]:'.VolumeClaimTemplates[0].Spec.Resources.Requests["storage"].i.value'
clickhouse-operator ap item value[20]:'1288490188800'
clickhouse-operator AP item end -------------------------
clickhouse-operator I1017 15:29:26.942798 1 worker.go:1369] updateStatefulSet():Update StatefulSet(clickhouse-operator/chi-logs-logs-0-1) switch from Update to Recreate
clickhouse-operator E1017 15:29:27.008616 1 worker.go:1373] updateStatefulSet():Update StatefulSet(clickhouse-operator/chi-logs-logs-0-1) - failed with error
clickhouse-operator ---
clickhouse-operator StatefulSet.apps "chi-logs-logs-0-1" is invalid: spec: Forbidden: updates to statefulset spec for fields other than 'replicas', 'ordinals', 'template', 'updateStrategy', 'persistentVolumeClaimRetentionPolicy' and 'minReadySeconds' are forbidden
clickhouse-operator --
clickhouse-operator Continue with recreate
clickhouse-operator I1017 15:29:27.009393 1 deleter.go:126] deleteStatefulSet():clickhouse-operator/chi-logs-logs-0-1
clickhouse-operator I1017 15:29:32.040669 1 poller.go:224] pollStatefulSet():clickhouse-operator/chi-logs-logs-0-1:OK :ObservedGeneration:2 Replicas:1 ReadyReplicas:1 CurrentReplicas:0 UpdatedReplicas:0 CurrentRevision:chi-logs-logs-0-1-547db7557f UpdateRevision:chi-logs-logs-0-1-547db7557f
clickhouse-operator I1017 15:29:37.052566 1 poller.go:224] pollStatefulSet():clickhouse-operator/chi-logs-logs-0-1:OK :ObservedGeneration:2 Replicas:0 ReadyReplicas:0 CurrentReplicas:0 UpdatedReplicas:0 CurrentRevision:chi-logs-logs-0-1-547db7557f UpdateRevision:chi-logs-logs-0-1-547db7557f
clickhouse-operator I1017 15:29:37.065697 1 deleter.go:154] OK delete StatefulSet clickhouse-operator/chi-logs-logs-0-1
clickhouse-operator ap item value[13]:'0'
clickhouse-operator ap item path [14]:'.Template.Spec.Containers[0].TerminationMessagePath'
clickhouse-operator ap item value[14]:'""'
clickhouse-operator ap item path [15]:'.Template.Spec.Containers[0].Ports[1].Protocol'
clickhouse-operator ap item value[15]:'""'
clickhouse-operator ap item path [16]:'.Template.Spec.Containers[0].TerminationMessagePolicy'
clickhouse-operator ap item value[16]:'""'
clickhouse-operator ap item path [17]:'.Template.Spec.Containers[0].ImagePullPolicy'
clickhouse-operator ap item value[17]:'""'
clickhouse-operator ap item path [18]:'.Template.Spec.SecurityContext'
clickhouse-operator ap item value[18]:'nil'
clickhouse-operator ap item path [19]:'.Template.Spec.SchedulerName'
clickhouse-operator ap item value[19]:'""'
clickhouse-operator ap item path [20]:'.VolumeClaimTemplates[0].Spec.Resources.Requests["storage"].i.value'
clickhouse-operator ap item value[20]:'1288490188800'
clickhouse-operator AP item end -------------------------
clickhouse-operator I1017 15:29:26.942798 1 worker.go:1369] updateStatefulSet():Update StatefulSet(clickhouse-operator/chi-logs-logs-0-1) switch from Update to Recreate
clickhouse-operator E1017 15:29:27.008616 1 worker.go:1373] updateStatefulSet():Update StatefulSet(clickhouse-operator/chi-logs-logs-0-1) - failed with error
clickhouse-operator ---
clickhouse-operator StatefulSet.apps "chi-logs-logs-0-1" is invalid: spec: Forbidden: updates to statefulset spec for fields other than 'replicas', 'ordinals', 'template', 'updateStrategy', 'persistentVolumeClaimRetentionPolicy' and 'minReadySeconds' are forbidden
clickhouse-operator --
clickhouse-operator Continue with recreate
clickhouse-operator I1017 15:29:27.009393 1 deleter.go:126] deleteStatefulSet():clickhouse-operator/chi-logs-logs-0-1
clickhouse-operator I1017 15:29:32.040669 1 poller.go:224] pollStatefulSet():clickhouse-operator/chi-logs-logs-0-1:OK :ObservedGeneration:2 Replicas:1 ReadyReplicas:1 CurrentReplicas:0 UpdatedReplicas:0 CurrentRevision:chi-logs-logs-0-1-547db7557f UpdateRevision:chi-logs-logs-0-1-547db7557f
clickhouse-operator I1017 15:29:37.052566 1 poller.go:224] pollStatefulSet():clickhouse-operator/chi-logs-logs-0-1:OK :ObservedGeneration:2 Replicas:0 ReadyReplicas:0 CurrentReplicas:0 UpdatedReplicas:0 CurrentRevision:chi-logs-logs-0-1-547db7557f UpdateRevision:chi-logs-logs-0-1-547db7557f
clickhouse-operator I1017 15:29:37.065697 1 deleter.go:154] OK delete StatefulSet clickhouse-operator/chi-logs-logs-0-1
clickhouse-operator I1017 15:29:52.078823 1 poller.go:98] cache synced
clickhouse-operator I1017 15:29:52.120950 1 worker.go:1247] createStatefulSet():Create StatefulSet clickhouse-operator/chi-logs-logs-0-1 - started
clickhouse-operator I1017 15:29:52.186657 1 creator.go:35] createStatefulSet()
clickhouse-operator I1017 15:29:52.186677 1 creator.go:44] Create StatefulSet clickhouse-operator/chi-logs-logs-0-1
clickhouse-operator I1017 15:29:57.222364 1 poller.go:224] pollStatefulSet():clickhouse-operator/chi-logs-logs-0-1:OK :ObservedGeneration:1 Replicas:1 ReadyReplicas:0 CurrentReplicas:1 UpdatedReplicas:1 CurrentRevision:chi-logs-logs-0-1-547db7557f UpdateRevision:chi-logs-logs-0-1-547db7557f
clickhouse-operator I1017 15:30:02.256953 1 worker.go:324] clickhouse-operator/logs/391a2022-e3d8-44b5-ab7f-10c09f8c0e19:IPs of the CHI-1 [10.120.132.197 10.120.143.45 10.120.143.52 10.120.143.10]
clickhouse-operator I1017 15:30:02.267330 1 worker.go:328] clickhouse-operator/logs/d14bf645-d654-4e19-b377-5cc6bfcc582a:Update users IPS-1
clickhouse-operator I1017 15:30:02.279076 1 worker.go:1011] updateConfigMap():clickhouse-operator/logs/d14bf645-d654-4e19-b377-5cc6bfcc582a:Update ConfigMap clickhouse-operator/chi-logs-common-usersd
While the output is long, we can see one of the pods(clickhouse-operator/chi-logs-logs-0-1) is
deleted and recreated Successfully.
# delete
clickhouse-operator I1017 15:29:37.065697 1 deleter.go:154] OK delete StatefulSet clickhouse-operator/chi-logs-logs-0-1
# recreated
clickhouse-operator I1017 15:29:52.186677 1 creator.go:44] Create StatefulSet clickhouse-operator/chi-logs-logs-0-1
Let's see what happened in the background.
In the above snippet, the operator first attempts to update the StatefulSet but then opts for a recreate strategy by deleting the affected pod.
kubernetes pods
We can also see from k9s UI that one of the pods is recreating.
Context: arn:aws-cn:eks:cn-northwest-2:321321321321:cluster/log-cluster <0> all <a> Attach <l> Logs <y> YAML ____ __.________
Cluster: arn:aws-cn:eks:cn-northwest-1:321321321321:cluster/log-cluster <1> clickhouse-operator <ctrl-d> Delete <p> Logs Previous | |/ _/ __ \______
User: arn:aws-cn:eks:cn-northwest-1:321321321321:cluster/log-cluster <2> default <d> Describe <shift-f> Port-Forward | < \____ / ___/
K9s Rev: v0.27.4 <e> Edit <s> Shell | | \ / /\___ \
K8s Rev: v1.27.4-eks-2d98532 <?> Help <n> Show Node |____|__ \ /____//____ >
CPU: 5% <ctrl-k> Kill <f> Show PortForward \/ \/
MEM: 29%
┌───────────────────────────────────────────────────────────────────────────────── Pods(clickhouse-operator)[5] ─────────────────────────────────────────────────────────────────────────────────┐
│ NAME↑ PF READY RESTARTS STATUS CPU MEM %CPU/R %CPU/L %MEM/R %MEM/L IP NODE AGE │
│ chi-logs-logs-0-0-0 ● 0/1Δ 0 Terminating 766 1436 n/a n/a n/a n/a n/aΔ ip-10-120-130-142.cn-northwest-1.compute.internal 90m │
│ chi-logs-logs-0-1-0 ● 1/1 0 Running 823 1307 n/a n/a n/a n/a 10.120.143.45 ip-10-120-130-142.cn-northwest-1.compute.internal 10m │
│ chi-logs-logs-1-0-0 ● 1/1 0 Running 947 1404 n/a n/a n/a n/a 10.120.135.149 ip-10-120-130-142.cn-northwest-1.compute.internal 7m17s │
│ chi-logs-logs-1-1-0 ● 1/1 0 Running 766 1436 n/a n/a n/a n/a 10.120.140.217 ip-10-120-130-142.cn-northwest-1.compute.internal 90m │
│ clickhouse-operator-55959cbf5d-n5swv ● 2/2 0 Running 6 33 n/a n/a n/a n/a 10.120.152.233 ip-10-120-158-240.cn-northwest-1.compute.internal 30d │
Notice that the pod chi-logs-logs-0-0-0 is being terminated and will be recreated.
kubernetes Events
We can find some evidence of pod recreating from kubernetes events.
k get events -n clickhouse-operator -w
2m15s Normal SuccessfulDelete statefulset/chi-logs-logs-0-0 delete Pod chi-logs-logs-0-0-0 in StatefulSet chi-logs-logs-0-0 successful
110s Normal SuccessfulCreate statefulset/chi-logs-logs-0-0 create Pod chi-logs-logs-0-0-0 in StatefulSet chi-logs-logs-0-0 successful
24m Normal Killing pod/chi-logs-logs-1-0-0 Stopping container clickhouse-pod
24m Normal Scheduled pod/chi-logs-logs-1-0-0 Successfully assigned clickhouse-operator/chi-logs-logs-1-0-0 to ip-10-120-130-142.cn-northwest-1.compute.internal
From the events, we can see that the pod chi-logs-logs-0-0-0 is being terminated and recreated again.
Below is all the events of scaling disk from 800G to 1200G.
LAST SEEN TYPE REASON OBJECT MESSAGE
2m15s Normal Killing pod/chi-logs-logs-0-0-0 Stopping container clickhouse-pod
2m10s Warning Unhealthy pod/chi-logs-logs-0-0-0 Readiness probe failed: Get "http://10.120.142.251:8123/ping": dial tcp 10.120.142.251:8123: connect: connection refused
110s Normal Scheduled pod/chi-logs-logs-0-0-0 Successfully assigned clickhouse-operator/chi-logs-logs-0-0-0 to ip-10-120-130-142.cn-northwest-1.compute.internal
108s Normal SuccessfulAttachVolume pod/chi-logs-logs-0-0-0 AttachVolume.Attach succeeded for volume "pvc-54910269-0c08-4170-8c04-0aba526dcf7e"
102s Normal FileSystemResizeSuccessful pod/chi-logs-logs-0-0-0 MountVolume.NodeExpandVolume succeeded for volume "pvc-54910269-0c08-4170-8c04-0aba526dcf7e" ip-10-120-130-142.cn-northwest-1.compute.internal
101s Normal Pulled pod/chi-logs-logs-0-0-0 Container image "321321321321.dkr.ecr.cn-northwest-1.amazonaws.com.cn/clickhouse/clickhouse-server:23.3" already present on machine
101s Normal Created pod/chi-logs-logs-0-0-0 Created container clickhouse-pod
101s Normal Started pod/chi-logs-logs-0-0-0 Started container clickhouse-pod
2m15s Normal SuccessfulDelete statefulset/chi-logs-logs-0-0 delete Pod chi-logs-logs-0-0-0 in StatefulSet chi-logs-logs-0-0 successful
110s Normal SuccessfulCreate statefulset/chi-logs-logs-0-0 create Pod chi-logs-logs-0-0-0 in StatefulSet chi-logs-logs-0-0 successful
24m Normal Killing pod/chi-logs-logs-1-0-0 Stopping container clickhouse-pod
24m Normal Scheduled pod/chi-logs-logs-1-0-0 Successfully assigned clickhouse-operator/chi-logs-logs-1-0-0 to ip-10-120-130-142.cn-northwest-1.compute.internal
24m Normal Pulled pod/chi-logs-logs-1-0-0 Container image "321321321321.dkr.ecr.cn-northwest-1.amazonaws.com.cn/clickhouse/clickhouse-server:23.3" already present on machine
24m Normal Created pod/chi-logs-logs-1-0-0 Created container clickhouse-pod
24m Normal Started pod/chi-logs-logs-1-0-0 Started container clickhouse-pod
23m Normal Killing pod/chi-logs-logs-1-0-0 Stopping container clickhouse-pod
23m Normal Scheduled pod/chi-logs-logs-1-0-0 Successfully assigned clickhouse-operator/chi-logs-logs-1-0-0 to ip-10-120-130-142.cn-northwest-1.compute.internal
23m Normal Pulled pod/chi-logs-logs-1-0-0 Container image "321321321321.dkr.ecr.cn-northwest-1.amazonaws.com.cn/clickhouse/clickhouse-server:23.3" already present on machine
23m Normal Created pod/chi-logs-logs-1-0-0 Created container clickhouse-pod
23m Normal Started pod/chi-logs-logs-1-0-0 Started container clickhouse-pod
24m Normal SuccessfulCreate statefulset/chi-logs-logs-1-0 create Pod chi-logs-logs-1-0-0 in StatefulSet chi-logs-logs-1-0 successful
23m Warning RecreatingFailedPod statefulset/chi-logs-logs-1-0 StatefulSet clickhouse-operator/chi-logs-logs-1-0 is recreating failed Pod chi-logs-logs-1-0-0
23m Normal SuccessfulDelete statefulset/chi-logs-logs-1-0 delete Pod chi-logs-logs-1-0-0 in StatefulSet chi-logs-logs-1-0 successful
24m Warning FailedDelete statefulset/chi-logs-logs-1-0 delete Pod chi-logs-logs-1-0-0 in StatefulSet chi-logs-logs-1-0 failed error: pods "chi-logs-logs-1-0-0" not found
74s Info ReconcileCompleted clickhouseinstallation/logs Reconcile Host 0-0 completed
110s Info CreateStarted clickhouseinstallation/logs Create StatefulSet clickhouse-operator/chi-logs-logs-0-0 - started
65s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-usersd
72s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-usersd
2m26s Info CreateStarted clickhouseinstallation/logs Update StatefulSet(clickhouse-operator/chi-logs-logs-0-0) - started
3m33s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-configd
84s Info UpdateCompleted clickhouseinstallation/logs Update Service clickhouse-operator/chi-logs-logs-0-0
100s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-usersd
23m Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-usersd
66s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-configd
74s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-configd
3m35s Info ReconcileStarted clickhouseinstallation/logs Reconcile Host 0-0 started
3m40s Info ReconcileStarted clickhouseinstallation/logs reconcile started
24m Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-usersd
24m Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-usersd
23m Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-usersd
70s Info UpdateCompleted clickhouseinstallation/logs Update Service clickhouse-operator/clickhouse-logs
85s Info CreateCompleted clickhouseinstallation/logs Create StatefulSet clickhouse-operator/chi-logs-logs-0-0 - completed
3m32s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-usersd
72s Info ProgressHostsCompleted clickhouseinstallation/logs ProgressHostsCompleted: 1 of 4
3m36s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-usersd
83s Info CreateStarted clickhouseinstallation/logs Adding tables on shard/host:0/0 cluster:logs
68s Info ReconcileStarted clickhouseinstallation/logs Reconcile Host 0-1 started
2m26s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-deploy-confd-logs-0-0
3m37s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-configd
2m16s Info UpdateInProgress clickhouseinstallation/logs Update StatefulSet(clickhouse-operator/chi-logs-logs-0-0) switch from Update to Recreate
2m3s Normal Resizing persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-0-0 External resizer is resizing volume pvc-54910269-0c08-4170-8c04-0aba526dcf7e
2m26s Warning ExternalExpanding persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-0-0 waiting for an external controller to expand this PVC
2m16s Warning VolumeResizeFailed persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-0-0 resize volume "pvc-54910269-0c08-4170-8c04-0aba526dcf7e" by resizer "ebs.csi.aws.com" failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
2m5s Warning VolumeResizeFailed persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-0-0 resize volume "pvc-54910269-0c08-4170-8c04-0aba526dcf7e" by resizer "ebs.csi.aws.com" failed: rpc error: code = Internal desc = Could not resize volume "vol-0f696cea1221fa93f": context cancelled
2m Normal FileSystemResizeRequired persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-0-0 Require file system resize of volume on node
102s Normal FileSystemResizeSuccessful persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-0-0 MountVolume.NodeExpandVolume succeeded for volume "pvc-54910269-0c08-4170-8c04-0aba526dcf7e" ip-10-120-130-142.cn-northwest-1.compute.internal
0s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-deploy-confd-logs-0-1
0s Info CreateStarted clickhouseinstallation/logs Update StatefulSet(clickhouse-operator/chi-logs-logs-0-1) - started
0s Normal Resizing persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-1-0 External resizer is resizing volume pvc-f9842a2c-94a6-4079-956b-7e04e7df1a77
0s Warning ExternalExpanding persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-1-0 waiting for an external controller to expand this PVC
0s Info UpdateInProgress clickhouseinstallation/logs Update StatefulSet(clickhouse-operator/chi-logs-logs-0-1) switch from Update to Recreate
0s Warning VolumeResizeFailed persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-1-0 resize volume "pvc-f9842a2c-94a6-4079-956b-7e04e7df1a77" by resizer "ebs.csi.aws.com" failed: rpc error: code = Internal desc = Could not resize volume "vol-0699b47667a442b1a": context cancelled
0s Normal Resizing persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-1-0 External resizer is resizing volume pvc-f9842a2c-94a6-4079-956b-7e04e7df1a77
0s Normal Killing pod/chi-logs-logs-0-1-0 Stopping container clickhouse-pod
0s Normal SuccessfulDelete statefulset/chi-logs-logs-0-1 delete Pod chi-logs-logs-0-1-0 in StatefulSet chi-logs-logs-0-1 successful
0s Warning Unhealthy pod/chi-logs-logs-0-1-0 Readiness probe failed: Get "http://10.120.128.145:8123/ping": dial tcp 10.120.128.145:8123: connect: connection refused
0s Warning Unhealthy pod/chi-logs-logs-0-1-0 Readiness probe failed: Get "http://10.120.128.145:8123/ping": dial tcp 10.120.128.145:8123: connect: connection refused
0s Warning VolumeResizeFailed persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-1-0 resize volume "pvc-f9842a2c-94a6-4079-956b-7e04e7df1a77" by resizer "ebs.csi.aws.com" failed: rpc error: code = Internal desc = Could not resize volume "vol-0699b47667a442b1a": context cancelled
1s Normal Resizing persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-1-0 External resizer is resizing volume pvc-f9842a2c-94a6-4079-956b-7e04e7df1a77
0s Normal FileSystemResizeRequired persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-1-0 Require file system resize of volume on node
0s Info CreateStarted clickhouseinstallation/logs Create StatefulSet clickhouse-operator/chi-logs-logs-0-1 - started
0s Normal SuccessfulCreate statefulset/chi-logs-logs-0-1 create Pod chi-logs-logs-0-1-0 in StatefulSet chi-logs-logs-0-1 successful
0s Normal Scheduled pod/chi-logs-logs-0-1-0 Successfully assigned clickhouse-operator/chi-logs-logs-0-1-0 to ip-10-120-130-142.cn-northwest-1.compute.internal
0s Normal SuccessfulAttachVolume pod/chi-logs-logs-0-1-0 AttachVolume.Attach succeeded for volume "pvc-f9842a2c-94a6-4079-956b-7e04e7df1a77"
0s Normal FileSystemResizeSuccessful pod/chi-logs-logs-0-1-0 MountVolume.NodeExpandVolume succeeded for volume "pvc-f9842a2c-94a6-4079-956b-7e04e7df1a77" ip-10-120-130-142.cn-northwest-1.compute.internal
0s Normal FileSystemResizeSuccessful persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-1-0 MountVolume.NodeExpandVolume succeeded for volume "pvc-f9842a2c-94a6-4079-956b-7e04e7df1a77" ip-10-120-130-142.cn-northwest-1.compute.internal
0s Normal FileSystemResizeSuccessful pod/chi-logs-logs-0-1-0 MountVolume.NodeExpandVolume succeeded for volume "pvc-f9842a2c-94a6-4079-956b-7e04e7df1a77" ip-10-120-130-142.cn-northwest-1.compute.internal
0s Normal FileSystemResizeSuccessful persistentvolumeclaim/data-volumeclaim-template-chi-logs-logs-0-1-0 MountVolume.NodeExpandVolume succeeded for volume "pvc-f9842a2c-94a6-4079-956b-7e04e7df1a77" ip-10-120-130-142.cn-northwest-1.compute.internal
0s Normal Pulled pod/chi-logs-logs-0-1-0 Container image "321321321321.dkr.ecr.cn-northwest-1.amazonaws.com.cn/clickhouse/clickhouse-server:23.3" already present on machine
0s Normal Created pod/chi-logs-logs-0-1-0 Created container clickhouse-pod
0s Normal Started pod/chi-logs-logs-0-1-0 Started container clickhouse-pod
0s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-usersd
0s Warning Unhealthy pod/chi-logs-logs-0-1-0 Readiness probe failed: Get "http://10.120.143.45:8123/ping": dial tcp 10.120.143.45:8123: connect: connection refused
0s Warning Unhealthy pod/chi-logs-logs-0-1-0 Readiness probe failed: Get "http://10.120.143.45:8123/ping": dial tcp 10.120.143.45:8123: connect: connection refused
0s Warning Unhealthy pod/chi-logs-logs-0-1-0 Readiness probe failed: Get "http://10.120.143.45:8123/ping": dial tcp 10.120.143.45:8123: connect: connection refused
0s Warning Unhealthy pod/chi-logs-logs-0-1-0 Readiness probe failed: Get "http://10.120.143.45:8123/ping": dial tcp 10.120.143.45:8123: connect: connection refused
0s Warning Unhealthy pod/chi-logs-logs-0-1-0 Readiness probe failed: Get "http://10.120.143.45:8123/ping": dial tcp 10.120.143.45:8123: connect: connection refused
0s Warning Unhealthy pod/chi-logs-logs-0-1-0 Readiness probe failed: Get "http://10.120.143.45:8123/ping": dial tcp 10.120.143.45:8123: connect: connection refused
0s Warning Unhealthy pod/chi-logs-logs-0-1-0 Readiness probe failed: Get "http://10.120.143.45:8123/ping": dial tcp 10.120.143.45:8123: connect: connection refused
0s Warning Unhealthy pod/chi-logs-logs-0-1-0 Readiness probe failed: Get "http://10.120.143.45:8123/ping": dial tcp 10.120.143.45:8123: connect: connection refused
lk0s Warning Unhealthy pod/chi-logs-logs-0-1-0 Readiness probe failed: Get "http://10.120.143.45:8123/ping": dial tcp 10.120.143.45:8123: connect: connection refused
0s Warning Unhealthy pod/chi-logs-logs-0-1-0 Readiness probe failed: Get "http://10.120.143.45:8123/ping": dial tcp 10.120.143.45:8123: connect: connection refused
0s Warning Unhealthy pod/chi-logs-logs-0-1-0 Readiness probe failed: Get "http://10.120.143.45:8123/ping": dial tcp 10.120.143.45:8123: connect: connection refused
0s Warning Unhealthy pod/chi-logs-logs-0-1-0 Readiness probe failed: Get "http://10.120.143.45:8123/ping": dial tcp 10.120.143.45:8123: connect: connection refused
0s Info CreateCompleted clickhouseinstallation/logs Create StatefulSet clickhouse-operator/chi-logs-logs-0-1 - completed
0s Info UpdateCompleted clickhouseinstallation/logs Update Service clickhouse-operator/chi-logs-logs-0-1
0s Info CreateStarted clickhouseinstallation/logs Adding tables on shard/host:0/1 cluster:logs
0s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-configd
0s Info ReconcileCompleted clickhouseinstallation/logs Reconcile Host 0-1 completed
0s Info ProgressHostsCompleted clickhouseinstallation/logs ProgressHostsCompleted: 2 of 4
1s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-usersd
0s Info ReconcileStarted clickhouseinstallation/logs Reconcile Host 1-0 started
0s Info UpdateCompleted clickhouseinstallation/logs Update ConfigMap clickhouse-operator/chi-logs-common-configd
From the events, we can see that all the pods are rolling out.
Conclusion
In this blog post, we discussed the process of extending disk size in a ClickHouse cluster using the ClickHouse Operator. We explored the necessary configuration changes, observed the logs during the scaling process, and reviewed the Kubernetes events that indicate pod recreation. This knowledge is crucial for maintaining optimal performance in your ClickHouse deployments.
Render all chartjs charts in react typescript tailwindcss projects
In this tutorial, we'll show you how to render all chartjs charts in React project.
Table of Contents
- Define all chartjs charts
- Write a funcitonal component
- Write a chartjs wrapper
- Final Code
- Demo
- Optimize
Define all chartjs charts
We copy all chartjs official example codes and put them in component/chartjsofficial directory. We also define title and component for each example chart.
import { VerticalBarChart } from "@/component/chartjsofficial/verticalbarchart";
import { HorizontalBarChart } from "@/component/chartjsofficial/horizontalbarchart";
import { StackedBarChart } from "@/component/chartjsofficial/stackedbarchart";
import { GroupedBarChart } from "@/component/chartjsofficial/groupedbarchart";
import { AreaChart } from "@/component/chartjsofficial/areachart";
import { LineChart } from "@/component/chartjsofficial/linechart";
import { MultiAxisLineChart } from "@/component/chartjsofficial/multiaxislinechart";
import { PieChart } from "@/component/chartjsofficial/piechart";
import { DoughnutChart } from "@/component/chartjsofficial/doughnutchart";
import { PolarAreaChart } from "@/component/chartjsofficial/polarareachart";
import { RadarChart } from "@/component/chartjsofficial/radarchart";
import { ScatterChart } from "@/component/chartjsofficial/scatterchart";
import { BubbleChart } from "@/component/chartjsofficial/bubblechart";
import { MultiTypeChart } from "@/component/chartjsofficial/multitypechart";
import { ChartEvents } from "@/component/chartjsofficial/chartevents";
import { ChartRef } from "@/component/chartjsofficial/chartref";
import { GradientChart } from "@/component/chartjsofficial/gradientchart";
import { ChartEventsSingleDataset } from "@/component/chartjsofficial/charteventssingledataset";
import { ChartEventsSingleDatasetOutsideDatasource } from "@/component/chartjsofficial/charteventssingledatasetoutsidedatasource";
const components = [
{
title: "VerticalBarChart",
component: VerticalBarChart,
},
{
title: "HorizontalBarChart",
component: HorizontalBarChart,
},
{
title: "StackedBarChart",
component: StackedBarChart,
},
{
title: "GroupedBarChart",
component: GroupedBarChart,
},
{
title: "AreaChart",
component: AreaChart,
},
{
title: "LineChart",
component: LineChart,
},
{
title: "MultiAxisLineChart",
component: MultiAxisLineChart,
},
{
title: "DoughnutChart",
component: DoughnutChart,
},
{
title: "PolarAreaChart",
component: PolarAreaChart,
},
{
title: "RadarChart",
component: RadarChart,
},
{
title: "ScatterChart",
component: ScatterChart,
},
{
title: "BubbleChart",
component: BubbleChart,
},
{
title: "ScatterChart",
component: ScatterChart,
},
{
title: "MultiTypeChart",
component: MultiTypeChart,
},
{
title: "ChartEvents",
component: ChartEvents,
},
{
title: "ChartRef",
component: ChartRef,
},
{
title: "GradientChart",
component: GradientChart,
},
{
title: "ChartEventsSingleDataset",
component: ChartEventsSingleDataset,
},
];
Write a funcitonal component
In order to render all components, we write a functional component to take array of component with title and render them in one place.
type Component = {
title: string,
component: React.FunctionComponent,
};
type ChartProps = {
components: Component[],
};
const ComponentWrapper: React.FC<ChartProps> = ({ components }) => {
return (
<div>
{components.map((component, index) => {
return (
<ChartWrapper key={index} title={component.title}>
<component.component />
</ChartWrapper>
);
})}
</div>
);
};
Write a chartjs wrapper
In order to add title for each chart, we write a functional component to wrapper up every chart with a h1. Note we define the h1 style using tailwindcss, setting div size(h-96) and text size(text-3xl), etc.
export const ChartWrapper: React.FC<{
title: string,
children: React.ReactNode,
}> = ({ title, children }) => {
return (
<div className="max-h-96 h-96 bg-slate-50 border border-dashed">
<h1 className="text-3xl text-center font-bold underline">{title}</h1>
{children}
</div>
);
};
Final Code
First, import all chartjs components and define components to render.
import { VerticalBarChart } from "@/component/chartjsofficial/verticalbarchart";
import { HorizontalBarChart } from "@/component/chartjsofficial/horizontalbarchart";
import { StackedBarChart } from "@/component/chartjsofficial/stackedbarchart";
import { GroupedBarChart } from "@/component/chartjsofficial/groupedbarchart";
import { AreaChart } from "@/component/chartjsofficial/areachart";
import { LineChart } from "@/component/chartjsofficial/linechart";
import { MultiAxisLineChart } from "@/component/chartjsofficial/multiaxislinechart";
import { PieChart } from "@/component/chartjsofficial/piechart";
import { DoughnutChart } from "@/component/chartjsofficial/doughnutchart";
import { PolarAreaChart } from "@/component/chartjsofficial/polarareachart";
import { RadarChart } from "@/component/chartjsofficial/radarchart";
import { ScatterChart } from "@/component/chartjsofficial/scatterchart";
import { BubbleChart } from "@/component/chartjsofficial/bubblechart";
import { MultiTypeChart } from "@/component/chartjsofficial/multitypechart";
import { ChartEvents } from "@/component/chartjsofficial/chartevents";
import { ChartRef } from "@/component/chartjsofficial/chartref";
import { GradientChart } from "@/component/chartjsofficial/gradientchart";
import { ChartEventsSingleDataset } from "@/component/chartjsofficial/charteventssingledataset";
import { ChartEventsSingleDatasetOutsideDatasource } from "@/component/chartjsofficial/charteventssingledatasetoutsidedatasource";
const components = [
{
title: "VerticalBarChart",
component: VerticalBarChart,
},
{
title: "HorizontalBarChart",
component: HorizontalBarChart,
},
{
title: "StackedBarChart",
component: StackedBarChart,
},
{
title: "GroupedBarChart",
component: GroupedBarChart,
},
{
title: "AreaChart",
component: AreaChart,
},
{
title: "LineChart",
component: LineChart,
},
{
title: "MultiAxisLineChart",
component: MultiAxisLineChart,
},
{
title: "DoughnutChart",
component: DoughnutChart,
},
{
title: "PolarAreaChart",
component: PolarAreaChart,
},
{
title: "RadarChart",
component: RadarChart,
},
{
title: "ScatterChart",
component: ScatterChart,
},
{
title: "BubbleChart",
component: BubbleChart,
},
{
title: "ScatterChart",
component: ScatterChart,
},
{
title: "MultiTypeChart",
component: MultiTypeChart,
},
{
title: "ChartEvents",
component: ChartEvents,
},
{
title: "ChartRef",
component: ChartRef,
},
{
title: "GradientChart",
component: GradientChart,
},
{
title: "ChartEventsSingleDataset",
component: ChartEventsSingleDataset,
},
];
Next, write a function called ChartWrapper to wrapper up react chartjs chart components with a h1 as the title.
export const ChartWrapper: React.FC<{
title: string,
children: React.ReactNode,
}> = ({ title, children }) => {
return (
<div className="max-h-96 h-96 bg-slate-50 border border-dashed">
<h1 className="text-3xl text-center font-bold underline">{title}</h1>
{children}
</div>
);
};
Then, write a functional component to take a arrays of components and render them use ChartWrapper component.
type Component = {
title: string,
component: React.FunctionComponent,
};
type ChartProps = {
components: Component[],
};
const ComponentWrapper: React.FC<ChartProps> = ({ components }) => {
return (
<div>
{components.map((component, index) => {
return (
<ChartWrapper key={index} title={component.title}>
<component.component />
</ChartWrapper>
);
})}
</div>
);
};
Finally, in App component, we iterate the components and render them in a div with grid class.
export default function App() {
return (
<div>
<Head>
<title>ChartJS + NextJS + TailwindCSS</title>
<meta name="description" content="Generated by create next app" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<link rel="icon" href="/favicon.ico" />
</Head>
<main className={styles.main}>
<div className={styles.description}>
<h1 className="text-3xl text-center font-bold underline">
ChartJS + NextJS + TailwindCSS
</h1>
<div className="container columns-2">
<div className="grid grid-cols-2 md:grid-cols-1 gap-0">
{<ComponentWrapper components={components} />}
</div>
</div>
</div>
</main>
</div>
);
}
Demo

Optimize
Note, for ComponentWrapper function component, it's more verbose. We could write it in another way.
Here is the old way.
// NOTE: OK but verbose
const ComponentWrapper: React.FC<ChartProps> = ({ components }) => {
return (
<div>
{components.map((c, index) => {
return (
<ChartWrapper key={index} title={c.title}>
<c.component />
</ChartWrapper>
);
})}
</div>
);
};
The new way:
// NOTE: concise
const ComponentWrapperChatGPTAgain: React.FC<ChartProps> = ({ components }) => {
return (
<div>
{components.map((c, index) => {
const { title, component: C } = c;
return (
<ChartWrapper key={index} title={title}>
<C />
</ChartWrapper>
);
})}
</div>
);
};
To render list of charts components with titles and properties, we wrote two React component functions. While both functions produce the same output, their implementation approaches are different.
The first function ComponentWrapper is a good method, but the downside is that it is quite verbose. It uses curly braces and a return statement to wrap the component inside <ChartWrapper>, and it also references c.title and c.component multiple times within the function body.
The second function ComponentWrapperChatGPTAgain is a more concise implementation. It uses ES6 destructuring syntax to get title and component from the components object, which avoids repeated use of c.title and c.component. Additionally, it uses a more descriptive variable name C for the component.
Clearly, the second implementation is more succinct, easier to read and maintain, and also makes it easier to add new properties or methods. Therefore, we recommend using the second function ComponentWrapperChatGPTAgain as a more efficient programming practice.
To summarize, the primary difference between these two implementation methods is that the first one is verbose, which makes it difficult to read and maintain, while the second one is more concise and easier to read and maintain. The second function also uses destructuring, which is a useful syntax for improving readability by eliminating repetition. By using a more concise and readable implementation, you can streamline your code and make it more efficient.
chatgpt says
Comparing Two React Component Functions
In this post, we will compare and contrast two React component functions that are used to render a list of chart components with titles and properties. While both functions ultimately produce the same result, their implementation approaches are different.
Function 1: ComponentWrapper
const ComponentWrapper: React.FC<ChartProps> = ({ components }) => {
return (
<div>
{components.map((c, index) => {
return (
<ChartWrapper key={index} title={c.title}>
<c.component />
</ChartWrapper>
);
})}
</div>
);
};
This function is a good approach, but it is quite verbose. It uses curly braces and a return statement to wrap the component inside <ChartWrapper>, and it also references c.title and c.component multiple times within the function body. It might be a bit difficult to read and maintain for developers, especially with more complex components.
Function 2: ComponentWrapperChatGPTAgain
const ComponentWrapperChatGPTAgain: React.FC<ChartProps> = ({ components }) => {
return (
<div>
{components.map((c, index) => {
const { title, component: C } = c;
return (
<ChartWrapper key={index} title={title}>
<C />
</ChartWrapper>
);
})}
</div>
);
};
This function, on the other hand, is a more concise implementation. It uses ES6 destructuring syntax to get title and component from the components object, which avoids repeated use of c.title and c.component. Additionally, it uses a more descriptive variable name C for the component.
The second implementation is more succinct, easier to read and maintain, and also makes it easier to add new properties or methods in the future. Therefore, we recommend using the second function ComponentWrapperChatGPTAgain as a more efficient programming practice.
Conclusion
The primary difference between these two implementation methods is that the first one is verbose, which makes it difficult to read and maintain, while the second one is more concise and easier to read and maintain. The second function also uses destructuring, which is a useful syntax for improving readability by eliminating repetition. By using a concise, readable implementation, code can be streamlined and more efficient.
Setup React Query in NextJS Project
- Introduction
- Install
- Use react-query in nextjs project
- Write your component
- JSONTable - A component to render data as a table
Introduction
In the modern web development landscape, efficiently managing and handling data is a crucial aspect that can dramatically impact the user experience. React Query is a powerful data synchronization and state management library that aims to simplify fetching, caching, background updates and server state management in your React applications.
Next.js is a popular React framework that enables features such as Server-Side Rendering and Static Site Generation out of the box. This makes it a great choice for building performant, SEO-friendly web applications. However, when it comes to data fetching and managing server state, Next.js leaves the choice up to the developer.
Therefore, using React Query with Next.js can be a powerful combination for building robust, data-driven applications with improved user experience. This blog post will guide you step by step to integrating React Query in a Next.js project.
We will cover:
- Setting up a new Next.js project
- Installing and setting up React Query
- Fetching data using React Query
- Displaying the fetched data using a table component
No matter the size and scale of your application, using React Query with Next.js can improve the efficiency of your data operations and the overall quality of your product. Let's dive in!
Install
To install react-query, you can use yarn or npm:
yarn add react-query
This will install react-query ("react-query": "^3.39.3") as a dependency in your project. See package.json for more details.
{
"name": "mui-5-example",
"version": "0.1.0",
"private": true,
"scripts": {
"dev": "next dev",
"build": "next build",
"start": "next start",
"lint": "next lint"
},
"dependencies": {
"@emotion/react": "^11.11.1",
"@emotion/styled": "^11.11.0",
"@mui/base": "^5.0.0-beta.16",
"@mui/icons-material": "^5.11.11",
"@mui/material": "^5.14.9",
"@mui/styles": "^5.11.13",
"@mui/system": "^5.14.9",
"@mui/utils": "^5.14.9",
"@mui/x-data-grid": "^6.14.0",
"@mui/x-data-grid-generator": "^6.14.0",
"@mui/x-data-grid-pro": "^6.14.0",
"@types/node": "18.15.11",
"@types/react": "18.0.31",
"@types/react-dom": "18.0.11",
"@visx/group": "^3.3.0",
"@visx/mock-data": "^3.3.0",
"@visx/responsive": "^3.3.0",
"@visx/scale": "^3.5.0",
"@visx/shape": "^3.5.0",
"@visx/text": "^3.3.0",
"@visx/wordcloud": "^3.3.0",
"eslint": "8.37.0",
"eslint-config-next": "13.2.4",
"expression-eval": "^5.0.1",
"moment-timezone": "^0.5.44",
"next": "13.2.4",
"qs": "^6.11.2",
"react": "18.2.0",
"react-dom": "18.2.0",
"react-query": "^3.39.3",
"recharts": "^2.5.0",
"typescript": "5.0.3"
},
"devDependencies": {
"@tanstack/eslint-plugin-query": "^5.20.1"
}
}
Use react-query in nextjs project
After installation, you can use it in nextjs project by adding the following code in _app.tsx:
import "@/styles/globals.css";
import type { AppProps } from "next/app";
import { QueryClient, QueryClientProvider } from "react-query";
export default function App({ Component, pageProps }: AppProps) {
// NOTE: This is old way of, no QueryClientProvider is used
// return <Component {...pageProps} />
// NOTE: This is new way of, using QueryClientProvider
// return (<QueryClientProvider client={queryClient}>
// <Component {...pageProps} />
// </QueryClientProvider>)
// Create a QueryClient instance
const queryClient = new QueryClient();
return (
// Use QueryClientProvider to wrapper the app component with the query client
<QueryClientProvider client={queryClient}>
<Component {...pageProps} />
</QueryClientProvider>
);
}
Diff:
diff --git a/a.tsx b/a.tsx
index 9a16b79..20d285a 100644
--- a/a.tsx
+++ b/a.tsx
@@ -1,6 +1,15 @@
import "@/styles/globals.css";
import type { AppProps } from "next/app";
+import { QueryClient, QueryClientProvider } from "react-query";
export default function App({ Component, pageProps }: AppProps) {
- return <Component {...pageProps} />
+ // Create a QueryClient instance
+ const queryClient = new QueryClient();
+
+ return (
+ // Use QueryClientProvider to wrapper the app component with the query client
+ <QueryClientProvider client={queryClient}>
+ <Component {...pageProps} />
+ </QueryClientProvider>
+ );
}
Write your component
Now, we can write our component to use the useQuery hook.
The useQuery hook is a higher-order component that returns a QueryClient instance.
import React from "react";
import { useQuery } from "react-query";
// import {
// QueryClient,
// QueryClientProvider,
// useQuery,
// } from "@tanstack/react-query";
import type { InferGetServerSidePropsType, GetServerSideProps } from "next";
import JSONTable from "../components/table/JSONTable";
// Function to fetch data
const fetchData = async () => {
const response = await fetch("https://api.github.com/repos/vercel/next.js");
if (!response.ok) {
throw new Error("Network response was not ok");
}
return response.json();
};
function DataFetchUsingReactQuery() {
// Using the useQuery hook to fetch data
const { data, error, isLoading } = useQuery("fetchData", fetchData);
if (isLoading) {
return <p>Loading...</p>;
}
if (error) {
return <p>Error: {error.message}</p>;
}
return (
<div>
<h1>Data from API:</h1>
<JSONTable data={data} />
</div>
);
}
export default DataFetchUsingReactQuery;
JSONTable - A component to render data as a table
As we use MUI to render the table, we write a JSONTable component , which takes a data prop and renders the data as a table.
The code is pretty simple, but we need to import the Table and TableHead components from @mui/material.
import React from "react";
import {
Table,
TableHead,
TableBody,
TableRow,
TableCell,
TableContainer,
Paper,
} from "@mui/material";
const JSONTable = ({ data }) => {
const renderTableRows = () => {
return Object.entries(data).map(([key, value]) => (
<TableRow key={key}>
<TableCell sx={{ wordBreak: "break-word", maxWidth: 20 }}>
{key}
</TableCell>
<TableCell sx={{ wordBreak: "break-word", maxWidth: 800 }}>
{/* // NOTE: when value is boolean, we should call toString to change it
to string instead of JSON.stringify */}
{typeof value === "object"
? JSON.stringify(value)
: typeof value === "boolean"
? value.toString()
: value}
{/* {typeof value === "object" ? JSON.stringify(value) : value} */}
{/* {JSON.stringify(value)} */}
{/* {typeof value} */}
</TableCell>
</TableRow>
));
};
return (
<TableContainer
component={Paper}
style={{ margin: "20px", marginRight: "40px" }}
>
<Table sx={{ minWidth: 650 }} aria-label="simple table">
<TableHead>
<TableRow>
<TableCell>Property</TableCell>
<TableCell>Value</TableCell>
</TableRow>
</TableHead>
<TableBody>{renderTableRows()}</TableBody>
</Table>
</TableContainer>
);
};
export default JSONTable;
Setup Tanstack React Query in NextJS Project
- Introduction
- Install
- Use tanstack/react-query in nextjs project
- Write your component
- JSONTable - A component to render data as a table
Introduction
In the modern web development landscape, efficiently managing and handling data is a crucial aspect that can dramatically impact the user experience. React Query is a powerful data synchronization and state management library that aims to simplify fetching, caching, background updates and server state management in your React applications.
Next.js is a popular React framework that enables features such as Server-Side Rendering and Static Site Generation out of the box. This makes it a great choice for building performant, SEO-friendly web applications. However, when it comes to data fetching and managing server state, Next.js leaves the choice up to the developer.
Therefore, using React Query with Next.js can be a powerful combination for building robust, data-driven applications with improved user experience. This blog post will guide you step by step to integrating React Query in a Next.js project.
We will cover:
- Setting up a new Next.js project
- Installing and setting up React Query
- Fetching data using React Query
- Displaying the fetched data using a table component
No matter the size and scale of your application, using React Query with Next.js can improve the efficiency of your data operations and the overall quality of your product. Let's dive in!
Install
To install tanstack/react-query, you can use yarn or npm:
yarn add @tanstack/react-query
yarn add -D @tanstack/eslint-plugin-query
This will install tanstack/react-query ("@tanstack/react-query": "^5.21.7") as a dependency in your project. See package.json for more details.
{
"name": "mui-5-example",
"version": "0.1.0",
"private": true,
"scripts": {
"dev": "next dev",
"build": "next build",
"start": "next start",
"lint": "next lint"
},
"dependencies": {
"@emotion/react": "^11.11.1",
"@emotion/styled": "^11.11.0",
"@mui/base": "^5.0.0-beta.16",
"@mui/icons-material": "^5.11.11",
"@mui/material": "^5.14.9",
"@mui/styles": "^5.11.13",
"@mui/system": "^5.14.9",
"@mui/utils": "^5.14.9",
"@mui/x-data-grid": "^6.14.0",
"@mui/x-data-grid-generator": "^6.14.0",
"@mui/x-data-grid-pro": "^6.14.0",
"@tanstack/react-query": "^5.21.7",
"@types/node": "18.15.11",
"@types/react": "18.0.31",
"@types/react-dom": "18.0.11",
"@visx/group": "^3.3.0",
"@visx/mock-data": "^3.3.0",
"@visx/responsive": "^3.3.0",
"@visx/scale": "^3.5.0",
"@visx/shape": "^3.5.0",
"@visx/text": "^3.3.0",
"@visx/wordcloud": "^3.3.0",
"eslint": "8.37.0",
"eslint-config-next": "13.2.4",
"expression-eval": "^5.0.1",
"moment-timezone": "^0.5.44",
"next": "13.2.4",
"qs": "^6.11.2",
"react": "18.2.0",
"react-dom": "18.2.0",
"react-query": "^3.39.3",
"recharts": "^2.5.0",
"typescript": "5.0.3"
},
"devDependencies": {
"@tanstack/eslint-plugin-query": "^5.20.1"
}
}
Use tanstack/react-query in nextjs project
After installation, you can use it in nextjs project by adding the following code in _app.tsx:
import React from "react";
import "@/styles/globals.css";
import type { AppProps } from "next/app";
// import { QueryClient, QueryClientProvider } from "react-query";
import {
Hydrate,
QueryClient,
QueryClientProvider,
} from "@tanstack/react-query";
// NOTE: Default code
// export default function App({ Component, pageProps }: AppProps) {
// return <Component {...pageProps} />
// }
// NOTE: Using react-query v3, for v4+, use tanstack/react-query
// export default function App({ Component, pageProps }: AppProps) {
// // Create a QueryClient instance
// const queryClient = new QueryClient();
// return (
// // Use QueryClientProvider to wrapper your application,and pass the queryClient to the component
// <QueryClientProvider client={queryClient}>
// <Component {...pageProps} />
// </QueryClientProvider>
// );
// }
export default function App({ Component, pageProps }: AppProps) {
// Create a QueryClient instance
const [queryClient] = React.useState(() => new QueryClient());
return (
<QueryClientProvider client={queryClient}>
{/* <Hydrate state={pageProps.dehydratedState}> */}
<Component {...pageProps} />
{/* </Hydrate> */}
</QueryClientProvider>
);
}
Write your component
Now, we can write our component to use the useQuery hook.
The useQuery hook is a higher-order component that returns a QueryClient instance.
import React from "react";
// import { useQuery } from "react-query";
import { useQuery } from "@tanstack/react-query";
import type { InferGetServerSidePropsType, GetServerSideProps } from "next";
import JSONTable from "../../components/table/JSONTable";
type Repo = {
name: string;
stargazers_count: number;
};
// Function to fetch data
const fetchData = async () => {
const response = await fetch("https://api.github.com/repos/vercel/next.js");
if (!response.ok) {
throw new Error("Network response was not ok");
}
return response.json();
};
function DataFetchUsingTanstackReactQuery() {
// Using the useQuery hook to fetch data
// const { data, error, isLoading } = useQuery("fetchData", fetchData);
const { data, error, isLoading } = useQuery({
queryKey: ["fetchData"],
queryFn: fetchData,
});
if (isLoading) {
return <p>Loading...</p>;
}
if (error) {
return <p>Error: {error.message}</p>;
}
return (
<div>
<h1>Data from API:</h1>
<JSONTable data={data} />
</div>
);
}
export default DataFetchUsingTanstackReactQuery;
Starting with version 4 of @tanstack/react-query, there was a breaking change in how queries and mutations are called. Before version 4, it was possible to use the "array" syntax or the "object" syntax when calling query functions. After version 4, only the "object" form is allowed.
// Older version:
// const { data, error, isLoading } = useQuery("fetchData", fetchData);
// New version:
const { data, error, isLoading } = useQuery({
queryKey: ["fetchData"],
queryFn: fetchData,
});
Below is the difference between older and newer versions of @tanstack/react-query.
- useQuery(key, fn, options)
+ useQuery({ queryKey, queryFn, ...options })
- useInfiniteQuery(key, fn, options)
+ useInfiniteQuery({ queryKey, queryFn, ...options })
- useMutation(fn, options)
+ useMutation({ mutationFn, ...options })
- useIsFetching(key, filters)
+ useIsFetching({ queryKey, ...filters })
- useIsMutating(key, filters)
+ useIsMutating({ mutationKey, ...filters })
JSONTable - A component to render data as a table
As we use MUI to render the table, we write a JSONTable component , which takes a data prop and renders the data as a table.
The code is pretty simple, but we need to import the Table and TableHead components from @mui/material.
import React from "react";
import {
Table,
TableHead,
TableBody,
TableRow,
TableCell,
TableContainer,
Paper,
} from "@mui/material";
const JSONTable = ({ data }) => {
const renderTableRows = () => {
return Object.entries(data).map(([key, value]) => (
<TableRow key={key}>
<TableCell sx={{ wordBreak: "break-word", maxWidth: 20 }}>
{key}
</TableCell>
<TableCell sx={{ wordBreak: "break-word", maxWidth: 800 }}>
{/* // NOTE: when value is boolean, we should call toString to change it
to string instead of JSON.stringify */}
{typeof value === "object"
? JSON.stringify(value)
: typeof value === "boolean"
? value.toString()
: value}
{/* {typeof value === "object" ? JSON.stringify(value) : value} */}
{/* {JSON.stringify(value)} */}
{/* {typeof value} */}
</TableCell>
</TableRow>
));
};
return (
<TableContainer
component={Paper}
style={{ margin: "20px", marginRight: "40px" }}
>
<Table sx={{ minWidth: 650 }} aria-label="simple table">
<TableHead>
<TableRow>
<TableCell>Property</TableCell>
<TableCell>Value</TableCell>
</TableRow>
</TableHead>
<TableBody>{renderTableRows()}</TableBody>
</Table>
</TableContainer>
);
};
export default JSONTable;
Redux Typescript 大型软件实践
Intro
大多数程序员都将类型安全理解为编程语言的一个特性,TypeScript 作为 JavaScript 的超集,它可以更严格地执行类型检查。
我们拿一个螃蟹 🦀️ 举例,我们知道它只能向左走或向右走,于是我们定义它的方向:
type Direction = "left" | "right";
然后定义它的类:
class Crab {
name: string;
constructor(name: string) {
this.name = name;
}
move(direction: Direction, distanceInMeters: number = 0) {
console.log(`${this.name} moved ${distanceInMeters} m.`);
}
}
然后我们去了夏威夷,抓了一只小螃蟹:
const crab = new Crab("a just catched crab from Hawaii");
让它向前走:
crab.move("forward", 20);
于是出错了!
error TS2345: Argument of type '"forward"' is not assignable to parameter of type 'Direction'.
14 crab.move("forward", 20);
~~~~~~~~~
这个出错是什么意思呢?它告诉我们 forward 不可以赋值给类型是 Direction 的参数,到这里我们知道类型检查开始工作了。

我们只能让我们的小螃蟹向左或向右走:
crab.move("left", 20);
crab.move("right", 20);
针对 Direction 类型,我们还可以用模式匹配来进行类型检查。
假设我们的左岸是大海,右岸是陆地,而我们的螃蟹智商极高,当它移动时,它知道食物在海里,从而远离陆地。
vscode 会提示我们,只能向左走向右走,其他方向时不允许的

当我们谈到 pattern matching 时,是真的要讲 一只螃蟹向左走向右走 的问题吗?
Either Type
为什么要使用 Either Type?
Either Type 算是一种容器,它可以存储两种类型:A 和 B,这里是 Left 和 Right,一种表示失败,一种表示成功。
学过 Rust 的人都知道,Rust 有个 Result 类型:
#![allow(unused)] fn main() { pub enum Result<T, E> { /// Contains the success value Ok(T), /// Contains the error value Err(E), } }
它在 pattern match 的时候很有用,出错处理几乎离不开它:
#![allow(unused)] fn main() { fn halves_if_even(i: i32) -> Result<i32, Error> { if i % 2 == 0 { Ok(i/2) } else { Err(/* something */) } } fn do_the_thing(i: i32) -> Result<i32, Error> { let i = match halves_if_even(i) { Ok(i) => i, e => return e, }; // use `i` } }
我们可以效仿 Rust 实现 TypeScript 的 match on Either
我们使用 union type 来定义 Either
type Left<T> = { type: "left"; value: T };
type Right<T> = { type: "right"; value: T };
type Either<L, R> = Left<L> | Right<R>;
Either 定义了一个容器,实际编码中,我们需要从 Either 容器里提取结果,为了调用者的方便,我们允许传入 callback 来处理不同的情况
function match<T, L, R>(
input: Either<L, R>,
left: (left: L) => T,
right: (right: R) => T
) {
switch (input.type) {
case "left":
return left(input.value);
case "right":
return right(input.value);
}
}
调用者此时可以定义自己的函数,返回类型是个 Either,失败返回 Error,成功得到运动的方向
function validateCrabMoveDirection(
crab: Crab
): Either<Error, { direction: Direction }> {
if (crab.name === "strange crab") {
// return Left type
return { type: "left", value: Error("x") };
}
// return Right type
return { type: "right", value: { direction: crab.smartmove("right") } };
}
于是可以用 match 来获取上述函数的运行结果:
{
const direction = match(
validateCrabMoveDirection(crab),
(_) => null,
(right) => right.direction
);
// output: right
console.log(direction);
}
{
const crab = new Crab("strange crab");
const direction = match(
validateCrabMoveDirection(crab),
(_) => null,
(right) => right.direction
);
// output: null
console.log(direction);
}
Type-safe action creator in Redux
讲到这里不得不讲下 TypeScript 在 Redux 中的应用,当我们给 redux 的 action type 定义很多类型时,一个显著的问题是,不同 action creator 的函数类型不能动态获取,此时我们可以利用 TypeScript 的 ReturnType 来解决
以一个 Notes 应用为例
首先定义 Notes 的 interface
interface Note {
id: number;
title: string;
content: string;
creationDate: string;
}
然后定义 action type,可以用 const
const FETCH_REQUEST = "FETCH_REQUEST";
const FETCH_SUCCESS = "FETCH_SUCCESS";
const FETCH_ERROR = "FETCH_ERROR";
或者使用 enum
const enum NotesActionTypes {
FETCH_REQUEST = "@@notes/FETCH_REQUEST",
FETCH_SUCCESS = "@@notes/FETCH_SUCCESS",
FETCH_ERROR = "@@notes/FETCH_ERROR",
}
然后定义我们的 action creator,此时用到 typesafe-actions 这个库
const fetchRequest = createAction(NotesActionTypes.FETCH_REQUEST);
const fetchSuccess = createAction(NotesActionTypes.FETCH_SUCCESS, (action) => {
return (data: Note[]) => action(data);
});
const fetchError = createAction(NotesActionTypes.FETCH_ERROR, (action) => {
return (message: string) => action(message);
});
每个 action creator 的返回类型不同,此时 ReturnType 登场
// 利用 ReturnType 定义 action 减少代码冗余
const actions = { fetchRequest, fetchSuccess, fetchError };
type Action = ReturnType<(typeof actions)[keyof typeof actions]>;
定义了上述 Action,我们就可以给我们的 reducer 中的 action 做类型检查了
// 定义 redux state
type State = { notes: Note[]; state: string; errorMessage?: string };
// 定义 redux reducer
const reducer: Reducer<State> = (state: State, action: Action) => {
switch (action.type) {
case getType(fetchRequest): {
return { ...state, state: "LOADING" };
}
case getType(fetchSuccess): {
return { ...state, state: "LOADED", notes: action.payload };
}
case getType(fetchError): {
return {
...state,
state: "ERROR",
notes: [],
errorMessage: action.payload,
};
}
default: {
return state;
}
}
};
简单测试
let state = { notes: [], state: "INIT" };
state = reducer(state, fetchRequest());
// { notes: [], state: 'LOADING' }
console.log(state);
后记
关于为何螃蟹要横向走?来自维基百科
因为腿关节构造的缘故,螃蟹横著走会比较迅速,因此它们一般都是横著行进的,另外,蛙蟹科的一些生物也会直着或倒退着行进。
螃蟹富含优质蛋白质,蟹肉较细腻,肌肉纤维中含有 10 余种游离氨基酸,其中谷氨酸、脯氨酸、精氨酸含量较多,对术后、病后、慢性消耗性疾病等需要补充营养的人大有益处。螃蟹脂肪含量很低,但维生素 A、E 和 B 族较高,特别是蟹黄中富含维生素 A,有益于视力及皮肤健康。蟹富含矿物元素钙、镁以及锌、硒、铜等人体必需的微量元素。但由于螃蟹高胆固醇、高嘌呤,痛风患者食用时应自我节制,患有感冒、肝炎、心血管疾病的人不宜食蟹。死蟹不能吃,会带有大量细菌和毒素。
题图 https://pixabay.com/users/skylark-201564/
Narrowing
- 1.
typeofType Guards - 2. Truthiness Checking
- 3. Equality Narrowing
- 4.
inOperator Narrowing - 5.
instanceofNarrowing - 6. Control Flow Analysis
- 7. User-Defined Type Guards
In TypeScript, narrowing is the process of refining a variable's type from a broader type to a more specific one based on certain runtime checks. TypeScript uses control flow analysis to track the execution paths in your code, allowing it to infer more specific types in different branches. Here are some common techniques for narrowing:
1. typeof Type Guards
You can use the typeof operator to check the basic data type of a variable:
if (typeof value === "string") {
// TypeScript knows that value is a string here
}
2. Truthiness Checking
In conditional statements, TypeScript narrows types based on truthiness. For example:
if (value) {
// TypeScript knows value is not null, undefined, 0, NaN, or an empty string here
}
3. Equality Narrowing
By comparing two values for equality, TypeScript can infer that they are of the same type:
if (x === y) {
// x and y are narrowed to the same type here
}
4. in Operator Narrowing
The in operator checks if an object has a property, which can narrow the type:
if ("property" in obj) {
// obj has the property here
}
5. instanceof Narrowing
The instanceof operator checks whether an object is an instance of a particular class, narrowing the type:
if (obj instanceof SomeClass) {
// obj is known to be an instance of SomeClass here
}
6. Control Flow Analysis
TypeScript analyzes the control flow of your code, allowing it to track the types of variables. This means that a variable's type can be narrowed in different branches of code:
function example(value: number | string) {
if (typeof value === "number") {
// value is narrowed to number here
return value.toFixed(2);
}
// value is narrowed to string here
return value.toUpperCase();
}
7. User-Defined Type Guards
You can define a function that returns a type predicate to narrow types more flexibly:
function isFish(pet: Fish | Bird): pet is Fish {
return (pet as Fish).swim !== undefined;
}
if (isFish(pet)) {
pet.swim(); // pet is inferred to be Fish here
}
These narrowing techniques allow TypeScript to provide more stringent type checking at compile time, reducing runtime errors and enhancing the safety of your code.
Solana useWallet example
Here's a blog post about TypeScript's type narrowing:
Understanding TypeScript Type Narrowing: A Real-World Example
When working with TypeScript, you might encounter situations where a variable could be of multiple types. Here's a practical example I encountered while building a Solana dApp that demonstrates how TypeScript's type narrowing can help us write safer code.
The Problem
In our Solana application, we were using the useWallet() hook which returns a publicKey that could be either a PublicKey object or null:
const { publicKey } = useWallet(); // Type: PublicKey | null
When trying to pass this publicKey to a function that specifically required a PublicKey, TypeScript complained:
// Error: Type 'PublicKey | null' is not assignable to type 'PublicKey'
initialize.mutateAsync({ name: bankName, owner: publicKey });
The Solution: Type Narrowing
TypeScript has a powerful feature called "type narrowing" that helps us handle these situations. By adding a null check, we can narrow the type from PublicKey | null to just PublicKey:
if (!publicKey) {
toast.error("Please connect your wallet");
return;
}
// TypeScript now knows publicKey is definitely a PublicKey
initialize.mutateAsync({ name: bankName, owner: publicKey });
How It Works
TypeScript's control flow analysis understands that:
- If
publicKeyisnull, the function will return early - Therefore, in the code after the check,
publicKeymust be aPublicKey - This automatically narrows the type, making it safe to use
Best Practices
This pattern is not just about making TypeScript happy – it's about writing more robust code:
- It handles edge cases explicitly
- It provides clear feedback to users
- It prevents runtime errors that could occur if we tried to use a null value
Conclusion
Type narrowing is one of TypeScript's most powerful features for writing type-safe code. By understanding and using it effectively, we can catch potential errors at compile time rather than runtime, while also providing better user experiences.
Remember: When dealing with nullable types, always consider using type narrowing to handle all possible cases explicitly. Your future self (and your users) will thank you!
Rust grpc helloworld
- Init the project
- Write protocol file
- Write build.rs
- Write helloworld grpc server
- Write helloworld grpc client
- Run helloworld grpc server
- Run helloworld grpc client
- Generated helloworld.rs
In this tutorial, we'll walk you through how to setup a gRPC server in Rust using tonic crate.
Init the project
First, we'll create a new project using cargo init <project_name>.
cargo init tonic_example
Let's see the structure of the directory.
❯ tree
.
├── Cargo.toml
└── src
└── main.rs
2 directories, 2 files
~/tmp/tonic_example master*
❯ ct Cargo.toml
[package]
name = "tonic_example"
version = "0.1.0"
edition = "2021"
[dependencies]
As we'll build a grpc service, we can use tonic crate, which is a Rust implementation of gRPC.
Write protocol file
We'll create a simple greeter service. We'll put proto file in proto directory.
mkdir proto
touch proto/helloworld.proto
Here's the content of the helloworld.proto file, in which we define HelloRequest type, HelloReply type and Greeter service.
syntax = "proto3";
package helloworld;
service Greeter {
// Our SayHello rpc accepts HelloRequests and returns HelloReplies
rpc SayHello (HelloRequest) returns (HelloReply);
}
message HelloRequest {
// Request message contains the name to be greeted
string name = 1;
}
message HelloReply {
// Reply contains the greeting message
string message = 1;
}
Here's an explanation of the code:
syntax = "proto3";: This line indicates that you are using version 3 of the protobuf language.package helloworld;: This line defines the package name for the service. It helps to prevent name clashes between protobuf messages.
The service definition starts with this line: service Greeter {. Here are the key points:
Greeter: This is the name of the service (essentially an API) you are defining.- The service
Greeterhas a single methodSayHellowhich is defined as:rpc SayHello (HelloRequest) returns (HelloReply);SayHello: This is the name of the function that will be exposed to clients on the gRPC server.(HelloRequest): This denotes the input parameters of the method. It takes in a single parameter of the typeHelloRequest.returns (HelloReply): This shows that the function returns aHelloReplymessage.
The protocol buffer message types are defined with this code:
.message HelloRequest: TheHelloRequestmessage has a single field name of typestring. The= 1;bit is a unique number used to identify the field in the message binary format..message HelloReply: TheHelloReplymessage also has a single field message also of typestring.
In a nutshell, you have defined a Greeter service that has a SayHello method expecting a HelloRequest that contains a name and returns a HelloReply containing the message. It's analogous to defining a REST API endpoint but in the gRPC and protocol buffers context.
Write build.rs
In order to build protobuf file, we need to install the protoc protocol buffers compiler. On MacOS, we can install by using this command:
brew install protobuf
Write helloworld grpc server
Now, let's write server side code.
Create a file helloworld-server.rs in src/bin directory: touch src/bin/helloworld-server.rs.
use tonic::{transport::Server, Request, Response, Status}; use hello_world::{ greeter_server::{Greeter, GreeterServer}, HelloReply, HelloRequest, }; pub mod hello_world { tonic::include_proto!("helloworld"); } #[derive(Debug, Default)] pub struct MyGreeter {} #[tonic::async_trait] impl Greeter for MyGreeter { async fn say_hello( &self, request: Request<HelloRequest>, ) -> Result<Response<HelloReply>, Status> { // println!("Got a request: {:?}", request); let reply = hello_world::HelloReply { message: format!("Hello {}!", request.into_inner().name).into(), }; Ok(Response::new(reply)) } } #[tokio::main] // #[tokio::main(core_threads = 16, max_threads = 32)] async fn main() -> Result<(), Box<dyn std::error::Error>> { // NOTE: This works! let addr = "[::1]:50051".parse()?; // NOTE❌: This does NOT works! ConnectionRefused error // let addr = "0.0.0.0:50051".parse()?; let greeter = MyGreeter::default(); Server::builder() .add_service(GreeterServer::new(greeter)) .serve(addr) .await?; Ok(()) }
Write helloworld grpc client
Now, let's write client side code.
Create a file helloworld-client.rs in src/bin directory: touch src/bin/helloworld-client.rs.
use hello_world::greeter_client::GreeterClient; use hello_world::HelloRequest; pub mod hello_world { tonic::include_proto!("helloworld"); } #[tokio::main] async fn main() -> Result<(), Box<dyn std::error::Error>> { let mut client = GreeterClient::connect("http://[::1]:50051").await?; let request = tonic::Request::new(HelloRequest { name: "Tonic".into() }); let response = client.say_hello(request).await?; println!("RESPONSE={:?}", response); Ok(()) }
Run helloworld grpc server
Now, let's run the grpc server.
cargo run --bin helloworld-server
Run helloworld grpc client
While the server is up and running, we can run the grpc client to send request to the server.
cargo run --bin helloworld-client
Output:
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.11s
Running `target/debug/helloworld-client`
RESPONSE=Response {
metadata: MetadataMap {
headers: {
"content-type": "application/grpc",
"date": "Wed, 03 Apr 2024 17:56:21 GMT",
"grpc-status": "0",
},
},
message: HelloReply {
message: "Hello Tonic!",
},
extensions: Extensions,
}
Generated helloworld.rs
If you're interested in what the generated file looks like, you can refer to helloworld.rs file which is located in target/debug/build/tonic_example-4094918d1c86be5c/out directory.
Below is the contents of the file.
#![allow(unused)] fn main() { #[allow(clippy::derive_partial_eq_without_eq)] #[derive(Clone, PartialEq, ::prost::Message)] pub struct HelloRequest { /// Request message contains the name to be greeted #[prost(string, tag = "1")] pub name: ::prost::alloc::string::String, } #[allow(clippy::derive_partial_eq_without_eq)] #[derive(Clone, PartialEq, ::prost::Message)] pub struct HelloReply { /// Reply contains the greeting message #[prost(string, tag = "1")] pub message: ::prost::alloc::string::String, } /// Generated client implementations. pub mod greeter_client { #![allow(unused_variables, dead_code, missing_docs, clippy::let_unit_value)] use tonic::codegen::*; use tonic::codegen::http::Uri; #[derive(Debug, Clone)] pub struct GreeterClient<T> { inner: tonic::client::Grpc<T>, } impl GreeterClient<tonic::transport::Channel> { /// Attempt to create a new client by connecting to a given endpoint. pub async fn connect<D>(dst: D) -> Result<Self, tonic::transport::Error> where D: TryInto<tonic::transport::Endpoint>, D::Error: Into<StdError>, { let conn = tonic::transport::Endpoint::new(dst)?.connect().await?; Ok(Self::new(conn)) } } impl<T> GreeterClient<T> where T: tonic::client::GrpcService<tonic::body::BoxBody>, T::Error: Into<StdError>, T::ResponseBody: Body<Data = Bytes> + Send + 'static, <T::ResponseBody as Body>::Error: Into<StdError> + Send, { pub fn new(inner: T) -> Self { let inner = tonic::client::Grpc::new(inner); Self { inner } } pub fn with_origin(inner: T, origin: Uri) -> Self { let inner = tonic::client::Grpc::with_origin(inner, origin); Self { inner } } pub fn with_interceptor<F>( inner: T, interceptor: F, ) -> GreeterClient<InterceptedService<T, F>> where F: tonic::service::Interceptor, T::ResponseBody: Default, T: tonic::codegen::Service< http::Request<tonic::body::BoxBody>, Response = http::Response< <T as tonic::client::GrpcService<tonic::body::BoxBody>>::ResponseBody, >, >, <T as tonic::codegen::Service< http::Request<tonic::body::BoxBody>, >>::Error: Into<StdError> + Send + Sync, { GreeterClient::new(InterceptedService::new(inner, interceptor)) } /// Compress requests with the given encoding. /// /// This requires the server to support it otherwise it might respond with an /// error. #[must_use] pub fn send_compressed(mut self, encoding: CompressionEncoding) -> Self { self.inner = self.inner.send_compressed(encoding); self } /// Enable decompressing responses. #[must_use] pub fn accept_compressed(mut self, encoding: CompressionEncoding) -> Self { self.inner = self.inner.accept_compressed(encoding); self } /// Limits the maximum size of a decoded message. /// /// Default: `4MB` #[must_use] pub fn max_decoding_message_size(mut self, limit: usize) -> Self { self.inner = self.inner.max_decoding_message_size(limit); self } /// Limits the maximum size of an encoded message. /// /// Default: `usize::MAX` #[must_use] pub fn max_encoding_message_size(mut self, limit: usize) -> Self { self.inner = self.inner.max_encoding_message_size(limit); self } /// Our SayHello rpc accepts HelloRequests and returns HelloReplies pub async fn say_hello( &mut self, request: impl tonic::IntoRequest<super::HelloRequest>, ) -> std::result::Result<tonic::Response<super::HelloReply>, tonic::Status> { self.inner .ready() .await .map_err(|e| { tonic::Status::new( tonic::Code::Unknown, format!("Service was not ready: {}", e.into()), ) })?; let codec = tonic::codec::ProstCodec::default(); let path = http::uri::PathAndQuery::from_static( "/helloworld.Greeter/SayHello", ); let mut req = request.into_request(); req.extensions_mut() .insert(GrpcMethod::new("helloworld.Greeter", "SayHello")); self.inner.unary(req, path, codec).await } } } /// Generated server implementations. pub mod greeter_server { #![allow(unused_variables, dead_code, missing_docs, clippy::let_unit_value)] use tonic::codegen::*; /// Generated trait containing gRPC methods that should be implemented for use with GreeterServer. #[async_trait] pub trait Greeter: Send + Sync + 'static { /// Our SayHello rpc accepts HelloRequests and returns HelloReplies async fn say_hello( &self, request: tonic::Request<super::HelloRequest>, ) -> std::result::Result<tonic::Response<super::HelloReply>, tonic::Status>; } #[derive(Debug)] pub struct GreeterServer<T: Greeter> { inner: _Inner<T>, accept_compression_encodings: EnabledCompressionEncodings, send_compression_encodings: EnabledCompressionEncodings, max_decoding_message_size: Option<usize>, max_encoding_message_size: Option<usize>, } struct _Inner<T>(Arc<T>); impl<T: Greeter> GreeterServer<T> { pub fn new(inner: T) -> Self { Self::from_arc(Arc::new(inner)) } pub fn from_arc(inner: Arc<T>) -> Self { let inner = _Inner(inner); Self { inner, accept_compression_encodings: Default::default(), send_compression_encodings: Default::default(), max_decoding_message_size: None, max_encoding_message_size: None, } } pub fn with_interceptor<F>( inner: T, interceptor: F, ) -> InterceptedService<Self, F> where F: tonic::service::Interceptor, { InterceptedService::new(Self::new(inner), interceptor) } /// Enable decompressing requests with the given encoding. #[must_use] pub fn accept_compressed(mut self, encoding: CompressionEncoding) -> Self { self.accept_compression_encodings.enable(encoding); self } /// Compress responses with the given encoding, if the client supports it. #[must_use] pub fn send_compressed(mut self, encoding: CompressionEncoding) -> Self { self.send_compression_encodings.enable(encoding); self } /// Limits the maximum size of a decoded message. /// /// Default: `4MB` #[must_use] pub fn max_decoding_message_size(mut self, limit: usize) -> Self { self.max_decoding_message_size = Some(limit); self } /// Limits the maximum size of an encoded message. /// /// Default: `usize::MAX` #[must_use] pub fn max_encoding_message_size(mut self, limit: usize) -> Self { self.max_encoding_message_size = Some(limit); self } } impl<T, B> tonic::codegen::Service<http::Request<B>> for GreeterServer<T> where T: Greeter, B: Body + Send + 'static, B::Error: Into<StdError> + Send + 'static, { type Response = http::Response<tonic::body::BoxBody>; type Error = std::convert::Infallible; type Future = BoxFuture<Self::Response, Self::Error>; fn poll_ready( &mut self, _cx: &mut Context<'_>, ) -> Poll<std::result::Result<(), Self::Error>> { Poll::Ready(Ok(())) } fn call(&mut self, req: http::Request<B>) -> Self::Future { let inner = self.inner.clone(); match req.uri().path() { "/helloworld.Greeter/SayHello" => { #[allow(non_camel_case_types)] struct SayHelloSvc<T: Greeter>(pub Arc<T>); impl<T: Greeter> tonic::server::UnaryService<super::HelloRequest> for SayHelloSvc<T> { type Response = super::HelloReply; type Future = BoxFuture< tonic::Response<Self::Response>, tonic::Status, >; fn call( &mut self, request: tonic::Request<super::HelloRequest>, ) -> Self::Future { let inner = Arc::clone(&self.0); let fut = async move { <T as Greeter>::say_hello(&inner, request).await }; Box::pin(fut) } } let accept_compression_encodings = self.accept_compression_encodings; let send_compression_encodings = self.send_compression_encodings; let max_decoding_message_size = self.max_decoding_message_size; let max_encoding_message_size = self.max_encoding_message_size; let inner = self.inner.clone(); let fut = async move { let inner = inner.0; let method = SayHelloSvc(inner); let codec = tonic::codec::ProstCodec::default(); let mut grpc = tonic::server::Grpc::new(codec) .apply_compression_config( accept_compression_encodings, send_compression_encodings, ) .apply_max_message_size_config( max_decoding_message_size, max_encoding_message_size, ); let res = grpc.unary(method, req).await; Ok(res) }; Box::pin(fut) } _ => { Box::pin(async move { Ok( http::Response::builder() .status(200) .header("grpc-status", "12") .header("content-type", "application/grpc") .body(empty_body()) .unwrap(), ) }) } } } } impl<T: Greeter> Clone for GreeterServer<T> { fn clone(&self) -> Self { let inner = self.inner.clone(); Self { inner, accept_compression_encodings: self.accept_compression_encodings, send_compression_encodings: self.send_compression_encodings, max_decoding_message_size: self.max_decoding_message_size, max_encoding_message_size: self.max_encoding_message_size, } } } impl<T: Greeter> Clone for _Inner<T> { fn clone(&self) -> Self { Self(Arc::clone(&self.0)) } } impl<T: std::fmt::Debug> std::fmt::Debug for _Inner<T> { fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result { write!(f, "{:?}", self.0) } } impl<T: Greeter> tonic::server::NamedService for GreeterServer<T> { const NAME: &'static str = "helloworld.Greeter"; } } }
Upgrade diesel to 2.0
An introduction to diesel 2.0
Diesel 2.0 has breaking changes compared to 1.4.x.
Any code base migrating from Diesel 1.4.x to Diesel 2.0 is expected to be affected at least by the following changes:
Upgrade to diesel 2.0
Upgrade diesel version in Cargo.toml
In order to upgrade diesel to 2.0, we need to change dependencies in Cargo.toml.
diff --git a/rust/projects/diesel_2.0_example/Cargo.toml b/rust/projects/diesel_2.0_example/Cargo.toml
index 8f5a1aa..5164334 100644
--- a/rust/projects/diesel_2.0_example/Cargo.toml
+++ b/rust/projects/diesel_2.0_example/Cargo.toml
@@ -5,12 +5,13 @@ authors = ["lichuan <lichuan@mur>"]
edition = "2018"
[dependencies]
-diesel = { version = "1.4", features = [
+diesel = { version = "2.1.2", features = [
"postgres",
"serde_json",
"chrono",
"numeric",
"64-column-tables",
+ "r2d2",
] }
# r2d2 = "0.8"
# r2d2-diesel = "1.0"
dotenv = "0.14"
# actix-web = "1.0.3"
chrono = { version = "0.4.7", features = ["serde"] }
We change diesel version to 2.1.2 and remove r2d2 and r2d2-diesel dependencies, as they are included in diesel crate, by specifying the r2d2 feature in diesel crate diesel = { version = "2.1.2", features = [ "r2d2" ] }.
Add mut to PgConnection and dao functions
Diesel now requires mutable access to the Connection to perform any database interaction. The following changes are required for all usages of any Connection type:
- let connection = PgConnection::establish_connection("…")?;
- let result = some_query.load(&connection)?;
+ let mut connection = PgConnection::establish_connection("…")?;
+ let result = some_query.load(&mut connection)?;
Here are the changes for our own code:
diff --git a/rust/projects/diesel_2.0_example/src/bin/contacts.rs b/rust/projects/diesel_2.0_example/src/bin/contacts.rs
index a74e29397..6efc8ef4f 100644
--- a/rust/projects/diesel_2.0_example/src/bin/contacts.rs
+++ b/rust/projects/diesel_2.0_example/src/bin/contacts.rs
@@ -16,11 +16,15 @@ fn test_contacts() {
env::var("DATABASE_URL").unwrap_or(LOCAL_DATABASE_URL.into());
let pool = db::init_pool(database_url);
// https://github.com/sfackler/r2d2/issues/37
- let connection = pool.get().unwrap();
+ let mut conn = pool.get().unwrap();
- let conn: &PgConnection = &connection;
- conn.execute("TRUNCATE TABLE contacts").unwrap();
- conn.execute("alter sequence contacts_id_seq restart;").unwrap();
+ diesel::sql_query("TRUNCATE TABLE contacts").execute(&mut conn).unwrap();
+ diesel::sql_query("alter sequence contacts_id_seq restart;")
+ .execute(&mut conn)
+ .unwrap();
+
+ // conn.execute("TRUNCATE TABLE contacts").unwrap();
+ // conn.execute("alter sequence contacts_id_seq restart;").unwrap();
let santas_address: serde_json::Value = serde_json::from_str(
r#"{
@@ -61,7 +65,7 @@ fn test_contacts() {
},
];
- let contacts = create_contracts(&conn, &new_contacts).unwrap();
+ let contacts = create_contracts(&mut conn, &new_contacts).unwrap();
println!("{:?}", contacts);
// let inserted_address = insert_into(contacts)
@@ -75,9 +79,7 @@ fn get_contacts() {
let database_url =
env::var("DATABASE_URL").unwrap_or(LOCAL_DATABASE_URL.into());
let pool = db::init_pool(database_url);
- let connection = pool.get().unwrap();
-
- let conn: &PgConnection = &connection;
+ let mut conn = pool.get().unwrap();
let santas_address: serde_json::Value = serde_json::from_str(
r#"{
@@ -86,12 +88,13 @@ fn get_contacts() {
)
.unwrap();
- let contacts = get_contacts_by_address(&conn, &santas_address).unwrap();
+ let contacts = get_contacts_by_address(&mut conn, &santas_address).unwrap();
println!("{:?}", contacts);
let santas_address2: serde_json::Value = json!(true);
- let contacts = get_contacts_by_address(&conn, &santas_address2).unwrap();
+ let contacts =
+ get_contacts_by_address(&mut conn, &santas_address2).unwrap();
println!("{:?}", contacts);
}
diff --git a/rust/projects/diesel_2.0_example/src/bin/select-limit-offset.rs b/rust/projects/diesel_2.0_example/src/bin/select-limit-offset.rs
index a9c583039..a69489b7a 100644
--- a/rust/projects/diesel_2.0_example/src/bin/select-limit-offset.rs
+++ b/rust/projects/diesel_2.0_example/src/bin/select-limit-offset.rs
@@ -10,13 +10,11 @@ fn select_limit_offset() {
env::var("DATABASE_URL").unwrap_or(local_database_url.into());
let pool = db::init_pool(database_url);
// https://github.com/sfackler/r2d2/issues/37
- let connection = pool.get().unwrap();
-
- let _conn: &PgConnection = &connection;
+ let mut conn = pool.get().unwrap();
let limit = 2;
let offset = 2;
- let all = get_select_limit_offset(&connection, limit, offset).unwrap();
+ let all = get_select_limit_offset(&mut conn, limit, offset).unwrap();
println!("select : {:?} records", all);
}
@@ -26,17 +24,15 @@ fn select_limit_offset_loop() {
env::var("DATABASE_URL").unwrap_or(local_database_url.into());
let pool = db::init_pool(database_url);
// https://github.com/sfackler/r2d2/issues/37
- let connection = pool.get().unwrap();
-
- let _conn: &PgConnection = &connection;
+ let mut conn = pool.get().unwrap();
let limit = 2;
let mut offset = 0;
- let all = get_select_limit_offset(&connection, limit, offset).unwrap();
+ let all = get_select_limit_offset(&mut conn, limit, offset).unwrap();
println!("select : {:?} records", all);
loop {
- if let Ok(res) = get_select_limit_offset(&connection, limit, offset) {
+ if let Ok(res) = get_select_limit_offset(&mut conn, limit, offset) {
if res.len() == 0 {
break;
}
diff --git a/rust/projects/diesel_2.0_example/src/bin/test-connect-r2d2-pool-actix.rs b/rust/projects/diesel_2.0_example/src/bin/test-connect-r2d2-pool-actix.rs
index 1010a2380..44bce1eb4 100644
--- a/rust/projects/diesel_2.0_example/src/bin/test-connect-r2d2-pool-actix.rs
+++ b/rust/projects/diesel_2.0_example/src/bin/test-connect-r2d2-pool-actix.rs
@@ -2,15 +2,22 @@ extern crate diesel;
use std::env;
-use actix_web::{web, App, HttpRequest, HttpServer, Responder};
+use actix_web::{web, App, HttpServer, Responder};
use diesel_example::db;
-fn greet(req: HttpRequest) -> impl Responder {
- let name = req.match_info().get("name").unwrap_or("World");
- format!("Hello {}!", &name)
+// TODO: why compile error for actix-web 4?
+// fn greet(req: HttpRequest) -> impl Responder {
+// let name = req.match_info().get("name").unwrap_or("World");
+// format!("Hello {}!", &name)
+// }
+
+// #[get("/hello/{name}")]
+async fn greet(name: web::Path<String>) -> impl Responder {
+ format!("Hello {}!", name)
}
-fn main() {
+#[actix_web::main]
+async fn main() -> std::io::Result<()> {
let database_url = env::var("DATABASE_URL").expect("set DATABASE_URL");
let pool = db::init_pool(database_url);
// https://github.com/sfackler/r2d2/issues/37
@@ -26,5 +33,5 @@ fn main() {
.bind("127.0.0.1:8000")
.expect("Can not bind to port 8000")
.run()
- .unwrap();
+ .await
}
diff --git a/rust/projects/diesel_2.0_example/src/bin/test-partial-inserts.rs b/rust/projects/diesel_2.0_example/src/bin/test-partial-inserts.rs
index 1819a9677..0fa4e2650 100644
--- a/rust/projects/diesel_2.0_example/src/bin/test-partial-inserts.rs
+++ b/rust/projects/diesel_2.0_example/src/bin/test-partial-inserts.rs
@@ -1,4 +1,3 @@
-
use diesel_example::dao::partial_inserts::create_partial_inserts;
use diesel_example::db;
use diesel_example::model::partial_inserts::NewPartialInsert;
@@ -10,7 +9,7 @@ fn main() {
env::var("DATABASE_URL").unwrap_or(local_database_url.into());
let pool = db::init_pool(database_url);
// https://github.com/sfackler/r2d2/issues/37
- let connection = pool.get().unwrap();
+ let mut conn = pool.get().unwrap();
let v = vec![
NewPartialInsert { user_id: 5, name: Some("3".to_string()) },
@@ -20,7 +19,7 @@ fn main() {
// 如果每次插入多个,其中一个报错(比如以上 user_id = 2),整体插入失败(5 不被插入)
// Err(DatabaseError(UniqueViolation, "duplicate key value violates unique constraint \"ui_partial_inserts_user_id\""))
- let r = create_partial_inserts(&connection, &v);
+ let r = create_partial_inserts(&mut conn, &v);
println!("{:?}", r);
}
diff --git a/rust/projects/diesel_2.0_example/src/bin/timestamp-with-zone.rs b/rust/projects/diesel_2.0_example/src/bin/timestamp-with-zone.rs
index e5a793222..1d3b3e72d 100644
--- a/rust/projects/diesel_2.0_example/src/bin/timestamp-with-zone.rs
+++ b/rust/projects/diesel_2.0_example/src/bin/timestamp-with-zone.rs
@@ -1,7 +1,5 @@
-use chrono::{DateTime};
-use diesel_example::dao::timestamp_with_zone::{
- create_timestamp_with_zones,
-};
+use chrono::DateTime;
+use diesel_example::dao::timestamp_with_zone::create_timestamp_with_zones;
use diesel_example::db;
use diesel_example::model::timestamp_with_zone::NewTimestampWithZone;
use std::env;
@@ -12,7 +10,7 @@ fn main() {
env::var("DATABASE_URL").unwrap_or(local_database_url.into());
let pool = db::init_pool(database_url);
// https://github.com/sfackler/r2d2/issues/37
- let connection = pool.get().unwrap();
+ let mut conn = pool.get().unwrap();
/*
let mut user_id = 123;
@@ -45,7 +43,7 @@ fn main() {
NewTimestampWithZone { user_id: 109, created_at: dt.into() },
];
- let inserted = create_timestamp_with_zones(&connection, &zones);
+ let inserted = create_timestamp_with_zones(&mut conn, &zones);
match inserted {
Ok(ref v) => {
println!(
diff --git a/rust/projects/diesel_2.0_example/src/bin/updated-at.rs b/rust/projects/diesel_2.0_example/src/bin/updated-at.rs
index c536b6a9c..27c5a37da 100644
--- a/rust/projects/diesel_2.0_example/src/bin/updated-at.rs
+++ b/rust/projects/diesel_2.0_example/src/bin/updated-at.rs
@@ -10,7 +10,7 @@ fn main() {
env::var("DATABASE_URL").unwrap_or(local_database_url.into());
let pool = db::init_pool(database_url);
// https://github.com/sfackler/r2d2/issues/37
- let connection = pool.get().unwrap();
+ let mut conn = pool.get().unwrap();
let user_id = 123;
let n = NewWeiboFeedCrawlStatus {
@@ -20,11 +20,8 @@ fn main() {
created_at: Local::now().naive_local(),
updated_at: None,
};
- create_weibo_feed_crawl_status(&connection, &n);
+ create_weibo_feed_crawl_status(&mut conn, &n);
update_total_page_count_and_next_page_index_by_user_id(
- user_id,
- &connection,
- 1,
- 1,
+ user_id, &mut conn, 1, 1,
);
}
diff --git a/rust/projects/diesel_2.0_example/src/bin/upsert-if-condition.rs b/rust/projects/diesel_2.0_example/src/bin/upsert-if-condition.rs
index ca7f19d77..807f74272 100644
--- a/rust/projects/diesel_2.0_example/src/bin/upsert-if-condition.rs
+++ b/rust/projects/diesel_2.0_example/src/bin/upsert-if-condition.rs
@@ -10,11 +10,15 @@ fn upsert_on_conflict_id() {
env::var("DATABASE_URL").unwrap_or(local_database_url.into());
let pool = db::init_pool(database_url);
// https://github.com/sfackler/r2d2/issues/37
- let connection = pool.get().unwrap();
+ let mut conn = pool.get().unwrap();
- let conn: &PgConnection = &connection;
- conn.execute("TRUNCATE TABLE upserts_if_condition").unwrap();
- conn.execute("alter sequence upserts_if_condition_id_seq restart;")
+ // let conn: &mut PgConnection = &mut connection;
+ // conn.execute("TRUNCATE TABLE upserts_if_condition").unwrap();
+ // conn.execute("alter sequence upserts_if_condition_id_seq restart;")
+ // .unwrap();
+
+ diesel::sql_query("TRUNCATE TABLE upserts_if_condition")
+ .execute(&mut conn)
.unwrap();
let u = NewUpsertIfCondition {
@@ -27,7 +31,7 @@ fn upsert_on_conflict_id() {
next: Some(9),
email: Some("e".into()),
};
- let inserted = create_upserts_if_condition_by_sql(&connection, &u).unwrap();
+ let inserted = create_upserts_if_condition_by_sql(&mut conn, &u).unwrap();
println!("{} records inserted", inserted.len());
}
Derive attributes
You should add #[diesel()] when using derive attributes.
Below is an example of using table_name macro to define NewTimestampWithZone struct.
#![allow(unused)] fn main() { #[derive(Insertable, Debug)] // NOTE: For diesel 1.4.x, we use `table_name` macro directly. // #[table_name = "timestamp_with_zone"] #[table_name = "timestamp_with_zone"] pub struct NewTimestampWithZone { pub user_id: i64, pub created_at: DateTime<Utc>, } }
Refs
Diesel 2.0 migration guide https://diesel.rs/guides/migration_guide.html
Diesel JSONB Example
- Into
- Install dependencies
- Write sql for migration
- run migration
- Create database models
- Add more dependencies
- Modify main.rs
- Build
- Create orders
- Query orders
- Update order
- Delete order
- Summary
- Refs
Into
This is a simple example of using Diesel with JSONB in a Rust project.
Install dependencies
First, let's create a new project and add dependencies:
# Init project
cargo init order-diesel-jsonb-example
# Add dependencies
cd order-diesel-jsonb-example
cargo add diesel -F postgres
cargo add dotenvy
# Install diesel cli
cargo install diesel_cli
# Tell diesel where to find the database
# echo DATABASE_URL=postgres://username:password@localhost/diesel_demo > .env
echo DATABASE_URL=postgres://localhost/diesel_demo > .env
# Create postgres database
createdb diesel_demo
psql diesel_demo
# setup diesel and run migrations
diesel setup
diesel migration generate create_orders
# Output:
# Creating migrations/2024-12-16-120623_create_orders/up.sql
# Creating migrations/2024-12-16-120623_create_orders/down.sql
Write sql for migration
As diesel documents say:
Migrations allow us to evolve the database schema over time. Each migration consists of an up.sql file to apply the changes and a down.sql file to revert them.
diesel will create migrations directory after running diesel migration generate create_orders. It will create up.sql and down.sql files.
Let's write some sql in migrations/2024-12-16-120623_create_orders/up.sql:
-- Your SQL goes here
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
user_id INTEGER NOT NULL,
total_amount DECIMAL(10, 2) NOT NULL,
order_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
metadata JSONB
);
CREATE INDEX idx_order_metadata ON orders USING gin (metadata);
And migrations/2024-12-16-120623_create_orders/down.sql:
DROP TABLE orders;
run migration
Run diesel migration run will create table in postgres:
dylan@/tmp:diesel_demo> \d orders;
+--------------+-----------------------------+------------------------------------------------------+
| Column | Type | Modifiers |
|--------------+-----------------------------+------------------------------------------------------|
| id | integer | not null default nextval('orders_id_seq'::regclass) |
| user_id | integer | not null |
| total_amount | numeric(10,2) | not null |
| order_date | timestamp without time zone | not null default CURRENT_TIMESTAMP |
| metadata | jsonb | |
+--------------+-----------------------------+------------------------------------------------------+
Indexes:
"orders_pkey" PRIMARY KEY, btree (id)
"idx_order_metadata" gin (metadata)
Time: 0.034s
Also, diesel migration generate create_orders will generate the following code in src/schema.rs:
// @generated automatically by Diesel CLI.
diesel::table! {
orders (id) {
id -> Int4,
user_id -> Int4,
total_amount -> Numeric,
order_date -> Timestamp,
metadata -> Nullable<Jsonb>,
}
}
Schema defines a Rust module representing the table structure.
The key components for the schema are:
- Table Structure: Each table is represented by a struct, typically referenced as
users::table. - Column Definitions: Each column is represented by a struct implementing the
Expressiontrait to specify SQL types. - DSL Module: Provides a convenient syntax for queries, making them less verbose than writing SQL directly.
By leveraging Diesel's powerful features, you can easily interact with the database, perform complex queries, and manage your data efficiently.
#![allow(unused)] fn main() { use diesel::prelude::*; use dotenvy::dotenv; use diesel::pg::PgConnection; use diesel::r2d2::ConnectionManager; use diesel::r2d2::Pool; use crate::schema::orders; pub type PgPool = Pool<ConnectionManager<PgConnection>>; pub fn establish_connection() -> PgPool { dotenv().ok(); let database_url = std::env::var("DATABASE_URL").expect("DATABASE_URL must be set"); let manager = ConnectionManager::<PgConnection>::new(database_url); Pool::builder() .build(manager) .expect("Failed to create pool.") } pub fn create_order(conn: &PgConnection, new_order: NewOrder) -> Result<Order, diesel::result::Error> { use crate::schema::orders; diesel::insert_into(orders::table) .values(&new_order) .get_result(conn) } }
Create database models
Now, let's create database models in src/models.rs.
#![allow(unused)] fn main() { use diesel::prelude::*; use serde::{Deserialize, Serialize}; use chrono::NaiveDateTime; use serde_json::Value; #[derive(Queryable, Selectable, Insertable, Serialize, Deserialize, Debug)] #[diesel(table_name = orders)] #[diesel(check_for_backend(diesel::pg::Pg))] pub struct Order { pub id: i32, pub user_id: i32, pub total_amount: f64, pub order_date: NaiveDateTime, pub metadata: Value, // This will use JSONB } #[derive(Insertable, Deserialize)] #[diesel(table_name = orders)] pub struct NewOrder { pub user_id: i32, pub total_amount: f64, pub metadata: Value, } }
Here are some notes about the code:
-
#[derive(Queryable)]will generate all of the code needed to load aOrderstruct from a SQL query. -
#[derive(Selectable)]will generate code to construct a matching select clause based on your model type based on the table defined via#[diesel(table_name = orders)]. -
#[diesel(check_for_backend(diesel::pg::Pg))(orsqlite::SQLiteormysql::MySQL) adds additional compile time checks to verify that all field types in your struct are compatible with their corresponding SQL side expressions. This part is optional, but it greatly improves the generated compiler error messages.
If any types are not compatible with column type in database, Diesel will emit a compile-time error.
Add more dependencies
cargo add anyhow serde_json
cargo add chrono -F serde
cargo add serde -F derive
Here is the output:
> cargo add anyhow serde_json
Updating crates.io index
Adding anyhow v1.0.94 to dependencies
Features:
+ std
- backtrace
Adding serde_json v1.0.133 to dependencies
Features:
+ std
- alloc
- arbitrary_precision
- float_roundtrip
- indexmap
- preserve_order
- raw_value
- unbounded_depth
Updating crates.io index
Blocking waiting for file lock on package cache
Locking 6 packages to latest compatible versions
Adding anyhow v1.0.94
Adding memchr v2.7.4
Adding ryu v1.0.18
Adding serde v1.0.216
Adding serde_derive v1.0.216
Adding serde_json v1.0.133
> cargo add chrono -F serde
Updating crates.io index
Adding chrono v0.4.39 to dependencies
Features:
+ alloc
+ android-tzdata
+ clock
+ iana-time-zone
+ js-sys
+ now
+ oldtime
+ serde
+ std
+ wasm-bindgen
+ wasmbind
+ winapi
+ windows-targets
- __internal_bench
- arbitrary
- libc
- pure-rust-locales
- rkyv
- rkyv-16
- rkyv-32
- rkyv-64
- rkyv-validation
- unstable-locales
Updating crates.io index
Blocking waiting for file lock on package cache
Locking 31 packages to latest compatible versions
Adding android-tzdata v0.1.1
Adding android_system_properties v0.1.5
Adding autocfg v1.4.0
Adding bumpalo v3.16.0
Adding cc v1.2.4
Adding cfg-if v1.0.0
Adding chrono v0.4.39
Adding core-foundation-sys v0.8.7
Adding iana-time-zone v0.1.61
Adding iana-time-zone-haiku v0.1.2
Adding js-sys v0.3.76
Adding libc v0.2.168
Adding log v0.4.22
Adding num-traits v0.2.19
Adding once_cell v1.20.2
Adding shlex v1.3.0
Adding wasm-bindgen v0.2.99
Adding wasm-bindgen-backend v0.2.99
Adding wasm-bindgen-macro v0.2.99
Adding wasm-bindgen-macro-support v0.2.99
Adding wasm-bindgen-shared v0.2.99
Adding windows-core v0.52.0
Adding windows-targets v0.52.6
Adding windows_aarch64_gnullvm v0.52.6
Adding windows_aarch64_msvc v0.52.6
Adding windows_i686_gnu v0.52.6
Adding windows_i686_gnullvm v0.52.6
Adding windows_i686_msvc v0.52.6
Adding windows_x86_64_gnu v0.52.6
Adding windows_x86_64_gnullvm v0.52.6
Adding windows_x86_64_msvc v0.52.6
> cargo add serde -F derive
Updating crates.io index
Adding serde v1.0.216 to dependencies
Features:
+ derive
+ serde_derive
+ std
- alloc
- rc
- unstable
Blocking waiting for file lock on package cache
Blocking waiting for file lock on package cache
Modify main.rs
Now, let's modify main.rs to create a new order and print the result:
mod models; mod schema; mod db; use diesel::pg::PgConnection; use diesel::Connection; use dotenvy::dotenv; use std::env; fn establish_connection() -> PgConnection { dotenv().ok(); let database_url = env::var("DATABASE_URL") .expect("DATABASE_URL must be set"); PgConnection::establish(&database_url) .expect(&format!("Error connecting to {}", database_url)) } fn main() { let conn = &mut establish_connection(); // Example usage let new_order = models::NewOrder { user_id: 1, total_amount: 99.99, metadata: serde_json::json!({ "items": ["book", "pen"], "shipping_method": "express", "gift_wrap": true }), }; match db::create_order(conn, new_order) { Ok(order) => println!("Created order: {:?}", order), Err(e) => eprintln!("Error creating order: {}", e), } }
Build
Build and fail
Now, let's build the project and see the error:
> cargo build
Compiling core-foundation-sys v0.8.7
Compiling itoa v1.0.14
Compiling memchr v2.7.4
Compiling pq-sys v0.6.3
Compiling num-traits v0.2.19
Compiling byteorder v1.5.0
Compiling bitflags v2.6.0
Compiling serde v1.0.216
Compiling ryu v1.0.18
Compiling anyhow v1.0.94
Compiling dotenvy v0.15.7
Compiling iana-time-zone v0.1.61
Compiling diesel v2.2.6
Compiling serde_json v1.0.133
Compiling chrono v0.4.39
Compiling order-diesel-jsonb-example v0.1.0 (
error[E0433]: failed to resolve: use of undeclared crate or module `orders`
--> src/models.rs:7:23
|
7 | #[diesel(table_name = orders)]
| ^^^^^^ use of undeclared crate or module `orders`
|
help: a struct with a similar name exists
|
7 | #[diesel(table_name = Order)]
| ~~~~~
help: consider importing this struct through its public re-export
|
1 + use crate::schema::orders::dsl::orders;
|
error[E0433]: failed to resolve: use of undeclared crate or module `orders`
--> src/models.rs:18:23
|
18 | #[diesel(table_name = orders)]
| ^^^^^^ use of undeclared crate or module `orders`
|
help: a struct with a similar name exists
|
18 | #[diesel(table_name = Order)]
| ~~~~~
help: consider importing this struct through its public re-export
|
1 + use crate::schema::orders::dsl::orders;
|
warning: unused import: `serde_json::json`
--> src/db.rs:3:5
|
3 | use serde_json::json;
| ^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
error[E0277]: the trait bound `&NewOrder: diesel::Insertable<table>` is not satisfied
--> src/db.rs:10:17
|
10 | .values(&new_order)
| ------ ^^^^^^^^^^ the trait `diesel::Insertable<table>` is not implemented for `&NewOrder`
| |
| required by a bound introduced by this call
|
note: required by a bound in `IncompleteInsertStatement::<T, Op>::values`
--> /Users/dylan/.cargo/registry/src/index.crates.io-6f17d22bba15001f/diesel-2.2.6/src/query_builder/insert_statement/mod.rs:115:12
|
113 | pub fn values<U>(self, records: U) -> InsertStatement<T, U::Values, Op>
| ------ required by a bound in this associated function
114 | where
115 | U: Insertable<T>,
| ^^^^^^^^^^^^^ required by this bound in `IncompleteInsertStatement::<T, Op>::values`
error[E0277]: the trait bound `(i32, i32, f64, NaiveDateTime, Value): FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not satisfied
--> src/db.rs:11:21
|
11 | .get_result(conn)
| ---------- ^^^^ the trait `FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not implemented for `(i32, i32, f64, NaiveDateTime, Value)`, which is required by `InsertStatement<table, _>: LoadQuery<'_, _, _>`
| |
| required by a bound introduced by this call
|
= help: the following other types implement trait `FromStaticSqlRow<ST, DB>`:
`(T0,)` implements `FromStaticSqlRow<(ST0,), __DB>`
`(T1, T0)` implements `FromStaticSqlRow<(ST1, ST0), __DB>`
`(T1, T2, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST0), __DB>`
`(T1, T2, T3, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST0), __DB>`
`(T1, T2, T3, T4, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST0), __DB>`
`(T1, T2, T3, T4, T5, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T7, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST7, ST0), __DB>`
and 24 others
note: required for `models::Order` to implement `diesel::Queryable<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
--> src/models.rs:6:10
|
6 | #[derive(Queryable, Selectable, Insertable, Serialize, Deserialize, Debug)]
| ^^^^^^^^^ unsatisfied trait bound introduced in this `derive` macro
...
9 | pub struct Order {
| ^^^^^
= note: required for `models::Order` to implement `FromSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
= note: required for `(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>)` to implement `load_dsl::private::CompatibleType<models::Order, Pg>`
= note: required for `InsertStatement<table, _>` to implement `LoadQuery<'_, diesel::PgConnection, models::Order>`
note: required by a bound in `get_result`
--> /Users/dylan/.cargo/registry/src/index.crates.io-6f17d22bba15001f/diesel-2.2.6/src/query_dsl/mod.rs:1722:15
|
1720 | fn get_result<'query, U>(self, conn: &mut Conn) -> QueryResult<U>
| ---------- required by a bound in this associated function
1721 | where
1722 | Self: LoadQuery<'query, Conn, U>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ required by this bound in `RunQueryDsl::get_result`
= note: this error originates in the derive macro `Queryable` (in Nightly builds, run with -Z macro-backtrace for more info)
error[E0277]: the trait bound `(i32, i32, f64, NaiveDateTime, Value): FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not satisfied
--> src/db.rs:17:16
|
17 | .first(conn)
| ----- ^^^^ the trait `FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not implemented for `(i32, i32, f64, NaiveDateTime, Value)`, which is required by `SelectStatement<FromClause<table>, query_builder::select_clause::DefaultSelectClause<FromClause<table>>, query_builder::distinct_clause::NoDistinctClause, query_builder::where_clause::WhereClause<diesel::expression::grouped::Grouped<diesel::expression::operators::Eq<columns::id, diesel::expression::bound::Bound<Integer, i32>>>>, query_builder::order_clause::NoOrderClause, LimitOffsetClause<LimitClause<diesel::expression::bound::Bound<BigInt, i64>>, NoOffsetClause>>: LoadQuery<'_, _, _>`
| |
| required by a bound introduced by this call
|
= help: the following other types implement trait `FromStaticSqlRow<ST, DB>`:
`(T0,)` implements `FromStaticSqlRow<(ST0,), __DB>`
`(T1, T0)` implements `FromStaticSqlRow<(ST1, ST0), __DB>`
`(T1, T2, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST0), __DB>`
`(T1, T2, T3, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST0), __DB>`
`(T1, T2, T3, T4, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST0), __DB>`
`(T1, T2, T3, T4, T5, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T7, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST7, ST0), __DB>`
and 24 others
note: required for `models::Order` to implement `diesel::Queryable<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
--> src/models.rs:6:10
|
6 | #[derive(Queryable, Selectable, Insertable, Serialize, Deserialize, Debug)]
| ^^^^^^^^^ unsatisfied trait bound introduced in this `derive` macro
...
9 | pub struct Order {
| ^^^^^
= note: required for `models::Order` to implement `FromSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
= note: required for `(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>)` to implement `load_dsl::private::CompatibleType<models::Order, Pg>`
= note: required for `SelectStatement<FromClause<table>, DefaultSelectClause<FromClause<table>>, NoDistinctClause, ..., ..., ...>` to implement `LoadQuery<'_, diesel::PgConnection, models::Order>`
note: required by a bound in `first`
--> /Users/dylan/.cargo/registry/src/index.crates.io-6f17d22bba15001f/diesel-2.2.6/src/query_dsl/mod.rs:1779:22
|
1776 | fn first<'query, U>(self, conn: &mut Conn) -> QueryResult<U>
| ----- required by a bound in this associated function
...
1779 | Limit<Self>: LoadQuery<'query, Conn, U>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ required by this bound in `RunQueryDsl::first`
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-0af85acd9e7b4e2f.long-type-11474480310476070344.txt'
= note: consider using `--verbose` to print the full type name to the console
= note: this error originates in the derive macro `Queryable` (in Nightly builds, run with -Z macro-backtrace for more info)
error[E0277]: the trait bound `(i32, i32, f64, NaiveDateTime, Value): FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not satisfied
--> src/db.rs:24:15
|
24 | .load(conn)
| ---- ^^^^ the trait `FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not implemented for `(i32, i32, f64, NaiveDateTime, Value)`, which is required by `SelectStatement<FromClause<table>, query_builder::select_clause::DefaultSelectClause<FromClause<table>>, query_builder::distinct_clause::NoDistinctClause, query_builder::where_clause::WhereClause<diesel::expression::grouped::Grouped<diesel::expression::operators::Eq<columns::user_id, diesel::expression::bound::Bound<Integer, i32>>>>>: LoadQuery<'_, _, _>`
| |
| required by a bound introduced by this call
|
= help: the following other types implement trait `FromStaticSqlRow<ST, DB>`:
`(T0,)` implements `FromStaticSqlRow<(ST0,), __DB>`
`(T1, T0)` implements `FromStaticSqlRow<(ST1, ST0), __DB>`
`(T1, T2, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST0), __DB>`
`(T1, T2, T3, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST0), __DB>`
`(T1, T2, T3, T4, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST0), __DB>`
`(T1, T2, T3, T4, T5, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T7, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST7, ST0), __DB>`
and 24 others
note: required for `models::Order` to implement `diesel::Queryable<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
--> src/models.rs:6:10
|
6 | #[derive(Queryable, Selectable, Insertable, Serialize, Deserialize, Debug)]
| ^^^^^^^^^ unsatisfied trait bound introduced in this `derive` macro
...
9 | pub struct Order {
| ^^^^^
= note: required for `models::Order` to implement `FromSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
= note: required for `(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>)` to implement `load_dsl::private::CompatibleType<models::Order, Pg>`
= note: required for `SelectStatement<FromClause<table>, DefaultSelectClause<FromClause<table>>, NoDistinctClause, WhereClause<...>>` to implement `LoadQuery<'_, diesel::PgConnection, models::Order>`
note: required by a bound in `diesel::RunQueryDsl::load`
--> /Users/dylan/.cargo/registry/src/index.crates.io-6f17d22bba15001f/diesel-2.2.6/src/query_dsl/mod.rs:1542:15
|
1540 | fn load<'query, U>(self, conn: &mut Conn) -> QueryResult<Vec<U>>
| ---- required by a bound in this associated function
1541 | where
1542 | Self: LoadQuery<'query, Conn, U>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ required by this bound in `RunQueryDsl::load`
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-0af85acd9e7b4e2f.long-type-14102635225686123243.txt'
= note: consider using `--verbose` to print the full type name to the console
= note: this error originates in the derive macro `Queryable` (in Nightly builds, run with -Z macro-backtrace for more info)
Some errors have detailed explanations: E0277, E0433.
For more information about an error, try `rustc --explain E0277`.
warning: `order-diesel-jsonb-example` (bin "order-diesel-jsonb-example") generated 1 warning
error: could not compile `order-diesel-jsonb-example` (bin "order-diesel-jsonb-example") due to 6 previous errors; 1 warning emitted
Fix: import orders from schema module
Although there are a lot of errors, the rust compiler is able to find the error and give us some hints.
error[E0433]: failed to resolve: use of undeclared crate or module `orders`
--> src/models.rs:7:23
|
7 | #[diesel(table_name = orders)]
| ^^^^^^ use of undeclared crate or module `orders`
|
help: a struct with a similar name exists
|
7 | #[diesel(table_name = Order)]
| ~~~~~
help: consider importing this struct through its public re-export
|
1 + use crate::schema::orders::dsl::orders;
Howerver, the hint is not correcty, We should import orders from schema module(use crate::schema::orders), not use crate::schema::orders::dsl::orders.
Let's import orders from schema module:
#![allow(unused)] fn main() { use crate::schema::orders; }
Or follow the IDE:


Also, we should add chrono and serde_json features for diesel dependency:
cargo add diesel -F chrono,serde_json
Updating crates.io index
Adding diesel v2.2.6 to dependencies
Features:
+ 32-column-tables
+ chrono
+ postgres
+ postgres_backend
+ serde_json
+ with-deprecated
- 128-column-tables
- 64-column-tables
- __with_asan_tests
- extras
- huge-tables
- i-implement-a-third-party-backend-and-opt-into-breaking-changes
- ipnet-address
- large-tables
- mysql
- mysql_backend
- mysqlclient-src
- network-address
- numeric
- pq-src
- quickcheck
- r2d2
- returning_clauses_for_sqlite_3_35
- sqlite
- time
- unstable
- uuid
- without-deprecated
Let's build it again.
> cargo build
Compiling diesel v2.2.6
Compiling order-diesel-jsonb-example v0.1.0
warning: unused import: `serde_json::json`
--> src/db.rs:3:5
|
3 | use serde_json::json;
| ^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
error[E0277]: the trait bound `Value: FromSqlRow<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>` is not satisfied
--> src/models.rs:16:19
|
16 | pub metadata: Value, // This will use JSONB
| ^^^^^ the trait `FromSql<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>` is not implemented for `Value`, which is required by `Value: FromSqlRow<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>`
|
= note: double check your type mappings via the documentation of `diesel::sql_types::Nullable<diesel::sql_types::Jsonb>`
= note: `diesel::sql_query` requires the loading target to column names for loading values.
You need to provide a type that explicitly derives `diesel::deserialize::QueryableByName`
= help: the following other types implement trait `FromSql<A, DB>`:
`Value` implements `FromSql<Json, Pg>`
`Value` implements `FromSql<diesel::sql_types::Jsonb, Pg>`
= note: required for `Value` to implement `diesel::Queryable<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>`
= note: required for `Value` to implement `FromSqlRow<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>`
= help: see issue #48214
error[E0277]: the trait bound `f64: FromSqlRow<diesel::sql_types::Numeric, Pg>` is not satisfied
--> src/models.rs:14:23
|
14 | pub total_amount: f64,
| ^^^ the trait `FromSql<diesel::sql_types::Numeric, Pg>` is not implemented for `f64`, which is required by `f64: FromSqlRow<diesel::sql_types::Numeric, Pg>`
|
= note: double check your type mappings via the documentation of `diesel::sql_types::Numeric`
= note: `diesel::sql_query` requires the loading target to column names for loading values.
You need to provide a type that explicitly derives `diesel::deserialize::QueryableByName`
= help: the trait `FromSql<Double, Pg>` is implemented for `f64`
= help: for that trait implementation, expected `Double`, found `diesel::sql_types::Numeric`
= note: required for `f64` to implement `diesel::Queryable<diesel::sql_types::Numeric, Pg>`
= note: required for `f64` to implement `FromSqlRow<diesel::sql_types::Numeric, Pg>`
= help: see issue #48214
error[E0277]: the trait bound `f64: diesel::Expression` is not satisfied
--> src/models.rs:8:33
|
8 | #[derive(Queryable, Selectable, Insertable, Serialize, Deserialize, Debug)]
| ^^^^^^^^^^ the trait `diesel::Expression` is not implemented for `f64`, which is required by `f64: AsExpression<diesel::sql_types::Numeric>`
|
= help: the following other types implement trait `diesel::Expression`:
&'a T
(T0, T1)
(T0, T1, T2)
(T0, T1, T2, T3)
(T0, T1, T2, T3, T4)
(T0, T1, T2, T3, T4, T5)
(T0, T1, T2, T3, T4, T5, T6)
(T0, T1, T2, T3, T4, T5, T6, T7)
and 137 others
= note: required for `f64` to implement `AsExpression<diesel::sql_types::Numeric>`
= note: this error originates in the derive macro `Insertable` (in Nightly builds, run with -Z macro-backtrace for more info)
error[E0277]: the trait bound `f64: diesel::Expression` is not satisfied
--> src/models.rs:8:33
|
8 | #[derive(Queryable, Selectable, Insertable, Serialize, Deserialize, Debug)]
| ^^^^^^^^^^ the trait `diesel::Expression` is not implemented for `f64`, which is required by `&'insert f64: AsExpression<diesel::sql_types::Numeric>`
|
= help: the following other types implement trait `diesel::Expression`:
&'a T
(T0, T1)
(T0, T1, T2)
(T0, T1, T2, T3)
(T0, T1, T2, T3, T4)
(T0, T1, T2, T3, T4, T5)
(T0, T1, T2, T3, T4, T5, T6)
(T0, T1, T2, T3, T4, T5, T6, T7)
and 137 others
= note: required for `&'insert f64` to implement `diesel::Expression`
= note: required for `&'insert f64` to implement `AsExpression<diesel::sql_types::Numeric>`
= note: this error originates in the derive macro `Insertable` (in Nightly builds, run with -Z macro-backtrace for more info)
error[E0277]: the trait bound `f64: diesel::Expression` is not satisfied
--> src/models.rs:19:10
|
19 | #[derive(Insertable, Deserialize)]
| ^^^^^^^^^^ the trait `diesel::Expression` is not implemented for `f64`, which is required by `f64: AsExpression<diesel::sql_types::Numeric>`
|
= help: the following other types implement trait `diesel::Expression`:
&'a T
(T0, T1)
(T0, T1, T2)
(T0, T1, T2, T3)
(T0, T1, T2, T3, T4)
(T0, T1, T2, T3, T4, T5)
(T0, T1, T2, T3, T4, T5, T6)
(T0, T1, T2, T3, T4, T5, T6, T7)
and 137 others
= note: required for `f64` to implement `AsExpression<diesel::sql_types::Numeric>`
= note: this error originates in the derive macro `Insertable` (in Nightly builds, run with -Z macro-backtrace for more info)
error[E0277]: the trait bound `f64: diesel::Expression` is not satisfied
--> src/models.rs:19:10
|
19 | #[derive(Insertable, Deserialize)]
| ^^^^^^^^^^ the trait `diesel::Expression` is not implemented for `f64`, which is required by `&'insert f64: AsExpression<diesel::sql_types::Numeric>`
|
= help: the following other types implement trait `diesel::Expression`:
&'a T
(T0, T1)
(T0, T1, T2)
(T0, T1, T2, T3)
(T0, T1, T2, T3, T4)
(T0, T1, T2, T3, T4, T5)
(T0, T1, T2, T3, T4, T5, T6)
(T0, T1, T2, T3, T4, T5, T6, T7)
and 137 others
= note: required for `&'insert f64` to implement `diesel::Expression`
= note: required for `&'insert f64` to implement `AsExpression<diesel::sql_types::Numeric>`
= note: this error originates in the derive macro `Insertable` (in Nightly builds, run with -Z macro-backtrace for more info)
error[E0277]: the trait bound `f64: diesel::Expression` is not satisfied
--> src/models.rs:14:9
|
14 | pub total_amount: f64,
| ^^^^^^^^^^^^ the trait `diesel::Expression` is not implemented for `f64`, which is required by `f64: AsExpression<diesel::sql_types::Numeric>`
|
= help: the following other types implement trait `diesel::Expression`:
&'a T
(T0, T1)
(T0, T1, T2)
(T0, T1, T2, T3)
(T0, T1, T2, T3, T4)
(T0, T1, T2, T3, T4, T5)
(T0, T1, T2, T3, T4, T5, T6)
(T0, T1, T2, T3, T4, T5, T6, T7)
and 137 others
= note: required for `f64` to implement `AsExpression<diesel::sql_types::Numeric>`
error[E0277]: the trait bound `f64: diesel::Expression` is not satisfied
--> src/models.rs:14:9
|
14 | pub total_amount: f64,
| ^^^^^^^^^^^^ the trait `diesel::Expression` is not implemented for `f64`, which is required by `&'insert f64: AsExpression<diesel::sql_types::Numeric>`
|
= help: the following other types implement trait `diesel::Expression`:
&'a T
(T0, T1)
(T0, T1, T2)
(T0, T1, T2, T3)
(T0, T1, T2, T3, T4)
(T0, T1, T2, T3, T4, T5)
(T0, T1, T2, T3, T4, T5, T6)
(T0, T1, T2, T3, T4, T5, T6, T7)
and 137 others
= note: required for `&'insert f64` to implement `diesel::Expression`
= note: required for `&'insert f64` to implement `AsExpression<diesel::sql_types::Numeric>`
error[E0277]: the trait bound `f64: diesel::Expression` is not satisfied
--> src/models.rs:23:9
|
23 | pub total_amount: f64,
| ^^^^^^^^^^^^ the trait `diesel::Expression` is not implemented for `f64`, which is required by `f64: AsExpression<diesel::sql_types::Numeric>`
|
= help: the following other types implement trait `diesel::Expression`:
&'a T
(T0, T1)
(T0, T1, T2)
(T0, T1, T2, T3)
(T0, T1, T2, T3, T4)
(T0, T1, T2, T3, T4, T5)
(T0, T1, T2, T3, T4, T5, T6)
(T0, T1, T2, T3, T4, T5, T6, T7)
and 137 others
= note: required for `f64` to implement `AsExpression<diesel::sql_types::Numeric>`
error[E0277]: the trait bound `f64: diesel::Expression` is not satisfied
--> src/models.rs:23:9
|
23 | pub total_amount: f64,
| ^^^^^^^^^^^^ the trait `diesel::Expression` is not implemented for `f64`, which is required by `&'insert f64: AsExpression<diesel::sql_types::Numeric>`
|
= help: the following other types implement trait `diesel::Expression`:
&'a T
(T0, T1)
(T0, T1, T2)
(T0, T1, T2, T3)
(T0, T1, T2, T3, T4)
(T0, T1, T2, T3, T4, T5)
(T0, T1, T2, T3, T4, T5, T6)
(T0, T1, T2, T3, T4, T5, T6, T7)
and 137 others
= note: required for `&'insert f64` to implement `diesel::Expression`
= note: required for `&'insert f64` to implement `AsExpression<diesel::sql_types::Numeric>`
error[E0277]: the trait bound `f64: diesel::Expression` is not satisfied
--> src/db.rs:10:10
|
10 | .values(&new_order)
| ^^^^^^ the trait `diesel::Expression` is not implemented for `f64`, which is required by `&f64: AsExpression<diesel::sql_types::Numeric>`
|
= help: the following other types implement trait `diesel::Expression`:
&'a T
(T0, T1)
(T0, T1, T2)
(T0, T1, T2, T3)
(T0, T1, T2, T3, T4)
(T0, T1, T2, T3, T4, T5)
(T0, T1, T2, T3, T4, T5, T6)
(T0, T1, T2, T3, T4, T5, T6, T7)
and 137 others
= note: required for `&f64` to implement `diesel::Expression`
= note: required for `&f64` to implement `AsExpression<diesel::sql_types::Numeric>`
error[E0277]: the trait bound `f64: AppearsOnTable<NoFromClause>` is not satisfied
--> src/db.rs:11:21
|
11 | .get_result(conn)
| ---------- ^^^^ the trait `AppearsOnTable<NoFromClause>` is not implemented for `f64`, which is required by `InsertStatement<table, query_builder::insert_statement::ValuesClause<(DefaultableColumnInsertValue<ColumnInsertValue<columns::user_id, diesel::expression::bound::Bound<Integer, &i32>>>, DefaultableColumnInsertValue<ColumnInsertValue<columns::total_amount, &f64>>, DefaultableColumnInsertValue<ColumnInsertValue<columns::metadata, diesel::expression::bound::Bound<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, &Value>>>), table>>: LoadQuery<'_, _, _>`
| |
| required by a bound introduced by this call
|
= help: the following other types implement trait `AppearsOnTable<QS>`:
`&'a T` implements `AppearsOnTable<QS>`
`(T0, T1)` implements `AppearsOnTable<QS>`
`(T0, T1, T2)` implements `AppearsOnTable<QS>`
`(T0, T1, T2, T3)` implements `AppearsOnTable<QS>`
`(T0, T1, T2, T3, T4)` implements `AppearsOnTable<QS>`
`(T0, T1, T2, T3, T4, T5)` implements `AppearsOnTable<QS>`
`(T0, T1, T2, T3, T4, T5, T6)` implements `AppearsOnTable<QS>`
`(T0, T1, T2, T3, T4, T5, T6, T7)` implements `AppearsOnTable<QS>`
and 137 others
= note: required for `&f64` to implement `AppearsOnTable<NoFromClause>`
= note: required for `DefaultableColumnInsertValue<ColumnInsertValue<columns::total_amount, &f64>>` to implement `InsertValues<_, table>`
= note: 1 redundant requirement hidden
= note: required for `(DefaultableColumnInsertValue<ColumnInsertValue<user_id, Bound<Integer, &i32>>>, ..., ...)` to implement `InsertValues<_, table>`
= note: required for `ValuesClause<(DefaultableColumnInsertValue<ColumnInsertValue<user_id, Bound<Integer, &i32>>>, ..., ...), ...>` to implement `QueryFragment<_>`
= note: 1 redundant requirement hidden
= note: required for `InsertStatement<table, ValuesClause<(DefaultableColumnInsertValue<...>, ..., ...), ...>, ..., ...>` to implement `QueryFragment<_>`
= note: required for `InsertStatement<table, ValuesClause<(DefaultableColumnInsertValue<ColumnInsertValue<..., ...>>, ..., ...), ...>>` to implement `LoadQuery<'_, _, _>`
note: required by a bound in `get_result`
--> /Users/dylan/.cargo/registry/src/index.crates.io-6f17d22bba15001f/diesel-2.2.6/src/query_dsl/mod.rs:1722:15
|
1720 | fn get_result<'query, U>(self, conn: &mut Conn) -> QueryResult<U>
| ---------- required by a bound in this associated function
1721 | where
1722 | Self: LoadQuery<'query, Conn, U>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ required by this bound in `RunQueryDsl::get_result`
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-f4ea1891b9fe6645.long-type-12046924592425831098.txt'
= note: consider using `--verbose` to print the full type name to the console
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-f4ea1891b9fe6645.long-type-16463581489430962252.txt'
= note: consider using `--verbose` to print the full type name to the console
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-f4ea1891b9fe6645.long-type-8702231718444061151.txt'
= note: consider using `--verbose` to print the full type name to the console
error[E0271]: type mismatch resolving `<Pg as SqlDialect>::InsertWithDefaultKeyword == NotSpecialized`
--> src/db.rs:11:21
|
11 | .get_result(conn)
| ---------- ^^^^ expected `NotSpecialized`, found `IsoSqlDefaultKeyword`
| |
| required by a bound introduced by this call
|
= note: required for `DefaultableColumnInsertValue<ColumnInsertValue<columns::total_amount, &f64>>` to implement `QueryFragment<Pg>`
= note: required for `DefaultableColumnInsertValue<ColumnInsertValue<columns::total_amount, &f64>>` to implement `InsertValues<Pg, table>`
= note: 3 redundant requirements hidden
= note: required for `InsertStatement<table, ValuesClause<(DefaultableColumnInsertValue<...>, ..., ...), ...>, ..., ...>` to implement `QueryFragment<Pg>`
= note: required for `InsertStatement<table, ValuesClause<(DefaultableColumnInsertValue<ColumnInsertValue<..., ...>>, ..., ...), ...>>` to implement `LoadQuery<'_, diesel::PgConnection, _>`
note: required by a bound in `get_result`
--> /Users/dylan/.cargo/registry/src/index.crates.io-6f17d22bba15001f/diesel-2.2.6/src/query_dsl/mod.rs:1722:15
|
1720 | fn get_result<'query, U>(self, conn: &mut Conn) -> QueryResult<U>
| ---------- required by a bound in this associated function
1721 | where
1722 | Self: LoadQuery<'query, Conn, U>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ required by this bound in `RunQueryDsl::get_result`
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-f4ea1891b9fe6645.long-type-12046924592425831098.txt'
= note: consider using `--verbose` to print the full type name to the console
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-f4ea1891b9fe6645.long-type-9860913280699406432.txt'
= note: consider using `--verbose` to print the full type name to the console
error[E0277]: the trait bound `(i32, i32, f64, NaiveDateTime, Value): FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not satisfied
--> src/db.rs:11:21
|
11 | .get_result(conn)
| ---------- ^^^^ the trait `FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not implemented for `(i32, i32, f64, NaiveDateTime, Value)`, which is required by `InsertStatement<table, query_builder::insert_statement::ValuesClause<(DefaultableColumnInsertValue<ColumnInsertValue<columns::user_id, diesel::expression::bound::Bound<Integer, &i32>>>, DefaultableColumnInsertValue<ColumnInsertValue<columns::total_amount, &f64>>, DefaultableColumnInsertValue<ColumnInsertValue<columns::metadata, diesel::expression::bound::Bound<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, &Value>>>), table>>: LoadQuery<'_, _, _>`
| |
| required by a bound introduced by this call
|
= help: the following other types implement trait `FromStaticSqlRow<ST, DB>`:
`(T0,)` implements `FromStaticSqlRow<(ST0,), __DB>`
`(T1, T0)` implements `FromStaticSqlRow<(ST1, ST0), __DB>`
`(T1, T2, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST0), __DB>`
`(T1, T2, T3, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST0), __DB>`
`(T1, T2, T3, T4, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST0), __DB>`
`(T1, T2, T3, T4, T5, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T7, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST7, ST0), __DB>`
and 24 others
note: required for `models::Order` to implement `diesel::Queryable<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
--> src/models.rs:8:10
|
8 | #[derive(Queryable, Selectable, Insertable, Serialize, Deserialize, Debug)]
| ^^^^^^^^^ unsatisfied trait bound introduced in this `derive` macro
...
11 | pub struct Order {
| ^^^^^
= note: required for `models::Order` to implement `FromSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
= note: required for `(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>)` to implement `load_dsl::private::CompatibleType<models::Order, Pg>`
= note: required for `InsertStatement<table, ValuesClause<(DefaultableColumnInsertValue<ColumnInsertValue<..., ...>>, ..., ...), ...>>` to implement `LoadQuery<'_, diesel::PgConnection, models::Order>`
note: required by a bound in `get_result`
--> /Users/dylan/.cargo/registry/src/index.crates.io-6f17d22bba15001f/diesel-2.2.6/src/query_dsl/mod.rs:1722:15
|
1720 | fn get_result<'query, U>(self, conn: &mut Conn) -> QueryResult<U>
| ---------- required by a bound in this associated function
1721 | where
1722 | Self: LoadQuery<'query, Conn, U>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ required by this bound in `RunQueryDsl::get_result`
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-f4ea1891b9fe6645.long-type-12046924592425831098.txt'
= note: consider using `--verbose` to print the full type name to the console
= note: this error originates in the derive macro `Queryable` (in Nightly builds, run with -Z macro-backtrace for more info)
error[E0277]: the trait bound `(i32, i32, f64, NaiveDateTime, Value): FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not satisfied
--> src/db.rs:17:16
|
17 | .first(conn)
| ----- ^^^^ the trait `FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not implemented for `(i32, i32, f64, NaiveDateTime, Value)`, which is required by `SelectStatement<FromClause<table>, query_builder::select_clause::DefaultSelectClause<FromClause<table>>, query_builder::distinct_clause::NoDistinctClause, query_builder::where_clause::WhereClause<diesel::expression::grouped::Grouped<diesel::expression::operators::Eq<columns::id, diesel::expression::bound::Bound<Integer, i32>>>>, query_builder::order_clause::NoOrderClause, LimitOffsetClause<LimitClause<diesel::expression::bound::Bound<BigInt, i64>>, NoOffsetClause>>: LoadQuery<'_, _, _>`
| |
| required by a bound introduced by this call
|
= help: the following other types implement trait `FromStaticSqlRow<ST, DB>`:
`(T0,)` implements `FromStaticSqlRow<(ST0,), __DB>`
`(T1, T0)` implements `FromStaticSqlRow<(ST1, ST0), __DB>`
`(T1, T2, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST0), __DB>`
`(T1, T2, T3, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST0), __DB>`
`(T1, T2, T3, T4, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST0), __DB>`
`(T1, T2, T3, T4, T5, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T7, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST7, ST0), __DB>`
and 24 others
note: required for `models::Order` to implement `diesel::Queryable<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
--> src/models.rs:8:10
|
8 | #[derive(Queryable, Selectable, Insertable, Serialize, Deserialize, Debug)]
| ^^^^^^^^^ unsatisfied trait bound introduced in this `derive` macro
...
11 | pub struct Order {
| ^^^^^
= note: required for `models::Order` to implement `FromSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
= note: required for `(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>)` to implement `load_dsl::private::CompatibleType<models::Order, Pg>`
= note: required for `SelectStatement<FromClause<table>, DefaultSelectClause<FromClause<table>>, NoDistinctClause, ..., ..., ...>` to implement `LoadQuery<'_, diesel::PgConnection, models::Order>`
note: required by a bound in `first`
--> /Users/dylan/.cargo/registry/src/index.crates.io-6f17d22bba15001f/diesel-2.2.6/src/query_dsl/mod.rs:1779:22
|
1776 | fn first<'query, U>(self, conn: &mut Conn) -> QueryResult<U>
| ----- required by a bound in this associated function
...
1779 | Limit<Self>: LoadQuery<'query, Conn, U>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ required by this bound in `RunQueryDsl::first`
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-f4ea1891b9fe6645.long-type-13104014775257459898.txt'
= note: consider using `--verbose` to print the full type name to the console
= note: this error originates in the derive macro `Queryable` (in Nightly builds, run with -Z macro-backtrace for more info)
error[E0277]: the trait bound `(i32, i32, f64, NaiveDateTime, Value): FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not satisfied
--> src/db.rs:24:15
|
24 | .load(conn)
| ---- ^^^^ the trait `FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not implemented for `(i32, i32, f64, NaiveDateTime, Value)`, which is required by `SelectStatement<FromClause<table>, query_builder::select_clause::DefaultSelectClause<FromClause<table>>, query_builder::distinct_clause::NoDistinctClause, query_builder::where_clause::WhereClause<diesel::expression::grouped::Grouped<diesel::expression::operators::Eq<columns::user_id, diesel::expression::bound::Bound<Integer, i32>>>>>: LoadQuery<'_, _, _>`
| |
| required by a bound introduced by this call
|
= help: the following other types implement trait `FromStaticSqlRow<ST, DB>`:
`(T0,)` implements `FromStaticSqlRow<(ST0,), __DB>`
`(T1, T0)` implements `FromStaticSqlRow<(ST1, ST0), __DB>`
`(T1, T2, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST0), __DB>`
`(T1, T2, T3, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST0), __DB>`
`(T1, T2, T3, T4, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST0), __DB>`
`(T1, T2, T3, T4, T5, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T7, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST7, ST0), __DB>`
and 24 others
note: required for `models::Order` to implement `diesel::Queryable<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
--> src/models.rs:8:10
|
8 | #[derive(Queryable, Selectable, Insertable, Serialize, Deserialize, Debug)]
| ^^^^^^^^^ unsatisfied trait bound introduced in this `derive` macro
...
11 | pub struct Order {
| ^^^^^
= note: required for `models::Order` to implement `FromSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
= note: required for `(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>)` to implement `load_dsl::private::CompatibleType<models::Order, Pg>`
= note: required for `SelectStatement<FromClause<table>, DefaultSelectClause<FromClause<table>>, NoDistinctClause, WhereClause<...>>` to implement `LoadQuery<'_, diesel::PgConnection, models::Order>`
note: required by a bound in `diesel::RunQueryDsl::load`
--> /Users/dylan/.cargo/registry/src/index.crates.io-6f17d22bba15001f/diesel-2.2.6/src/query_dsl/mod.rs:1542:15
|
1540 | fn load<'query, U>(self, conn: &mut Conn) -> QueryResult<Vec<U>>
| ---- required by a bound in this associated function
1541 | where
1542 | Self: LoadQuery<'query, Conn, U>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ required by this bound in `RunQueryDsl::load`
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-f4ea1891b9fe6645.long-type-451606845660155404.txt'
= note: consider using `--verbose` to print the full type name to the console
= note: this error originates in the derive macro `Queryable` (in Nightly builds, run with -Z macro-backtrace for more info)
Some errors have detailed explanations: E0271, E0277.
For more information about an error, try `rustc --explain E0271`.
warning: `order-diesel-jsonb-example` (bin "order-diesel-jsonb-example") generated 1 warning
error: could not compile `order-diesel-jsonb-example` (bin "order-diesel-jsonb-example") due to 24 previous errors; 1 warning emitted
Fix: change total_amount type from f64 to BigDecimal
That's a lot of errors, let's fix it step by step.
First, let's see the error for total_amount field
error[E0277]: the trait bound `f64: FromSqlRow<diesel::sql_types::Numeric, Pg>` is not satisfied
--> src/models.rs:14:23
|
14 | pub total_amount: f64,
| ^^^ the trait `FromSql<diesel::sql_types::Numeric, Pg>` is not implemented for `f64`, which is required by `f64: FromSqlRow<diesel::sql_types::Numeric, Pg>`
|
= note: double check your type mappings via the documentation of `diesel::sql_types::Numeric`
= note: `diesel::sql_query` requires the loading target to column names for loading values.
You need to provide a type that explicitly derives `diesel::deserialize::QueryableByName`
= help: the trait `FromSql<Double, Pg>` is implemented for `f64`
= help: for that trait implementation, expected `Double`, found `diesel::sql_types::Numeric`
= note: required for `f64` to implement `diesel::Queryable<diesel::sql_types::Numeric, Pg>`
= note: required for `f64` to implement `FromSqlRow<diesel::sql_types::Numeric, Pg>`
= help: see issue #48214
error[E0277]: the trait bound `f64: diesel::Expression` is not satisfied
--> src/models.rs:8:33
|
8 | #[derive(Queryable, Selectable, Insertable, Serialize, Deserialize, Debug)]
| ^^^^^^^^^^ the trait `diesel::Expression` is not implemented for `f64`, which is required by `f64: AsExpression<diesel::sql_types::Numeric>`
|
= help: the following other types implement trait `diesel::Expression`:
&'a T
(T0, T1)
(T0, T1, T2)
(T0, T1, T2, T3)
(T0, T1, T2, T3, T4)
(T0, T1, T2, T3, T4, T5)
(T0, T1, T2, T3, T4, T5, T6)
(T0, T1, T2, T3, T4, T5, T6, T7)
and 137 others
= note: required for `f64` to implement `AsExpression<diesel::sql_types::Numeric>`
= note: this error originates in the derive macro `Insertable` (in Nightly builds, run with -Z macro-backtrace for more info)
Notice, in migration file, total_amount column type is Decimal, and diesel will use Numeric type in it's SQL query.
Here is the source code of diesel::sql_types::Numeric
#![allow(unused)] fn main() { /// The arbitrary precision numeric SQL type. /// /// This type is only supported on PostgreSQL and MySQL. /// On SQLite, [`Double`] should be used instead. /// /// ### [`ToSql`](crate::serialize::ToSql) impls /// /// - [`bigdecimal::BigDecimal`] with `feature = ["numeric"]` /// /// ### [`FromSql`](crate::deserialize::FromSql) impls /// /// - [`bigdecimal::BigDecimal`] with `feature = ["numeric"]` /// /// [`bigdecimal::BigDecimal`]: /bigdecimal/struct.BigDecimal.html #[derive(Debug, Clone, Copy, Default, QueryId, SqlType)] #[diesel(postgres_type(oid = 1700, array_oid = 1231))] #[diesel(mysql_type(name = "Numeric"))] #[diesel(sqlite_type(name = "Double"))] pub struct Numeric; }
We should tell diesel to use numeric type.
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
user_id INTEGER NOT NULL,
total_amount DECIMAL(10, 2) NOT NULL, -- 👈👈👈👈👈👈 🙋
order_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
metadata JSONB
);
Let's enable numeric feature to diesel dependency to correctly deserialize total_amount field.
cargo add diesel -F numeric
Updating crates.io index
Adding diesel v2.2.6 to dependencies
Features:
+ 32-column-tables
+ chrono
+ numeric
+ postgres
+ postgres_backend
+ serde_json
+ with-deprecated
- 128-column-tables
- 64-column-tables
- __with_asan_tests
- extras
- huge-tables
- i-implement-a-third-party-backend-and-opt-into-breaking-changes
- ipnet-address
- large-tables
- mysql
- mysql_backend
- mysqlclient-src
- network-address
- pq-src
- quickcheck
- r2d2
- returning_clauses_for_sqlite_3_35
- sqlite
- time
- unstable
- uuid
- without-deprecated
Locking 4 packages to latest compatible versions
Adding bigdecimal v0.4.7
Adding libm v0.2.11
Adding num-bigint v0.4.6
Adding num-integer v0.1.46
Now, let's build it again.
Still lots of errors:
Compiling order-diesel-jsonb-example v0.1.0
warning: unused import: `serde_json::json`
--> src/db.rs:3:5
|
3 | use serde_json::json;
| ^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
error[E0277]: the trait bound `Value: FromSqlRow<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>` is not satisfied
--> src/models.rs:18:19
|
18 | pub metadata: Value, // This will use JSONB
| ^^^^^ the trait `FromSql<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>` is not implemented for `Value`, which is required by `Value: FromSqlRow<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>`
|
= note: double check your type mappings via the documentation of `diesel::sql_types::Nullable<diesel::sql_types::Jsonb>`
= note: `diesel::sql_query` requires the loading target to column names for loading values.
You need to provide a type that explicitly derives `diesel::deserialize::QueryableByName`
= help: the following other types implement trait `FromSql<A, DB>`:
`Value` implements `FromSql<Json, Pg>`
`Value` implements `FromSql<diesel::sql_types::Jsonb, Pg>`
= note: required for `Value` to implement `diesel::Queryable<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>`
= note: required for `Value` to implement `FromSqlRow<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>`
= help: see issue #48214
error[E0277]: the trait bound `(i32, i32, BigDecimal, NaiveDateTime, Value): FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not satisfied
--> src/db.rs:11:21
|
11 | .get_result(conn)
| ---------- ^^^^ the trait `FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not implemented for `(i32, i32, BigDecimal, NaiveDateTime, Value)`, which is required by `InsertStatement<table, query_builder::insert_statement::ValuesClause<(DefaultableColumnInsertValue<ColumnInsertValue<columns::user_id, diesel::expression::bound::Bound<Integer, &i32>>>, DefaultableColumnInsertValue<ColumnInsertValue<columns::total_amount, diesel::expression::bound::Bound<diesel::sql_types::Numeric, &BigDecimal>>>, DefaultableColumnInsertValue<ColumnInsertValue<columns::metadata, diesel::expression::bound::Bound<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, &Value>>>), table>>: LoadQuery<'_, _, _>`
| |
| required by a bound introduced by this call
|
= help: the following other types implement trait `FromStaticSqlRow<ST, DB>`:
`(T0,)` implements `FromStaticSqlRow<(ST0,), __DB>`
`(T1, T0)` implements `FromStaticSqlRow<(ST1, ST0), __DB>`
`(T1, T2, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST0), __DB>`
`(T1, T2, T3, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST0), __DB>`
`(T1, T2, T3, T4, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST0), __DB>`
`(T1, T2, T3, T4, T5, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T7, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST7, ST0), __DB>`
and 24 others
note: required for `models::Order` to implement `diesel::Queryable<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
--> src/models.rs:9:10
|
9 | #[derive(Queryable, Selectable, Insertable, Serialize, Deserialize, Debug)]
| ^^^^^^^^^ unsatisfied trait bound introduced in this `derive` macro
...
12 | pub struct Order {
| ^^^^^
= note: required for `models::Order` to implement `FromSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
= note: required for `(Integer, Integer, Numeric, Timestamp, Nullable<Jsonb>)` to implement `load_dsl::private::CompatibleType<models::Order, Pg>`
= note: required for `InsertStatement<table, ValuesClause<(..., ..., ...), ...>>` to implement `LoadQuery<'_, diesel::PgConnection, models::Order>`
note: required by a bound in `get_result`
--> /Users/dylan/.cargo/registry/src/index.crates.io-6f17d22bba15001f/diesel-2.2.6/src/query_dsl/mod.rs:1722:15
|
1720 | fn get_result<'query, U>(self, conn: &mut Conn) -> QueryResult<U>
| ---------- required by a bound in this associated function
1721 | where
1722 | Self: LoadQuery<'query, Conn, U>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ required by this bound in `RunQueryDsl::get_result`
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-cdb3b656aa15b263.long-type-9790004947608049719.txt'
= note: consider using `--verbose` to print the full type name to the console
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-cdb3b656aa15b263.long-type-2452195376562117312.txt'
= note: consider using `--verbose` to print the full type name to the console
= note: this error originates in the derive macro `Queryable` (in Nightly builds, run with -Z macro-backtrace for more info)
error[E0277]: the trait bound `(i32, i32, BigDecimal, NaiveDateTime, Value): FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not satisfied
--> src/db.rs:17:16
|
17 | .first(conn)
| ----- ^^^^ the trait `FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not implemented for `(i32, i32, BigDecimal, NaiveDateTime, Value)`, which is required by `SelectStatement<FromClause<table>, query_builder::select_clause::DefaultSelectClause<FromClause<table>>, query_builder::distinct_clause::NoDistinctClause, query_builder::where_clause::WhereClause<diesel::expression::grouped::Grouped<diesel::expression::operators::Eq<columns::id, diesel::expression::bound::Bound<Integer, i32>>>>, query_builder::order_clause::NoOrderClause, LimitOffsetClause<LimitClause<diesel::expression::bound::Bound<diesel::sql_types::BigInt, i64>>, NoOffsetClause>>: LoadQuery<'_, _, _>`
| |
| required by a bound introduced by this call
|
= help: the following other types implement trait `FromStaticSqlRow<ST, DB>`:
`(T0,)` implements `FromStaticSqlRow<(ST0,), __DB>`
`(T1, T0)` implements `FromStaticSqlRow<(ST1, ST0), __DB>`
`(T1, T2, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST0), __DB>`
`(T1, T2, T3, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST0), __DB>`
`(T1, T2, T3, T4, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST0), __DB>`
`(T1, T2, T3, T4, T5, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T7, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST7, ST0), __DB>`
and 24 others
note: required for `models::Order` to implement `diesel::Queryable<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
--> src/models.rs:9:10
|
9 | #[derive(Queryable, Selectable, Insertable, Serialize, Deserialize, Debug)]
| ^^^^^^^^^ unsatisfied trait bound introduced in this `derive` macro
...
12 | pub struct Order {
| ^^^^^
= note: required for `models::Order` to implement `FromSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
= note: required for `(Integer, Integer, Numeric, Timestamp, Nullable<Jsonb>)` to implement `load_dsl::private::CompatibleType<models::Order, Pg>`
= note: required for `SelectStatement<FromClause<table>, DefaultSelectClause<...>, ..., ..., ..., ...>` to implement `LoadQuery<'_, diesel::PgConnection, models::Order>`
note: required by a bound in `first`
--> /Users/dylan/.cargo/registry/src/index.crates.io-6f17d22bba15001f/diesel-2.2.6/src/query_dsl/mod.rs:1779:22
|
1776 | fn first<'query, U>(self, conn: &mut Conn) -> QueryResult<U>
| ----- required by a bound in this associated function
...
1779 | Limit<Self>: LoadQuery<'query, Conn, U>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ required by this bound in `RunQueryDsl::first`
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-cdb3b656aa15b263.long-type-12865645728958808655.txt'
= note: consider using `--verbose` to print the full type name to the console
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-cdb3b656aa15b263.long-type-2452195376562117312.txt'
= note: consider using `--verbose` to print the full type name to the console
= note: this error originates in the derive macro `Queryable` (in Nightly builds, run with -Z macro-backtrace for more info)
error[E0277]: the trait bound `(i32, i32, BigDecimal, NaiveDateTime, Value): FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not satisfied
--> src/db.rs:24:15
|
24 | .load(conn)
| ---- ^^^^ the trait `FromStaticSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>` is not implemented for `(i32, i32, BigDecimal, NaiveDateTime, Value)`, which is required by `SelectStatement<FromClause<table>, query_builder::select_clause::DefaultSelectClause<FromClause<table>>, query_builder::distinct_clause::NoDistinctClause, query_builder::where_clause::WhereClause<diesel::expression::grouped::Grouped<diesel::expression::operators::Eq<columns::user_id, diesel::expression::bound::Bound<Integer, i32>>>>>: LoadQuery<'_, _, _>`
| |
| required by a bound introduced by this call
|
= help: the following other types implement trait `FromStaticSqlRow<ST, DB>`:
`(T0,)` implements `FromStaticSqlRow<(ST0,), __DB>`
`(T1, T0)` implements `FromStaticSqlRow<(ST1, ST0), __DB>`
`(T1, T2, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST0), __DB>`
`(T1, T2, T3, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST0), __DB>`
`(T1, T2, T3, T4, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST0), __DB>`
`(T1, T2, T3, T4, T5, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST0), __DB>`
`(T1, T2, T3, T4, T5, T6, T7, T0)` implements `FromStaticSqlRow<(ST1, ST2, ST3, ST4, ST5, ST6, ST7, ST0), __DB>`
and 24 others
note: required for `models::Order` to implement `diesel::Queryable<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
--> src/models.rs:9:10
|
9 | #[derive(Queryable, Selectable, Insertable, Serialize, Deserialize, Debug)]
| ^^^^^^^^^ unsatisfied trait bound introduced in this `derive` macro
...
12 | pub struct Order {
| ^^^^^
= note: required for `models::Order` to implement `FromSqlRow<(Integer, Integer, diesel::sql_types::Numeric, diesel::sql_types::Timestamp, diesel::sql_types::Nullable<diesel::sql_types::Jsonb>), Pg>`
= note: required for `(Integer, Integer, Numeric, Timestamp, Nullable<Jsonb>)` to implement `load_dsl::private::CompatibleType<models::Order, Pg>`
= note: required for `SelectStatement<FromClause<table>, DefaultSelectClause<FromClause<...>>, ..., ...>` to implement `LoadQuery<'_, diesel::PgConnection, models::Order>`
note: required by a bound in `diesel::RunQueryDsl::load`
--> /Users/dylan/.cargo/registry/src/index.crates.io-6f17d22bba15001f/diesel-2.2.6/src/query_dsl/mod.rs:1542:15
|
1540 | fn load<'query, U>(self, conn: &mut Conn) -> QueryResult<Vec<U>>
| ---- required by a bound in this associated function
1541 | where
1542 | Self: LoadQuery<'query, Conn, U>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ required by this bound in `RunQueryDsl::load`
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-cdb3b656aa15b263.long-type-17907481964813576637.txt'
= note: consider using `--verbose` to print the full type name to the console
= note: the full name for the type has been written to '/Users/dylan/projects/order-diesel-jsonb-example/target/debug/deps/order_diesel_jsonb_example-cdb3b656aa15b263.long-type-2452195376562117312.txt'
= note: consider using `--verbose` to print the full type name to the console
= note: this error originates in the derive macro `Queryable` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
warning: `order-diesel-jsonb-example` (bin "order-diesel-jsonb-example") generated 1 warning
error: could not compile `order-diesel-jsonb-example` (bin "order-diesel-jsonb-example") due to 4 previous errors; 1 warning emitted
Fix: Change metadata type from Value to Option<Value>
Next, let's see the error for metadata field.
> cargo build
Compiling order-diesel-jsonb-example v0.1.0
warning: unused import: `serde_json::json`
--> src/db.rs:3:5
|
3 | use serde_json::json;
| ^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
error[E0277]: the trait bound `Value: FromSqlRow<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>` is not satisfied
--> src/models.rs:18:19
|
18 | pub metadata: Value, // This will use JSONB
| ^^^^^ the trait `FromSql<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>` is not implemented for `Value`, which is required by `Value: FromSqlRow<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>`
|
= note: double check your type mappings via the documentation of `diesel::sql_types::Nullable<diesel::sql_types::Jsonb>`
= note: `diesel::sql_query` requires the loading target to column names for loading values.
You need to provide a type that explicitly derives `diesel::deserialize::QueryableByName`
= help: the following other types implement trait `FromSql<A, DB>`:
`Value` implements `FromSql<Json, Pg>`
`Value` implements `FromSql<diesel::sql_types::Jsonb, Pg>`
= note: required for `Value` to implement `diesel::Queryable<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>`
= note: required for `Value` to implement `FromSqlRow<diesel::sql_types::Nullable<diesel::sql_types::Jsonb>, Pg>`
= help: see issue #48214
The reason for that error is that we declare metadata as NOT NULL in migration sql file, which is not aligned with metadata type in model defination. The fix is easy by changing datetype for metadata from Value to Option<Value>.
#![allow(unused)] fn main() { #[derive(Queryable, Selectable, Insertable, Serialize, Deserialize, Debug)] #[diesel(table_name = orders)] #[diesel(check_for_backend(diesel::pg::Pg))] pub struct Order { pub id: i32, pub user_id: i32, // pub total_amount: f64, pub total_amount: BigDecimal, pub order_date: NaiveDateTime, // pub metadata: Value, // This will use JSONB ❌ pub metadata: Option<Value>, // This will use JSONB ✅ } }
metadata column type:
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
user_id INTEGER NOT NULL,
total_amount DECIMAL(10, 2) NOT NULL,
order_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
metadata JSONB -- 👈👈👈👈👈👈 🙋
);
Now, let's build it.
Compiling order-diesel-jsonb-example v0.1.0
warning: unused import: `serde_json::json`
--> src/db.rs:3:5
|
3 | use serde_json::json;
| ^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: function `get_order_by_id` is never used
--> src/db.rs:15:8
|
15 | pub fn get_order_by_id(conn: &mut PgConnection, order_id: i32) -> Result<Order> {
| ^^^^^^^^^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: function `get_orders_by_user` is never used
--> src/db.rs:21:8
|
21 | pub fn get_orders_by_user(conn: &mut PgConnection, user_id_param: i32) -> Result<Vec<Order>> {
| ^^^^^^^^^^^^^^^^^^
warning: `order-diesel-jsonb-example` (bin "order-diesel-jsonb-example") generated 3 warnings (run `cargo fix --bin "order-diesel-jsonb-example"` to apply 1 suggestion)
🎉🎉🎉
We could also add NOT NULL to metadata column type and keep metadata as Value in model definition.
Create orders
Finally, let's create some orders and see the result in database.
cargo run --bin order-diesel-jsonb-example
Connect the database using psql diesel_demo and see the result:
dylan@/tmp:diesel_demo> \d
+--------+----------------------------+----------+-------+
| Schema | Name | Type | Owner |
|--------+----------------------------+----------+-------|
| public | __diesel_schema_migrations | table | dylan |
| public | orders | table | dylan |
| public | orders_id_seq | sequence | dylan |
+--------+----------------------------+----------+-------+
SELECT 3
Time: 0.008s
dylan@/tmp:diesel_demo> select * from orders;
+----+---------+--------------+----------------------------+-----------------------------------------------------------------------------+
| id | user_id | total_amount | order_date | metadata |
|----+---------+--------------+----------------------------+-----------------------------------------------------------------------------|
| 1 | 1 | 0.80 | 2024-12-17 03:05:10.732408 | {"items": ["book", "pen"], "gift_wrap": true, "shipping_method": "express"} |
+----+---------+--------------+----------------------------+-----------------------------------------------------------------------------+
SELECT 1
Time: 0.006s
Query orders
As a next step, let's see how to query orders.
Below is the query result for SELECT * FROM orders WHERE metadata @> '{"address": "Article Circle Expressway 2"}':
dylan@/tmp:diesel_demo> select * from orders;
+----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------+
| id | user_id | total_amount | order_date | metadata |
|----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------|
| 1 | 1 | 0.80 | 2024-12-17 03:05:10.732408 | {"items": ["book", "pen"], "gift_wrap": true, "shipping_method": "express"} |
| 2 | 1 | 0.80 | 2024-12-17 03:08:16.591275 | {"items": ["book", "pen"], "gift_wrap": true, "shipping_method": "express"} |
| 3 | 1 | 0.80 | 2024-12-17 05:46:41.173109 | {"items": ["book", "pen"], "address": "123 Main St, Anytown, USA", "gift_wrap": true, "shipping_method": "express"} |
| 4 | 1 | 0.80 | 2024-12-17 05:47:40.956483 | {"items": ["book", "pen"], "address": "Article Circle Expressway 2", "gift_wrap": true, "shipping_method": "express"} |
+----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------+
SELECT 4
Time: 0.006s
dylan@/tmp:diesel_demo>
Time: 0.000s
dylan@/tmp:diesel_demo>
Time: 0.000s
dylan@/tmp:diesel_demo> SELECT * FROM orders WHERE metadata @> '{"address": "Article Circle Expressway 2"}';
+----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------+
| id | user_id | total_amount | order_date | metadata |
|----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------|
| 4 | 1 | 0.80 | 2024-12-17 05:47:40.956483 | {"items": ["book", "pen"], "address": "Article Circle Expressway 2", "gift_wrap": true, "shipping_method": "express"} |
+----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------+
SELECT 1
Time: 0.013s
Let's see how we can archieve the same result using Diesel.
We can use operators for jsonb types:
#![allow(unused)] fn main() { pub fn get_orders_by_address( conn: &mut PgConnection, metadata: &serde_json::Value, ) -> QueryResult<Vec<Order>> { use crate::schema::orders::dsl::{metadata as orders_metadata, orders}; let query = orders.filter(orders_metadata.contains(metadata)); let debug = diesel::debug_query::<diesel::pg::Pg, _>(&query); println!("The insert query: {:#?}", debug); query.get_results(conn) } }
The code above uses contains jsonb operator(@>) to query the orders by metadata. You can use {"address": "Article Circle Expressway 2"} as the creteria.
Now, let's modify main.rs to call the get_orders_by_address method.
fn main() { let conn = &mut establish_connection(); // // Example usage // let new_order = models::NewOrder { // user_id: 1, // // total_amount: 99.99, // total_amount: BigDecimal::from_str("0.80").unwrap(), // metadata: serde_json::json!({ // "items": ["book", "pen"], // "shipping_method": "express", // "gift_wrap": true, // "address": "Article Circle Expressway 2", // // "address": "123 Main St, Anytown, USA", // }), // }; // match db::create_order(conn, new_order) { // Ok(order) => println!("Created order: {:?}", order), // Err(e) => eprintln!("Error creating order: {}", e), // } let metadata_address: serde_json::Value = serde_json::json!({"address": "Article Circle Expressway 2"}); match db::get_orders_by_address(conn, &metadata_address) { Ok(orders) => println!("Orders by address: {:#?}", orders), Err(e) => eprintln!("Error getting orders by address: {}", e), } }
Running the query using contains jsonb operator(@>) gives us the same result. Notice the @> operator in the SQL query.
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.46s
Running `target/debug/order-diesel-jsonb-example`
The insert query: Query {
sql: "SELECT \"orders\".\"id\", \"orders\".\"user_id\", \"orders\".\"total_amount\", \"orders\".\"order_date\", \"orders\".\"metadata\" FROM \"orders\" WHERE (\"orders\".\"metadata\" @> $1)",
binds: [
Object {
"address": String("Article Circle Expressway 2"),
},
],
}
Orders by address: [
Order {
id: 4,
user_id: 1,
total_amount: BigDecimal("80e-2"),
order_date: 2024-12-17T05:47:40.956483,
metadata: Some(
Object {
"address": String("Article Circle Expressway 2"),
"gift_wrap": Bool(true),
"items": Array [
String("book"),
String("pen"),
],
"shipping_method": String("express"),
},
),
},
]
Below is the source code for contains method in diesel source code.
/// PostgreSQL specific methods present on JSONB expressions. #[cfg(feature = "postgres_backend")] pub trait PgJsonbExpressionMethods: Expression + Sized { /// Creates a PostgreSQL `@>` expression. /// /// This operator checks whether left hand side JSONB value contains right hand side JSONB value /// /// # Example /// /// ```rust /// # include!("../../doctest_setup.rs"); /// # /// # table! { /// # contacts { /// # id -> Integer, /// # name -> VarChar, /// # address -> Jsonb, /// # } /// # } /// # /// # fn main() { /// # run_test().unwrap(); /// # } /// # /// # #[cfg(feature = "serde_json")] /// # fn run_test() -> QueryResult<()> { /// # use self::contacts::dsl::*; /// # let conn = &mut establish_connection(); /// # diesel::sql_query("DROP TABLE IF EXISTS contacts").execute(conn).unwrap(); /// # diesel::sql_query("CREATE TABLE contacts ( /// # id SERIAL PRIMARY KEY, /// # name VARCHAR NOT NULL, /// # address JSONB NOT NULL /// # )").execute(conn).unwrap(); /// # /// let easter_bunny_address: serde_json::Value = serde_json::json!({ /// "street": "123 Carrot Road", /// "province": "Easter Island", /// "region": "Valparaíso", /// "country": "Chile", /// "postcode": "88888", /// }); /// diesel::insert_into(contacts) /// .values((name.eq("Bunny"), address.eq(&easter_bunny_address))) /// .execute(conn)?; /// /// let country_chile: serde_json::Value = serde_json::json!({"country": "Chile"}); /// let contains_country_chile = contacts.select(address.contains(&country_chile)).get_result::<bool>(conn)?; /// assert!(contains_country_chile); /// # Ok(()) /// # } /// # #[cfg(not(feature = "serde_json"))] /// # fn run_test() -> QueryResult<()> { /// # Ok(()) /// # } /// ``` fn contains<T>(self, other: T) -> dsl::Contains<Self, T> where Self::SqlType: SqlType, T: AsExpression<Self::SqlType>, { Grouped(Contains::new(self, other.as_expression())) } }
Update order
Now, let's update the order by filtering the order by address.
#![allow(unused)] fn main() { // write update order by address function pub fn update_order_by_address( conn: &mut PgConnection, address: &str, new_amount: BigDecimal, ) -> QueryResult<usize> { use crate::schema::orders::dsl::{metadata, orders, total_amount}; let query = diesel::update(orders) .filter(metadata.contains(json!({ "address": address }))) .set(total_amount.eq(new_amount)); let debug = diesel::debug_query::<diesel::pg::Pg, _>(&query); println!("The update query: {:#?}", debug); query.execute(conn) } }
This function will update the order by filtering the order by address.
Now, let's modify main.rs to call the update_order_by_address method.
fn main() { let conn = &mut establish_connection(); // // Example usage // let new_order = models::NewOrder { // user_id: 1, // // total_amount: 99.99, // total_amount: BigDecimal::from_str("0.80").unwrap(), // metadata: serde_json::json!({ // "items": ["book", "pen"], // "shipping_method": "express", // "gift_wrap": true, // "address": "Article Circle Expressway 2", // // "address": "123 Main St, Anytown, USA", // }), // }; // match db::create_order(conn, new_order) { // Ok(order) => println!("Created order: {:?}", order), // Err(e) => eprintln!("Error creating order: {}", e), // } // Query // let metadata_address: serde_json::Value = serde_json::json!({"address": "Article Circle Expressway 2"}); // match db::get_orders_by_address(conn, &metadata_address) { // Ok(orders) => println!("Orders by address: {:#?}", orders), // Err(e) => eprintln!("Error getting orders by address: {}", e), // } // Update let address = "Article Circle Expressway 2"; let new_amount = BigDecimal::from_f64(1234.56).unwrap(); match db::update_order_by_address(conn, address, new_amount) { Ok(orders) => println!("Orders by address: {:#?}", orders), Err(e) => eprintln!("Error getting orders by address: {}", e), } }
Below is the data changes after the update:
dylan@/tmp:diesel_demo> SELECT * FROM orders WHERE metadata @> '{"address": "Article Circle Expressway 2"}';
+----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------+
| id | user_id | total_amount | order_date | metadata |
|----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------|
| 4 | 1 | 0.80 | 2024-12-17 05:47:40.956483 | {"items": ["book", "pen"], "address": "Article Circle Expressway 2", "gift_wrap": true, "shipping_method": "express"} |
+----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------+
SELECT 1
Time: 0.017s
dylan@/tmp:diesel_demo>
Time: 0.000s
dylan@/tmp:diesel_demo>
Time: 0.000s
dylan@/tmp:diesel_demo>
Time: 0.000s
dylan@/tmp:diesel_demo> SELECT * FROM orders WHERE metadata @> '{"address": "Article Circle Expressway 2"}';
+----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------+
| id | user_id | total_amount | order_date | metadata |
|----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------|
| 4 | 1 | 1234.56 | 2024-12-17 05:47:40.956483 | {"items": ["book", "pen"], "address": "Article Circle Expressway 2", "gift_wrap": true, "shipping_method": "express"} |
+----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------+
SELECT 1
Time: 0.007s
Delete order
Let's write the code to delete the order by filtering the order by address.
#![allow(unused)] fn main() { // write delete order by address function pub fn delete_order_by_address( conn: &mut PgConnection, address: &str, ) -> QueryResult<usize> { use crate::schema::orders::dsl::{metadata, orders}; let query = diesel::delete(orders) .filter(metadata.contains(json!({ "address": address }))); let debug = diesel::debug_query::<diesel::pg::Pg, _>(&query); println!("The delete query: {:#?}", debug); query.execute(conn) } }
Let's modify main.rs to call the delete_order_by_address method.
fn main() { let conn = &mut establish_connection(); // // Example usage // let new_order = models::NewOrder { // user_id: 1, // // total_amount: 99.99, // total_amount: BigDecimal::from_str("0.80").unwrap(), // metadata: serde_json::json!({ // "items": ["book", "pen"], // "shipping_method": "express", // "gift_wrap": true, // "address": "Article Circle Expressway 2", // // "address": "123 Main St, Anytown, USA", // }), // }; // match db::create_order(conn, new_order) { // Ok(order) => println!("Created order: {:?}", order), // Err(e) => eprintln!("Error creating order: {}", e), // } // Query // let metadata_address: serde_json::Value = serde_json::json!({"address": "Article Circle Expressway 2"}); // match db::get_orders_by_address(conn, &metadata_address) { // Ok(orders) => println!("Orders by address: {:#?}", orders), // Err(e) => eprintln!("Error getting orders by address: {}", e), // } // Update // let address = "Article Circle Expressway 2"; // let new_amount = BigDecimal::from_f64(1234.56).unwrap(); // match db::update_order_by_address(conn, address, new_amount) { // Ok(orders) => println!("Orders by address: {:#?}", orders), // Err(e) => eprintln!("Error getting orders by address: {}", e), // } // Delete let address = "Article Circle Expressway 2"; match db::delete_order_by_address(conn, address) { Ok(orders) => println!("Orders by address: {:#?}", orders), Err(e) => eprintln!("Error getting orders by address: {}", e), } }
Below is the data changes after the delete:
dylan@/tmp:diesel_demo> SELECT * FROM orders WHERE metadata @> '{"address": "Article Circle Expressway 2"}';
+----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------+
| id | user_id | total_amount | order_date | metadata |
|----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------|
| 4 | 1 | 1234.56 | 2024-12-17 05:47:40.956483 | {"items": ["book", "pen"], "address": "Article Circle Expressway 2", "gift_wrap": true, "shipping_method": "express"} |
+----+---------+--------------+----------------------------+-----------------------------------------------------------------------------------------------------------------------+
SELECT 1
Time: 0.007s
dylan@/tmp:diesel_demo>
Time: 0.000s
dylan@/tmp:diesel_demo>
Time: 0.000s
dylan@/tmp:diesel_demo>
Time: 0.000s
dylan@/tmp:diesel_demo> SELECT * FROM orders WHERE metadata @> '{"address": "Article Circle Expressway 2"}';
+----+---------+--------------+------------+----------+
| id | user_id | total_amount | order_date | metadata |
|----+---------+--------------+------------+----------|
+----+---------+--------------+------------+----------+
SELECT 0
Time: 0.006s
Summary
In this demo, we have seen how to setup diesel and run migrations, write sql for migration, create orders, query orders, update orders, delete orders.
We learned how to use Diesel to query the orders by metadata using the @> jsonb operator.
We have also seen how to update the order by filtering the order by address and delete the order by filtering the order by address.
Refs
Diesel schema https://diesel.rs/guides/schema-in-depth.html
Diesel getting started https://diesel.rs/guides/getting-started
Tokio Codec
Intro
今天来讲讲 tokio 的 codec。
顾名思义,codec 是一个编码解码器,用于将原始字节解码为 rust 的数据类型。
首先,我们来看看 codec 的基本用法。
EchoCodec
我们首先来看一个简单的例子,我们将 tokio 中的 TcpStream 进行编码和解码。
实现 Decoder 和 Encoder 这两个 trait 即可拥有编解码的功能。
在实现这两个 trait 之前,我们首先定义错误类型,这里使用 enum ConnectionError,使用 enum 也是最常见的定义错误类型的方式。
为什么要先定义错误类型呢?因为 Decoder 和 Encoder 这两个 trait 都定义了一个叫做 Error 的关联类型(associated type),所以为了实现这两个 trait,我们也需要定义一个错误类型。
下面是 tokio_util::codec 这个包(package)里的 Decoder 和 Encoder 的定义。
Decoder trait 的定义:
#![allow(unused)] fn main() { /// Decoding of frames via buffers. /// /// This trait is used when constructing an instance of [`Framed`] or /// [`FramedRead`]. An implementation of `Decoder` takes a byte stream that has /// already been buffered in `src` and decodes the data into a stream of /// `Self::Item` frames. /// /// Implementations are able to track state on `self`, which enables /// implementing stateful streaming parsers. In many cases, though, this type /// will simply be a unit struct (e.g. `struct HttpDecoder`). /// /// For some underlying data-sources, namely files and FIFOs, /// it's possible to temporarily read 0 bytes by reaching EOF. /// /// In these cases `decode_eof` will be called until it signals /// fullfillment of all closing frames by returning `Ok(None)`. /// After that, repeated attempts to read from the [`Framed`] or [`FramedRead`] /// will not invoke `decode` or `decode_eof` again, until data can be read /// during a retry. /// /// It is up to the Decoder to keep track of a restart after an EOF, /// and to decide how to handle such an event by, for example, /// allowing frames to cross EOF boundaries, re-emitting opening frames, or /// resetting the entire internal state. /// /// [`Framed`]: crate::codec::Framed /// [`FramedRead`]: crate::codec::FramedRead pub trait Decoder { /// The type of decoded frames. type Item; /// The type of unrecoverable frame decoding errors. /// /// If an individual message is ill-formed but can be ignored without /// interfering with the processing of future messages, it may be more /// useful to report the failure as an `Item`. /// /// `From<io::Error>` is required in the interest of making `Error` suitable /// for returning directly from a [`FramedRead`], and to enable the default /// implementation of `decode_eof` to yield an `io::Error` when the decoder /// fails to consume all available data. /// /// Note that implementors of this trait can simply indicate `type Error = /// io::Error` to use I/O errors as this type. /// /// [`FramedRead`]: crate::codec::FramedRead type Error: From<io::Error>; /// Attempts to decode a frame from the provided buffer of bytes. /// /// This method is called by [`FramedRead`] whenever bytes are ready to be /// parsed. The provided buffer of bytes is what's been read so far, and /// this instance of `Decode` can determine whether an entire frame is in /// the buffer and is ready to be returned. /// /// If an entire frame is available, then this instance will remove those /// bytes from the buffer provided and return them as a decoded /// frame. Note that removing bytes from the provided buffer doesn't always /// necessarily copy the bytes, so this should be an efficient operation in /// most circumstances. /// /// If the bytes look valid, but a frame isn't fully available yet, then /// `Ok(None)` is returned. This indicates to the [`Framed`] instance that /// it needs to read some more bytes before calling this method again. /// /// Note that the bytes provided may be empty. If a previous call to /// `decode` consumed all the bytes in the buffer then `decode` will be /// called again until it returns `Ok(None)`, indicating that more bytes need to /// be read. /// /// Finally, if the bytes in the buffer are malformed then an error is /// returned indicating why. This informs [`Framed`] that the stream is now /// corrupt and should be terminated. /// /// [`Framed`]: crate::codec::Framed /// [`FramedRead`]: crate::codec::FramedRead /// /// # Buffer management /// /// Before returning from the function, implementations should ensure that /// the buffer has appropriate capacity in anticipation of future calls to /// `decode`. Failing to do so leads to inefficiency. /// /// For example, if frames have a fixed length, or if the length of the /// current frame is known from a header, a possible buffer management /// strategy is: /// /// # use std::io; /// # /// # use bytes::BytesMut; /// # use tokio_util::codec::Decoder; /// # /// # struct MyCodec; /// # /// impl Decoder for MyCodec { /// // ... /// # type Item = BytesMut; /// # type Error = io::Error; /// /// fn decode(&mut self, src: &mut BytesMut) -> Result<Option<Self::Item>, Self::Error> { /// // ... /// /// // Reserve enough to complete decoding of the current frame. /// let current_frame_len: usize = 1000; // Example. /// // And to start decoding the next frame. /// let next_frame_header_len: usize = 10; // Example. /// src.reserve(current_frame_len + next_frame_header_len); /// /// return Ok(None); /// } /// } /// /// An optimal buffer management strategy minimizes reallocations and /// over-allocations. fn decode(&mut self, src: &mut BytesMut) -> Result<Option<Self::Item>, Self::Error>; /// A default method available to be called when there are no more bytes /// available to be read from the underlying I/O. /// /// This method defaults to calling `decode` and returns an error if /// `Ok(None)` is returned while there is unconsumed data in `buf`. /// Typically this doesn't need to be implemented unless the framing /// protocol differs near the end of the stream, or if you need to construct /// frames _across_ eof boundaries on sources that can be resumed. /// /// Note that the `buf` argument may be empty. If a previous call to /// `decode_eof` consumed all the bytes in the buffer, `decode_eof` will be /// called again until it returns `None`, indicating that there are no more /// frames to yield. This behavior enables returning finalization frames /// that may not be based on inbound data. /// /// Once `None` has been returned, `decode_eof` won't be called again until /// an attempt to resume the stream has been made, where the underlying stream /// actually returned more data. fn decode_eof(&mut self, buf: &mut BytesMut) -> Result<Option<Self::Item>, Self::Error> { match self.decode(buf)? { Some(frame) => Ok(Some(frame)), None => { if buf.is_empty() { Ok(None) } else { Err(io::Error::new(io::ErrorKind::Other, "bytes remaining on stream").into()) } } } } /// Provides a [`Stream`] and [`Sink`] interface for reading and writing to this /// `Io` object, using `Decode` and `Encode` to read and write the raw data. /// /// Raw I/O objects work with byte sequences, but higher-level code usually /// wants to batch these into meaningful chunks, called "frames". This /// method layers framing on top of an I/O object, by using the `Codec` /// traits to handle encoding and decoding of messages frames. Note that /// the incoming and outgoing frame types may be distinct. /// /// This function returns a *single* object that is both `Stream` and /// `Sink`; grouping this into a single object is often useful for layering /// things like gzip or TLS, which require both read and write access to the /// underlying object. /// /// If you want to work more directly with the streams and sink, consider /// calling `split` on the [`Framed`] returned by this method, which will /// break them into separate objects, allowing them to interact more easily. /// /// [`Stream`]: futures_core::Stream /// [`Sink`]: futures_sink::Sink /// [`Framed`]: crate::codec::Framed fn framed<T: AsyncRead + AsyncWrite + Sized>(self, io: T) -> Framed<T, Self> where Self: Sized, { Framed::new(io, self) } } }
Encoder trait 的定义:
#![allow(unused)] fn main() { /// Trait of helper objects to write out messages as bytes, for use with /// [`FramedWrite`]. /// /// [`FramedWrite`]: crate::codec::FramedWrite pub trait Encoder<Item> { /// The type of encoding errors. /// /// [`FramedWrite`] requires `Encoder`s errors to implement `From<io::Error>` /// in the interest letting it return `Error`s directly. /// /// [`FramedWrite`]: crate::codec::FramedWrite type Error: From<io::Error>; /// Encodes a frame into the buffer provided. /// /// This method will encode `item` into the byte buffer provided by `dst`. /// The `dst` provided is an internal buffer of the [`FramedWrite`] instance and /// will be written out when possible. /// /// [`FramedWrite`]: crate::codec::FramedWrite fn encode(&mut self, item: Item, dst: &mut BytesMut) -> Result<(), Self::Error>; } }
由于还不知道未来会有几种类型的错误,我们先随意定义两个: Disconnected 和 Io(io::IoError),分别代表 网络连接出错(断开)以及读取 socket 时发生的 io 错误,当然实际场景的错误更加复杂和多样。
#![allow(unused)] fn main() { // 因为 codecs 的 Encoder trait 有个 associate type ,所以需要 Error 定义 #[derive(Debug)] pub enum ConnectionError { Io(io::Error), Disconnected, } impl From<io::Error> for ConnectionError { fn from(err: io::Error) -> Self { ConnectionError::Io(err) } } }
其次定义 EchoCodec,它实现了 Decoder 和 Encoder trait,其中 Decoder 和 Encoder 的 associated type 都是 ConnectionError。
实现 From<io::Error> 的原因是 Encoder 的关联类型的类型约束: type Error: From<io::Error>,即我们必须能够将 io::Error 转换为 ConnectionError。
接下来我们定义需要被编码的消息类型 Message,它是一个 String 类型,并为此实现 Encoder 和 Decoder trait。
被编码(Encode)的意思是,将 Message 类型转换为 BytesMut,然后写入到 TcpStream 中。
被解码(Decode)的意思是,从 FramedRead 中读取 BytesMut,然后解码为 Message 供应用程序使用。
#![allow(unused)] fn main() { use tokio::codec::{Decoder, Encoder}; type Message = String; struct EchoCodec; // 给 EchoCodec 实现 Encoder trait impl Encoder<Message> for EchoCodec { type Error = ConnectionError; fn encode( &mut self, item: Message, dst: &mut BytesMut, ) -> Result<(), Self::Error> { // 将 Message 写入 dst dst.extend(item.as_bytes()); Ok(()) } } // 给 EchoCodec 实现 Decoder trait impl Decoder for EchoCodec { type Item = Message; type Error = ConnectionError; fn decode( &mut self, src: &mut BytesMut, ) -> Result<Option<Self::Item>, Self::Error> { // 将 src 中的数据转换为 String if src.is_empty() { return Ok(None); } // 将 src 中的数据移除 let data = src.split(); let data = String::from_utf8_lossy(&data[..]).to_string(); // 将 line 转换为 Message Ok(Some(data)) } } }
上面可以看出,encode 方法就是将 Message 转换为 bytes 并写入 BytesMut(通过 BytesMut 的 extend 方法),而 decode 方法就是将 BytesMut 转换为 Message。
最后,在 main 函数里是这么使用的:
#[tokio::main] async fn main() -> Result<(), Box<dyn std::error::Error>> { // start listening on 50007 let listener = TcpListener::bind("127.0.0.1:50007").await?; println!("echo server started!"); loop { let (socket, addr) = listener.accept().await?; println!("accepted connection from: {}", addr); tokio::spawn(async move { let codec = EchoCodec {}; let mut conn = codec.framed(socket); while let Some(message) = conn.next().await { if let Ok(message) = message { println!("received: {:?}", message); conn.send(message).await.unwrap(); } } }); } }
值得注意的是,codec 的 framed 方法(codec.framed(socket))将 TcpStream 转换为 Framed<TcpStream, EchoCodec>,这个 Framed 就是实现了 tokio 中的 Stream 和 Sink 这两个 trait,因而具有了接收(通过 Stream)和发送(通过 Sink)数据的功能,关于这两个 trait,后面会提到。
上述 framed 方法是 Decoder trait 的方法,它第一个参数是 TcpStream,第二个参数是 EchoCodec,这个 EchoCodec 就是我们定义的 EchoCodec。
Decoder::framed 方法的定义如下:
#![allow(unused)] fn main() { fn framed<T, U>(self, codec: U) -> Framed<T, U> where T: AsyncRead + AsyncWrite, U: Decoder + Encoder<Item = Self::Item>, { Framed::new(self, codec) } }
Framed::new 方法创建一个 Framed 实例,将 TcpStream 和 EchoCodec 保存在 FramedImpl 中。
Framed struct 的定义以及 new 方法的定义:
#![allow(unused)] fn main() { pin_project! { /// A unified [`Stream`] and [`Sink`] interface to an underlying I/O object, using /// the `Encoder` and `Decoder` traits to encode and decode frames. /// /// You can create a `Framed` instance by using the [`Decoder::framed`] adapter, or /// by using the `new` function seen below. /// [`Stream`]: futures_core::Stream /// [`Sink`]: futures_sink::Sink /// [`AsyncRead`]: tokio::io::AsyncRead /// [`Decoder::framed`]: crate::codec::Decoder::framed() pub struct Framed<T, U> { #[pin] inner: FramedImpl<T, U, RWFrames> } } impl<T, U> Framed<T, U> where T: AsyncRead + AsyncWrite, { /// Provides a [`Stream`] and [`Sink`] interface for reading and writing to this /// I/O object, using [`Decoder`] and [`Encoder`] to read and write the raw data. /// /// Raw I/O objects work with byte sequences, but higher-level code usually /// wants to batch these into meaningful chunks, called "frames". This /// method layers framing on top of an I/O object, by using the codec /// traits to handle encoding and decoding of messages frames. Note that /// the incoming and outgoing frame types may be distinct. /// /// This function returns a *single* object that is both [`Stream`] and /// [`Sink`]; grouping this into a single object is often useful for layering /// things like gzip or TLS, which require both read and write access to the /// underlying object. /// /// If you want to work more directly with the streams and sink, consider /// calling [`split`] on the `Framed` returned by this method, which will /// break them into separate objects, allowing them to interact more easily. /// /// Note that, for some byte sources, the stream can be resumed after an EOF /// by reading from it, even after it has returned `None`. Repeated attempts /// to do so, without new data available, continue to return `None` without /// creating more (closing) frames. /// /// [`Stream`]: futures_core::Stream /// [`Sink`]: futures_sink::Sink /// [`Decode`]: crate::codec::Decoder /// [`Encoder`]: crate::codec::Encoder /// [`split`]: https://docs.rs/futures/0.3/futures/stream/trait.StreamExt.html#method.split pub fn new(inner: T, codec: U) -> Framed<T, U> { Framed { inner: FramedImpl { inner, codec, state: Default::default(), }, } } } }
FramedImpl 除了保存了 TcpStream 和 EchoCodec,它还保存了一个 State,这个 State 是一个 RWFrames 实例,相当于一个缓冲区。
FramedImpl struct 的定义:
#![allow(unused)] fn main() { pin_project! { #[derive(Debug)] pub(crate) struct FramedImpl<T, U, State> { #[pin] pub(crate) inner: T, pub(crate) state: State, pub(crate) codec: U, } } }
RWFrames 、ReadFrame 和 WriteFrame 的定义。
#![allow(unused)] fn main() { #[derive(Debug)] pub(crate) struct ReadFrame { pub(crate) eof: bool, pub(crate) is_readable: bool, pub(crate) buffer: BytesMut, pub(crate) has_errored: bool, } pub(crate) struct WriteFrame { pub(crate) buffer: BytesMut, } #[derive(Default)] pub(crate) struct RWFrames { pub(crate) read: ReadFrame, pub(crate) write: WriteFrame, } }
RWFrames 实现了 Borrow 和 BorrowMut 这两个 trait,能分别返回 ReadFrame 和 WriteFrame 用来作为读写数据的缓冲。
#![allow(unused)] fn main() { impl Borrow<ReadFrame> for RWFrames { fn borrow(&self) -> &ReadFrame { &self.read } } impl BorrowMut<ReadFrame> for RWFrames { fn borrow_mut(&mut self) -> &mut ReadFrame { &mut self.read } } impl Borrow<WriteFrame> for RWFrames { fn borrow(&self) -> &WriteFrame { &self.write } } impl BorrowMut<WriteFrame> for RWFrames { fn borrow_mut(&mut self) -> &mut WriteFrame { &mut self.write } } }
RWFrames 实现 Borrow BorrowMut 也比较有意思,当需要从 Stream 读 数据(这里指异步读取 AsyncRead)的时候,会调用 BorrowMut<ReadFrame> 方法,返回内部的 ReadFrame 的引用,作为读数据的缓冲。当需要向 Sink 写 数据(这里指异步写入 AsyncWrite)的时候,会调用 BorrowMut<WriteFrame> 方法,返回内部的 WriteFrame 的引用,作为写数据的缓冲。
而 FramedImpl 实现了 Stream 和 Sink 这两个 trait。Stream 代表读数据,Sink 代表写数据。实现 Stream 时,FramedImpl 的泛型参数的约束是 T: AsyncRead 和 R: BorrowMut<ReadFrame>,表示 FramedImpl::inner 只需满足 AsyncRead,而且读取操作时会用到 ReadFrame。
实现 Sink 时,FramedImpl 的泛型参数的约束是 T: AsyncWrite 和 R: BorrowMut<WriteFrame>。实现 Sink 时,表示 FramedImpl::inner 只需满足 AsyncWrite,而且写入操作时会用到 WriteFrame。
另外,比较有趣的是,FramedImpl 实现 Stream 时,poll_next 方法有个状态机,体现了读取数据流时复杂的流程。
#![allow(unused)] fn main() { impl<T, U, R> Stream for FramedImpl<T, U, R> where T: AsyncRead, U: Decoder, R: BorrowMut<ReadFrame>, { type Item = Result<U::Item, U::Error>; fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> { use crate::util::poll_read_buf; let mut pinned = self.project(); let state: &mut ReadFrame = pinned.state.borrow_mut(); // The following loops implements a state machine with each state corresponding // to a combination of the `is_readable` and `eof` flags. States persist across // loop entries and most state transitions occur with a return. // // The initial state is `reading`. // // | state | eof | is_readable | has_errored | // |---------|-------|-------------|-------------| // | reading | false | false | false | // | framing | false | true | false | // | pausing | true | true | false | // | paused | true | false | false | // | errored | <any> | <any> | true | // `decode_eof` returns Err // ┌────────────────────────────────────────────────────────┐ // `decode_eof` returns │ │ // `Ok(Some)` │ │ // ┌─────┐ │ `decode_eof` returns After returning │ // Read 0 bytes ├─────▼──┴┐ `Ok(None)` ┌────────┐ ◄───┐ `None` ┌───▼─────┐ // ┌────────────────►│ Pausing ├───────────────────────►│ Paused ├─┐ └───────────┤ Errored │ // │ └─────────┘ └─┬──▲───┘ │ └───▲───▲─┘ // Pending read │ │ │ │ │ │ // ┌──────┐ │ `decode` returns `Some` │ └─────┘ │ │ // │ │ │ ┌──────┐ │ Pending │ │ // │ ┌────▼──┴─┐ Read n>0 bytes ┌┴──────▼─┐ read n>0 bytes │ read │ │ // └─┤ Reading ├───────────────►│ Framing │◄────────────────────────┘ │ │ // └──┬─▲────┘ └─────┬──┬┘ │ │ // │ │ │ │ `decode` returns Err │ │ // │ └───decode` returns `None`──┘ └───────────────────────────────────────────────────────┘ │ // │ read returns Err │ // └────────────────────────────────────────────────────────────────────────────────────────────┘ loop { // too long, omit } } }
FramedImpl 实现了 Stream,我们就能够从它那里读取数据了。
读取数据的过程是通过 StreamExt::next 方法实现的,它是对 Stream trait 的扩展,提供了很多实用方法,其中 next 就是其中一个。
StreamExt::next 方法的定义:
#![allow(unused)] fn main() { /// An extension trait for `Stream`s that provides a variety of convenient /// combinator functions. pub trait StreamExt: Stream { /// Creates a future that resolves to the next item in the stream. /// /// Note that because `next` doesn't take ownership over the stream, /// the [`Stream`] type must be [`Unpin`]. If you want to use `next` with a /// [`!Unpin`](Unpin) stream, you'll first have to pin the stream. This can /// be done by boxing the stream using [`Box::pin`] or /// pinning it to the stack using the `pin_mut!` macro from the `pin_utils` /// crate. /// /// # Examples /// /// # futures::executor::block_on(async { /// use futures::stream::{self, StreamExt}; /// /// let mut stream = stream::iter(1..=3); /// /// assert_eq!(stream.next().await, Some(1)); /// assert_eq!(stream.next().await, Some(2)); /// assert_eq!(stream.next().await, Some(3)); /// assert_eq!(stream.next().await, None); /// # }); fn next(&mut self) -> Next<'_, Self> where Self: Unpin, { assert_future::<Option<Self::Item>, _>(Next::new(self)) } // other methods... } }
StreamExt::next 方法创建一个对自身的引用,并且返回一个 Next 对象,这个对象实现了 Future trait,所以我们可以通过 await 来读取数据。
Next struct 的定义:
#![allow(unused)] fn main() { /// Future for the [`next`](super::StreamExt::next) method. #[derive(Debug)] #[must_use = "futures do nothing unless you `.await` or poll them"] pub struct Next<'a, St: ?Sized> { stream: &'a mut St, } impl<St: ?Sized + Unpin> Unpin for Next<'_, St> {} impl<'a, St: ?Sized + Stream + Unpin> Next<'a, St> { pub(super) fn new(stream: &'a mut St) -> Self { Self { stream } } } impl<St: ?Sized + FusedStream + Unpin> FusedFuture for Next<'_, St> { fn is_terminated(&self) -> bool { self.stream.is_terminated() } } impl<St: ?Sized + Stream + Unpin> Future for Next<'_, St> { type Output = Option<St::Item>; fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { self.stream.poll_next_unpin(cx) } } }
在得知 FramedImpl 如何读取数据之后,那么 FramedImpl 是如何实现向 Sink 写入数据的呢?
FramedImpl 实现了 Sink trait,可以看到主要是调用了 FramedImpl::poll_flush 方法将 Encoder 编码的数据通过字节流发送出去。
#![allow(unused)] fn main() { impl<T, I, U, W> Sink<I> for FramedImpl<T, U, W> where T: AsyncWrite, U: Encoder<I>, U::Error: From<io::Error>, W: BorrowMut<WriteFrame>, { type Error = U::Error; fn poll_ready(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { if self.state.borrow().buffer.len() >= BACKPRESSURE_BOUNDARY { self.as_mut().poll_flush(cx) } else { Poll::Ready(Ok(())) } } fn start_send(self: Pin<&mut Self>, item: I) -> Result<(), Self::Error> { let pinned = self.project(); pinned .codec .encode(item, &mut pinned.state.borrow_mut().buffer)?; Ok(()) } fn poll_flush(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { use crate::util::poll_write_buf; trace!("flushing framed transport"); let mut pinned = self.project(); while !pinned.state.borrow_mut().buffer.is_empty() { let WriteFrame { buffer } = pinned.state.borrow_mut(); trace!("writing; remaining={}", buffer.len()); let n = ready!(poll_write_buf(pinned.inner.as_mut(), cx, buffer))?; if n == 0 { return Poll::Ready(Err(io::Error::new( io::ErrorKind::WriteZero, "failed to \ write frame to transport", ) .into())); } } // Try flushing the underlying IO ready!(pinned.inner.poll_flush(cx))?; trace!("framed transport flushed"); Poll::Ready(Ok(())) } fn poll_close(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { ready!(self.as_mut().poll_flush(cx))?; ready!(self.project().inner.poll_shutdown(cx))?; Poll::Ready(Ok(())) } } }
而我们能通过 send 方法(参看 main 函数中的 conn.send(message).await.unwrap();)将编码的 Message 发送出去,是因为 SinkExt 是对 Sink trait 的扩展,它提供了 send 方法。
#![allow(unused)] fn main() { impl<T: ?Sized, Item> SinkExt<Item> for T where T: Sink<Item> {} /// An extension trait for `Sink`s that provides a variety of convenient /// combinator functions. pub trait SinkExt<Item>: Sink<Item> { /// A future that completes after the given item has been fully processed /// into the sink, including flushing. /// /// Note that, **because of the flushing requirement, it is usually better /// to batch together items to send via `feed` or `send_all`, /// rather than flushing between each item.** fn send(&mut self, item: Item) -> Send<'_, Self, Item> where Self: Unpin, { assert_future::<Result<(), Self::Error>, _>(Send::new(self, item)) } // other methods... } }
这个方法返回一个 Send struct,它是对 Feed 的一个简单 wrapper,它的作用是将 item 发送出去,发送功能交给 Feed::sink_pin_mut::poll_flush 来实现。
#![allow(unused)] fn main() { /// Future for the [`send`](super::SinkExt::send) method. #[derive(Debug)] #[must_use = "futures do nothing unless you `.await` or poll them"] pub struct Send<'a, Si: ?Sized, Item> { feed: Feed<'a, Si, Item>, } // Pinning is never projected to children impl<Si: Unpin + ?Sized, Item> Unpin for Send<'_, Si, Item> {} impl<'a, Si: Sink<Item> + Unpin + ?Sized, Item> Send<'a, Si, Item> { pub(super) fn new(sink: &'a mut Si, item: Item) -> Self { Self { feed: Feed::new(sink, item) } } } impl<Si: Sink<Item> + Unpin + ?Sized, Item> Future for Send<'_, Si, Item> { type Output = Result<(), Si::Error>; fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { let this = &mut *self; if this.feed.is_item_pending() { ready!(Pin::new(&mut this.feed).poll(cx))?; debug_assert!(!this.feed.is_item_pending()); } // we're done sending the item, but want to block on flushing the // sink ready!(this.feed.sink_pin_mut().poll_flush(cx))?; Poll::Ready(Ok(())) } } }
这里是 Feed struct 的定义:
#![allow(unused)] fn main() { /// Future for the [`feed`](super::SinkExt::feed) method. #[derive(Debug)] #[must_use = "futures do nothing unless you `.await` or poll them"] pub struct Feed<'a, Si: ?Sized, Item> { sink: &'a mut Si, item: Option<Item>, } // Pinning is never projected to children impl<Si: Unpin + ?Sized, Item> Unpin for Feed<'_, Si, Item> {} impl<'a, Si: Sink<Item> + Unpin + ?Sized, Item> Feed<'a, Si, Item> { pub(super) fn new(sink: &'a mut Si, item: Item) -> Self { Feed { sink, item: Some(item) } } pub(super) fn sink_pin_mut(&mut self) -> Pin<&mut Si> { Pin::new(self.sink) } pub(super) fn is_item_pending(&self) -> bool { self.item.is_some() } } impl<Si: Sink<Item> + Unpin + ?Sized, Item> Future for Feed<'_, Si, Item> { type Output = Result<(), Si::Error>; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { let this = self.get_mut(); let mut sink = Pin::new(&mut this.sink); ready!(sink.as_mut().poll_ready(cx))?; let item = this.item.take().expect("polled Feed after completion"); sink.as_mut().start_send(item)?; Poll::Ready(Ok(())) } } }
Feed 实现了 Future trait,其 poll 方法首先调用 poll_ready 方法,如果 poll_ready 返回 Ready,则调用 start_send 方法,将 item 发送出去,如果 start_send 返回 Ready,则返回 Ready,否则继续调用 poll_ready 方法。
poll_ready 存在的意义是对是否能够发送 item 做出判断,如果不能发送,则需要等待(poll_ready 返回 Poll::Pending 等待被唤醒,具体实现是通过调用 cx.waker().wake_by_ref() 将异步任务注册,等待下一次被调度,poll_ready 的文档说明了这个过程,见下面 👇),直到能够发送。举个例子,在 FramedImpl 实现 Sink trait 时,采用了底层缓冲区(WriteFrame)的方式来存储待发送的数据,如果缓冲区满了,则调用 poll_flush 方法,否则表示可以开始发送数据(调用 start_send 方法)。
FramedImpl::poll_ready 方法的实现如下:
#![allow(unused)] fn main() { /// Attempts to prepare the `Sink` to receive a value. /// /// This method must be called and return `Poll::Ready(Ok(()))` prior to /// each call to `start_send`. /// /// This method returns `Poll::Ready` once the underlying sink is ready to /// receive data. If this method returns `Poll::Pending`, the current task /// is registered to be notified (via `cx.waker().wake_by_ref()`) when `poll_ready` /// should be called again. /// /// In most cases, if the sink encounters an error, the sink will /// permanently be unable to receive items. fn poll_ready(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { if self.state.borrow().buffer.len() >= BACKPRESSURE_BOUNDARY { self.as_mut().poll_flush(cx) } else { Poll::Ready(Ok(())) } } }
通过分析 Feed 的 poll 方法,我们得知数据最终是如何发送出去的了。
至于待发送的数据何时被编码,我们可以看到是在 FramedImpl::start_send 方法来做的。
FramedImpl::start_end 方法的实现如下:
#![allow(unused)] fn main() { fn start_send(self: Pin<&mut Self>, item: I) -> Result<(), Self::Error> { let pinned = self.project(); pinned .codec .encode(item, &mut pinned.state.borrow_mut().buffer)?; Ok(()) } }
所以,我们能通过 next 来从数据流中接收并解析成 Message 结构,然后又通过 send 方法来将接收到的数据发送出去了。
next 接收数据 send 发送数据:
#![allow(unused)] fn main() { while let Some(message) = conn.next().await { if let Ok(message) = message { println!("received: {:?}", message); conn.send(message).await.unwrap(); } } }
总结一下就是:
SinkExt提供了send方法,用于将接收到的数据发送出去SinkExt::send方法通过Send::new返回一个实现了Future的SendstructSend内部采用Feed实现,目的是防止重复发送(将带发送的Item放入Option,在poll被调用前检查是否已经被编码发送出去,如果已经被编码并发送,则Option为None),Feed也实现了FuturetraitSend方法首先检查Feed的is_item_pending方法,如果Feed的item为None,则表示Feed已经被编码并发送出去,如果Feed的item为Some,则表示Feed还未被编码并发送出去,需要调用Feed的poll方法。Feed::poll方法完成发送逻辑- 调用
poll_ready判断是否可以发送,缓冲区BACKPRESSURE_BOUNDARY大小为 8k,满了则无法发送 - 调用
self.item.take将待发送的Item取出 - 调用
start_send对Item进行编码
- 调用
Send最后调用poll_flush(此时是FramedImpl::poll_flush)刷新写缓冲区
客户端测试:
首先运行 server 端:
#![allow(unused)] fn main() { echo server started! accepted connection from: 127.0.0.1:60105 received: "1\r\n" received: "2\r\n" received: "3\r\n" received: "44\r\n" received: "55\r\n" received: "66\r\n" received: "777\r\n" received: "888\r\n" received: "999\r\n" }
其次使用 telnet 来连接 server 端,并输入数字,然后按回车键,这些数字会被转换成字符串,然后会被发送到 server 端。
客户端的连接:
telnet localhost 50007
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
1
1
2
2
3
3
44
44
55
55
66
66
777
777
888
888
999
999
可以看到,server 端接收到的数据是 1\r\n, 2\r\n, 3\r\n, 44\r\n, 55\r\n, 66\r\n, 777\r\n, 888\r\n, 999\r\n,成功接受到来自 client 端的数据。
Echo using io::Copy
手动实现 EchoCodec 比较繁琐,为了方便,我们可以使用 io::copy 来实现 EchoCodec 的功能,它的实现如下:
首先,socket.split() 将 socket 分成两个部分,一个是接收数据(这个在 tokio 里叫做 ReadHalf),一个是发送数据(这个在 tokio 里叫做 WriteHalf)。io::copy 将接收数据(ReadHalf)的部分拷贝到发送数据(WritHalf)的部分,这样就实现了数据的双向传输。
#![allow(unused)] fn main() { // 使用 io::copy 自动拷贝数据,需要调用 tokio::io::split 分割成 reader 和 writer let (mut rd, mut wr) = socket.split(); if io::copy(&mut rd, &mut wr).await.is_err() { eprintln!("failed to copy"); } }
完整的实现如下:
#[tokio::main] async fn main() -> Result<(), Box<dyn std::error::Error>> { // start listening on 50007 let listener = TcpListener::bind("127.0.0.1:50007").await?; println!("echo server started!"); loop { let (mut socket, addr) = listener.accept().await?; println!("accepted connection from: {}", addr); tokio::spawn(async move { // 方法1: // 使用 io::copy 自动拷贝数据,需要调用 tokio::io::split 分割成 reader 和 writer let (mut rd, mut wr) = socket.split(); if io::copy(&mut rd, &mut wr).await.is_err() { eprintln!("failed to copy"); } }); } Ok(()) }
同样的,我们用客户端来进行测试:
首先运行 server 端:
#![allow(unused)] fn main() { echo server started! accepted connection from: 127.0.0.1:60205 received: "1\r\n" received: "2\r\n" received: "3\r\n" received: "44\r\n" received: "55\r\n" received: "66\r\n" received: "777\r\n" received: "888\r\n" received: "999\r\n" }
其次使用 telnet 来连接 server 端,并输入数字,然后按回车键,这些数字会被转换成字符串,然后会被发送到 server 端。
客户端的连接:
telnet localhost 50007
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
1
1
2
2
3
3
44
44
55
55
66
66
777
777
888
888
999
999
可以看到,利用 io::copy 和手动实现 EchoCodec 的输出一致。
Stream Sink trait
最后,附赠一下 Stream 和 Sink trait 的定义。
实现了 tokio 中的 Stream 和 Sink 就能从数据流(如 TcpStream 或 File)中获取数据,并且能够将数据写回到数据流中。
Stream trait 的定义:
#![allow(unused)] fn main() { /// A stream of values produced asynchronously. /// /// If `Future<Output = T>` is an asynchronous version of `T`, then `Stream<Item /// = T>` is an asynchronous version of `Iterator<Item = T>`. A stream /// represents a sequence of value-producing events that occur asynchronously to /// the caller. /// /// The trait is modeled after `Future`, but allows `poll_next` to be called /// even after a value has been produced, yielding `None` once the stream has /// been fully exhausted. #[must_use = "streams do nothing unless polled"] pub trait Stream { /// Values yielded by the stream. type Item; /// Attempt to pull out the next value of this stream, registering the /// current task for wakeup if the value is not yet available, and returning /// `None` if the stream is exhausted. /// /// # Return value /// /// There are several possible return values, each indicating a distinct /// stream state: /// /// - `Poll::Pending` means that this stream's next value is not ready /// yet. Implementations will ensure that the current task will be notified /// when the next value may be ready. /// /// - `Poll::Ready(Some(val))` means that the stream has successfully /// produced a value, `val`, and may produce further values on subsequent /// `poll_next` calls. /// /// - `Poll::Ready(None)` means that the stream has terminated, and /// `poll_next` should not be invoked again. /// /// # Panics /// /// Once a stream has finished (returned `Ready(None)` from `poll_next`), calling its /// `poll_next` method again may panic, block forever, or cause other kinds of /// problems; the `Stream` trait places no requirements on the effects of /// such a call. However, as the `poll_next` method is not marked `unsafe`, /// Rust's usual rules apply: calls must never cause undefined behavior /// (memory corruption, incorrect use of `unsafe` functions, or the like), /// regardless of the stream's state. /// /// If this is difficult to guard against then the [`fuse`] adapter can be used /// to ensure that `poll_next` always returns `Ready(None)` in subsequent /// calls. /// /// [`fuse`]: https://docs.rs/futures/0.3/futures/stream/trait.StreamExt.html#method.fuse fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>>; /// Returns the bounds on the remaining length of the stream. /// /// Specifically, `size_hint()` returns a tuple where the first element /// is the lower bound, and the second element is the upper bound. /// /// The second half of the tuple that is returned is an [`Option`]`<`[`usize`]`>`. /// A [`None`] here means that either there is no known upper bound, or the /// upper bound is larger than [`usize`]. /// /// # Implementation notes /// /// It is not enforced that a stream implementation yields the declared /// number of elements. A buggy stream may yield less than the lower bound /// or more than the upper bound of elements. /// /// `size_hint()` is primarily intended to be used for optimizations such as /// reserving space for the elements of the stream, but must not be /// trusted to e.g., omit bounds checks in unsafe code. An incorrect /// implementation of `size_hint()` should not lead to memory safety /// violations. /// /// That said, the implementation should provide a correct estimation, /// because otherwise it would be a violation of the trait's protocol. /// /// The default implementation returns `(0, `[`None`]`)` which is correct for any /// stream. #[inline] fn size_hint(&self) -> (usize, Option<usize>) { (0, None) } } }
Sink trait 的定义:
#![allow(unused)] fn main() { /// A `Sink` is a value into which other values can be sent, asynchronously. /// /// Basic examples of sinks include the sending side of: /// /// - Channels /// - Sockets /// - Pipes /// /// In addition to such "primitive" sinks, it's typical to layer additional /// functionality, such as buffering, on top of an existing sink. /// /// Sending to a sink is "asynchronous" in the sense that the value may not be /// sent in its entirety immediately. Instead, values are sent in a two-phase /// way: first by initiating a send, and then by polling for completion. This /// two-phase setup is analogous to buffered writing in synchronous code, where /// writes often succeed immediately, but internally are buffered and are /// *actually* written only upon flushing. /// /// In addition, the `Sink` may be *full*, in which case it is not even possible /// to start the sending process. /// /// As with `Future` and `Stream`, the `Sink` trait is built from a few core /// required methods, and a host of default methods for working in a /// higher-level way. The `Sink::send_all` combinator is of particular /// importance: you can use it to send an entire stream to a sink, which is /// the simplest way to ultimately consume a stream. #[must_use = "sinks do nothing unless polled"] pub trait Sink<Item> { /// The type of value produced by the sink when an error occurs. type Error; /// Attempts to prepare the `Sink` to receive a value. /// /// This method must be called and return `Poll::Ready(Ok(()))` prior to /// each call to `start_send`. /// /// This method returns `Poll::Ready` once the underlying sink is ready to /// receive data. If this method returns `Poll::Pending`, the current task /// is registered to be notified (via `cx.waker().wake_by_ref()`) when `poll_ready` /// should be called again. /// /// In most cases, if the sink encounters an error, the sink will /// permanently be unable to receive items. fn poll_ready(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>>; /// Begin the process of sending a value to the sink. /// Each call to this function must be preceded by a successful call to /// `poll_ready` which returned `Poll::Ready(Ok(()))`. /// /// As the name suggests, this method only *begins* the process of sending /// the item. If the sink employs buffering, the item isn't fully processed /// until the buffer is fully flushed. Since sinks are designed to work with /// asynchronous I/O, the process of actually writing out the data to an /// underlying object takes place asynchronously. **You *must* use /// `poll_flush` or `poll_close` in order to guarantee completion of a /// send**. /// /// Implementations of `poll_ready` and `start_send` will usually involve /// flushing behind the scenes in order to make room for new messages. /// It is only necessary to call `poll_flush` if you need to guarantee that /// *all* of the items placed into the `Sink` have been sent. /// /// In most cases, if the sink encounters an error, the sink will /// permanently be unable to receive items. fn start_send(self: Pin<&mut Self>, item: Item) -> Result<(), Self::Error>; /// Flush any remaining output from this sink. /// /// Returns `Poll::Ready(Ok(()))` when no buffered items remain. If this /// value is returned then it is guaranteed that all previous values sent /// via `start_send` have been flushed. /// /// Returns `Poll::Pending` if there is more work left to do, in which /// case the current task is scheduled (via `cx.waker().wake_by_ref()`) to wake up when /// `poll_flush` should be called again. /// /// In most cases, if the sink encounters an error, the sink will /// permanently be unable to receive items. fn poll_flush(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>>; /// Flush any remaining output and close this sink, if necessary. /// /// Returns `Poll::Ready(Ok(()))` when no buffered items remain and the sink /// has been successfully closed. /// /// Returns `Poll::Pending` if there is more work left to do, in which /// case the current task is scheduled (via `cx.waker().wake_by_ref()`) to wake up when /// `poll_close` should be called again. /// /// If this function encounters an error, the sink should be considered to /// have failed permanently, and no more `Sink` methods should be called. fn poll_close(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>>; } }
Async Healthcheck Multiple Endpoints
Intro
Today, I'll show you how to use tokio to do healthcheck for multiple endpoints.
The architecture is simple:
- Initialized vector of healthcheck endpoints
- Spawn futures to do health check
Code
// use tokio::time::sleep; use serde::{Deserialize, Serialize}; use std::fs::File; use std::io::BufReader; use std::time::Duration; use tokio::select; use tokio::sync::mpsc; use tokio::time; use tokio::time::{interval, sleep}; #[derive(Debug, Deserialize, Serialize, Clone)] struct Config { interval: u64, url: String, } async fn check_url(config: Config) { loop { println!("In check_url loop"); let url = &config.url; match reqwest::get(url).await { Err(e) => println!("Error: Failed to access {}: {}", config.url, e), Ok(response) => { // println!("{response:?}"); if !response.status().is_success() { println!( "Error: {} returned status code {}", config.url, response.status() ); } println!("check for {url} OK"); } } sleep(Duration::from_secs(config.interval)).await; } } #[tokio::main] async fn main() { // Load configuration from file // let file = File::open("config.json").expect("Failed to open config file"); // let reader = BufReader::new(file); // let configs: Vec<Config> = // serde_json::from_reader(reader).expect("Failed to parse config file"); let configs = vec![ Config { interval: 10, url: "http://www.baidu.com".to_string() }, Config { interval: 10, url: "http://www.qq.com".to_string() }, ]; // Create a shared timer // let mut ticker = interval(Duration::from_secs(1)); // let mut interval = // time::interval(time::Duration::from_millis(consume_interval)); // Create a task for each URL and spawn it // // NOTE: we don't need to run in loop in spawn, check_url already has loop // for config in configs { // // let mut tick = ticker.tick(); // tokio::spawn(async move { // let mut ticker = interval(Duration::from_secs(1)); // loop { // select! { // // _ = tick => { // _ = ticker.tick() => { // println!("1s ..."); // check_url(config.clone()).await; // } // } // } // }); // } for config in configs { tokio::spawn(async move { println!("spawn check future ..."); check_url(config.clone()).await; }); } println!("Infinite loop"); // Keep the program running so that other tasks can continue to run time::sleep(Duration::from_secs(2000)).await; // loop {} }
Code explain
- Load configuration from file or hard code the configuration
We can hard code the configuration or load configuration from file.
#![allow(unused)] fn main() { // let file = File::open("config.json").expect("Failed to open config file"); // let reader = BufReader::new(file); // let configs: Vec<Config> = // serde_json::from_reader(reader).expect("Failed to parse config file"); let configs = vec![ Config { interval: 10, url: "http://www.baidu.com".to_string() }, Config { interval: 10, url: "http://www.qq.com".to_string() }, ]; }
- Create a task for each URL and spawn it
#![allow(unused)] fn main() { for config in configs { tokio::spawn(async move { println!("spawn check future ..."); check_url(config.clone()).await; }); } }
- Keep the program running so that other tasks can continue to run
#![allow(unused)] fn main() { time::sleep(Duration::from_secs(2000)).await; // loop {} // Keep the program running so that other tasks can continue to run }
prometheus support for actix-web project
- Init an empty actix-web project with tokio runtime
- Add prometheus support actix-web project
- Enable process features
- How to use
- Run actix-web server
- Request metrics endpoint
Init an empty actix-web project with tokio runtime
# init project
cargo init actix-web-t
# add dependencies
cargo add actix-web
cargo add tokio --features full
Add prometheus support actix-web project
cargo add actix_web_prometheus
actix-web-prometheus is a middleware inspired by and forked from actix-web-prom. By default three metrics are tracked (this assumes the namespace actix_web_prometheus):
actix_web_prometheus_incoming_requests(labels: endpoint, method, status): the total number of HTTP requests handled by the actixHttpServer.actix_web_prometheus_response_code(labels: endpoint, method, statuscode, type): Response codes of all HTTP requests handled by the actixHttpServer.actix_web_prometheus_response_time(labels: endpoint, method, status): Total the request duration of all HTTP requests handled by the actixHttpServer.
Enable process features
You could also enable process features when adding actix_web_prometheus crate, which means process metrics will also be collected.
cargo add actix_web_prometheus --features process
Output:
Updating crates.io index
warning: translating `actix_web_prometheus` to `actix-web-prometheus`
Adding actix-web-prometheus v0.1.2 to dependencies.
Features:
+ process
How to use
Here is an simple example of how to integrate this middleware into actix-web project.
main.rs
use actix_web::{http, web, App, HttpServer, Responder, Result, HttpResponse}; use actix_web_prometheus::PrometheusMetricsBuilder; use serde::{Deserialize, Serialize}; #[actix_web::main] async fn main() -> std::io::Result<()> { let prometheus = PrometheusMetricsBuilder::new("api") .endpoint("/metrics") .build() .unwrap(); HttpServer::new(move || { App::new() .wrap(prometheus.clone()) }) .bind(("127.0.0.1", 8080))? .run() .await }
Run actix-web server
cargo run
Output:
warning: unused imports: `HttpResponse`, `Responder`, `Result`, `http`, `web`
--> src/main.rs:1:17
|
1 | use actix_web::{http, web, App, HttpServer, Responder, Result, HttpResponse};
| ^^^^ ^^^ ^^^^^^^^^ ^^^^^^ ^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: unused imports: `Deserialize`, `Serialize`
--> src/main.rs:3:13
|
3 | use serde::{Deserialize, Serialize};
| ^^^^^^^^^^^ ^^^^^^^^^
warning: `actix-web-t` (bin "actix-web-t") generated 2 warnings
Finished dev [unoptimized + debuginfo] target(s) in 0.26s
Running `target/debug/actix-web-t`
Request metrics endpoint
Build and run actix-web project, we can send request to /metrics endpoint.
curl 0:8080/metrics
Ouput:
# HELP api_incoming_requests Incoming Requests
# TYPE api_incoming_requests counter
api_incoming_requests{endpoint="/metrics",method="GET",status="200"} 28
# HELP api_response_code Response Codes
# TYPE api_response_code counter
api_response_code{endpoint="/metrics",method="GET",statuscode="200",type="200"} 28
# HELP api_response_time Response Times
# TYPE api_response_time histogram
api_response_time_bucket{endpoint="/metrics",method="GET",status="200",le="0.005"} 28
api_response_time_bucket{endpoint="/metrics",method="GET",status="200",le="0.01"} 28
api_response_time_bucket{endpoint="/metrics",method="GET",status="200",le="0.025"} 28
api_response_time_bucket{endpoint="/metrics",method="GET",status="200",le="0.05"} 28
api_response_time_bucket{endpoint="/metrics",method="GET",status="200",le="0.1"} 28
api_response_time_bucket{endpoint="/metrics",method="GET",status="200",le="0.25"} 28
api_response_time_bucket{endpoint="/metrics",method="GET",status="200",le="0.5"} 28
api_response_time_bucket{endpoint="/metrics",method="GET",status="200",le="1"} 28
api_response_time_bucket{endpoint="/metrics",method="GET",status="200",le="2.5"} 28
api_response_time_bucket{endpoint="/metrics",method="GET",status="200",le="5"} 28
api_response_time_bucket{endpoint="/metrics",method="GET",status="200",le="10"} 28
api_response_time_bucket{endpoint="/metrics",method="GET",status="200",le="+Inf"} 28
api_response_time_sum{endpoint="/metrics",method="GET",status="200"} 0.03155173499999999
api_response_time_count{endpoint="/metrics",method="GET",status="200"} 28
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 66
# HELP process_max_fds Maximum number of open file descriptors.
# TYPE process_max_fds gauge
process_max_fds 50000
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
process_open_fds 23
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
process_resident_memory_bytes 6410240
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1677656707
# HELP process_threads Number of OS threads in the process.
# TYPE process_threads gauge
process_threads 3
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 165015552
Notice, on MacOS, process metrics are not exported.
Send Http Request in Handle function or in started function When Using Actix crate
- Send Http Request in Handle function
- Send Http Request in started function
- Full source code
- Appendix
Send Http Request in Handle function
When using actors to develop concurrent applications, you may need to run asynchronous functions, such as sending HTTP requests, when an actor is started or when handling specific messages.
We know there's a method called started when implementing Actor trait. The Actor trait is defined as follows:
#![allow(unused)] fn main() { pub trait Actor: Sized + Unpin + 'static { /// Actor execution context type type Context: ActorContext; /// Called when an actor gets polled the first time. fn started(&mut self, ctx: &mut Self::Context) {} /// Called after an actor is in `Actor::Stopping` state. /// /// There can be several reasons for stopping: /// /// - `Context::stop` gets called by the actor itself. /// - All addresses to the current actor get dropped and no more /// evented objects are left in the context. /// /// An actor can return from the stopping state to the running /// state by returning `Running::Continue`. fn stopping(&mut self, ctx: &mut Self::Context) -> Running { Running::Stop } /// Called after an actor is stopped. /// /// This method can be used to perform any needed cleanup work or /// to spawn more actors. This is the final state, after this /// method got called, the actor will be dropped. fn stopped(&mut self, ctx: &mut Self::Context) {} /// Start a new asynchronous actor, returning its address. fn start(self) -> Addr<Self> where Self: Actor<Context = Context<Self>>, { Context::new().run(self) } /// Construct and start a new asynchronous actor, returning its /// address. /// /// This is constructs a new actor using the `Default` trait, and /// invokes its `start` method. fn start_default() -> Addr<Self> where Self: Actor<Context = Context<Self>> + Default, { Self::default().start() } /// Start new actor in arbiter's thread. fn start_in_arbiter<F>(wrk: &ArbiterHandle, f: F) -> Addr<Self> where Self: Actor<Context = Context<Self>>, F: FnOnce(&mut Context<Self>) -> Self + Send + 'static, { let (tx, rx) = channel::channel(DEFAULT_CAPACITY); // create actor wrk.spawn_fn(move || { let mut ctx = Context::with_receiver(rx); let act = f(&mut ctx); let fut = ctx.into_future(act); actix_rt::spawn(fut); }); Addr::new(tx) } /// Start a new asynchronous actor given a `Context`. /// /// Use this method if you need the `Context` object during actor /// initialization. fn create<F>(f: F) -> Addr<Self> where Self: Actor<Context = Context<Self>>, F: FnOnce(&mut Context<Self>) -> Self, { let mut ctx = Context::new(); let act = f(&mut ctx); ctx.run(act) } } }
The started function will be called when actor is started, but if we call async function in started function(e.g. sending http request), we'll get an error:
#![allow(unused)] fn main() { error[E0728]: `await` is only allowed inside `async` functions and blocks --> src/bin/call-async-in-non-async-function.rs:25:57 | 22 | / fn handle(&mut self, _: Msg, _: &mut Context<Self>) -> Self::Result { 23 | | // async move { Ok(()) } 24 | | 25 | | let response = reqwest::get("https://hyper.rs").await.unwrap(); | | ^^^^^ only allowed inside `async` functions and blocks ... | 35 | | // }) 36 | | } | |_____- this is not `async` For more information about this error, try `rustc --explain E0728`. warning: `actix_example` (bin "call-async-in-non-async-function") generated 6 warnings error: could not compile `actix_example` (bin "call-async-in-non-async-function") due to previous error; 6 warnings emitted }
In Rust, await can only be used within an async function or an async block. You can refer to Async book for more details.
The solution is easy, I'll explain it step by step.
Return type Result<(), ()>
Let's start with calling async function or async block in handle method.
We can specify the result to be a ResponseFuture<Result<(), ()>> and wrapper async block with Box::pin.
#![allow(unused)] fn main() { #[derive(Message)] #[rtype(result = "Result<(), ()>")] struct Msg; struct MyActor2; impl Actor for MyActor2 { type Context = Context<Self>; } impl Handler<Msg> for MyActor2 { type Result = ResponseFuture<Result<(), ()>>; fn handle(&mut self, _: Msg, _: &mut Context<Self>) -> Self::Result { Box::pin(async move { // Some async computation println!("Box::pin called"); Ok(()) }) } } }
As we use ResponseFuture<Result<(), ()>> type in Handler trait's associated type Result, we can return a Box Future using Box::pin function in handle method.
Return type Result<usize, ()>
Now, let's change return type from Result<(), ()> to Result<usize, ()>, which will return a usize from async block.
#![allow(unused)] fn main() { #[derive(Message)] #[rtype(result = "Result<usize, ()>")] struct Msg3; struct MyActor3; impl Actor for MyActor3 { type Context = Context<Self>; } impl Handler<Msg3> for MyActor3 { type Result = ResponseActFuture<Self, Result<usize, ()>>; fn handle(&mut self, _: Msg3, _: &mut Context<Self>) -> Self::Result { Box::pin( async { println!("will return 42"); // Some async computation 42 } .into_actor(self) // converts future to ActorFuture .map(|res, _act, _ctx| { println!("map"); // Do some computation with actor's state or context Ok(res) }), ) } } }
We need to change in 3 places:
- Using
#[rtype(result = "Result<usize, ()>")]macro instruct Msg3 - Change associated type from
ResponseActFuture<Self, Result<(), ()>>;toResponseActFuture<Self, Result<usize, ()>>; - Change async block to return a value of
usize
Return type Result<u16, ()>
If we care about the status code from http response, what should we do? Obviousely, we can declare a Result<u16, ()> type. Here u16 represents the status code from http response.
#![allow(unused)] fn main() { #[derive(Message)] #[rtype(result = "Result<u16, ()>")] // return http status code struct Msg4; struct MyActor4; impl Actor for MyActor4 { type Context = Context<Self>; } impl Handler<Msg4> for MyActor4 { // type Result = ResponseActFuture<Self, Result<usize, ()>>; type Result = ResponseActFuture<Self, Result<u16, ()>>; fn handle(&mut self, _: Msg4, _: &mut Context<Self>) -> Self::Result { // let res = reqwest::get("https://hyper.rs").await?; // println!("Status: {}", res.status()); // let body = res.text().await?; Box::pin( async { println!("will return 42"); let status_code = match reqwest::get("https://hyper.rs").await { Ok(response) => { println!("Got status from hyper.rs {}", response.status()); response.status().as_u16() }, Err(err) => { println!("get response error : {err}"); 42 as u16 }, }; status_code } .into_actor(self) // converts future to ActorFuture .map(|res, _act, _ctx| { println!("result in map process : {res}"); // Do some computation with actor's state or context Ok(res) }), ) } } }
In async block, we return status code using response.status().as_u16().
Return type Result<String, ()>
What if we want to use the response body, what should we do? It's quite easy to change from u16 to String. The code looks like this:
#![allow(unused)] fn main() { #[derive(Message)] #[rtype(result = "Result<String, ()>")] // return http reponse body struct Msg5; struct MyActor5; impl Actor for MyActor5 { type Context = Context<Self>; } impl Handler<Msg5> for MyActor5 { // type Result = ResponseActFuture<Self, Result<usize, ()>>; type Result = ResponseActFuture<Self, Result<String, ()>>; fn handle(&mut self, _: Msg5, _: &mut Context<Self>) -> Self::Result { // let res = reqwest::get("https://hyper.rs").await?; // println!("Status: {}", res.status()); // let body = res.text().await?; Box::pin( async { let status_code = match reqwest::get("https://hyper.rs").await { Ok(response) => { println!("Reponse Ok from hyper.rs {}", response.status()); match response.text().await { Ok(body) => body, Err(err) => { format!("Convert Reposne to string error : {err}") } } }, Err(err) => { format!("Reposne error from hyper.rs, error : {err}") }, }; status_code } .into_actor(self) // converts future to ActorFuture .map(|res, _act, _ctx| { println!("result in map process : {res}"); // Do some computation with actor's state or context Ok(res) }), ) } } }
Now, we use response.text().await to convert reponse to string and return the response body for later use.
Send Http Request in started function
If we want to store some state in actor and initialize it when actor is started, we can use context.wait to wait an async block, turn it into an actor through into_actor and store the return value of async block in then method.
#![allow(unused)] fn main() { #[derive(Clone)] struct MyActor { status_code: Option<u16>, } impl MyActor { fn print_status_code(&mut self, context: &mut Context<Self>) { println!("status code: {:?}", self.status_code); } } impl Actor for MyActor { type Context = Context<Self>; fn started(&mut self, context: &mut Context<Self>) { println!("In started"); // ✅NOTE: This will run context.wait( async move { // send http reqwest let status_code = match reqwest::get("https://hyper.rs").await { Ok(response) => { println!( "Got status from hyper.rs {}", response.status() ); response.status().as_u16() } Err(err) => { println!("get response error : {err}"); 42 as u16 } }; println!("status code: {status_code}"); status_code } .into_actor(self) .then(|output, s, ctx| { s.status_code = Some(output); fut::ready(()) }), ); IntervalFunc::new(Duration::from_millis(5000), Self::print_status_code) .finish() .spawn(context); context.run_later(Duration::from_millis(20000), |_, _| { System::current().stop() }); } } }
In this example, we store status code as Option<u16> in MyActor and save it then method from ActorFutureExt trait:
#![allow(unused)] fn main() { fn started(&mut self, context: &mut Context<Self>) { context.wait( async move { // send http reqwest let status_code = match reqwest::get("https://hyper.rs").await { Ok(response) => { response.status().as_u16() } Err(err) => { 42 as u16 } }; status_code } .into_actor(self) .then(|output, s, ctx| { s.status_code = Some(output); fut::ready(()) }), ); } }
Here is the definition of ActorFutureExt trait.
#![allow(unused)] fn main() { pub trait ActorFutureExt<A: Actor>: ActorFuture<A> { /// Map this future's result to a different type, returning a new future of /// the resulting type. fn map<F, U>(self, f: F) -> Map<Self, F> where F: FnOnce(Self::Output, &mut A, &mut A::Context) -> U, Self: Sized, { Map::new(self, f) } /// Chain on a computation for when a future finished, passing the result of /// the future to the provided closure `f`. fn then<F, Fut>(self, f: F) -> Then<Self, Fut, F> where F: FnOnce(Self::Output, &mut A, &mut A::Context) -> Fut, Fut: ActorFuture<A>, Self: Sized, { then::new(self, f) } /// Add timeout to futures chain. /// /// `Err(())` returned as a timeout error. fn timeout(self, timeout: Duration) -> Timeout<Self> where Self: Sized, { Timeout::new(self, timeout) } /// Wrap the future in a Box, pinning it. /// /// A shortcut for wrapping in [`Box::pin`]. fn boxed_local(self) -> LocalBoxActorFuture<A, Self::Output> where Self: Sized + 'static, { Box::pin(self) } } }
Full source code
Send http request in handle function
use actix::prelude::*; use anyhow::Result; use futures::prelude::*; use tokio::time::{sleep, Duration}; #[derive(Message)] #[rtype(result = "Result<(), ()>")] struct Msg; struct MyActor2; impl Actor for MyActor2 { type Context = Context<Self>; } impl Handler<Msg> for MyActor2 { type Result = ResponseFuture<Result<(), ()>>; fn handle(&mut self, _: Msg, _: &mut Context<Self>) -> Self::Result { Box::pin(async move { // Some async computation println!("Box::pin called"); Ok(()) }) } } #[derive(Message)] #[rtype(result = "Result<usize, ()>")] struct Msg3; struct MyActor3; impl Actor for MyActor3 { type Context = Context<Self>; } impl Handler<Msg3> for MyActor3 { type Result = ResponseActFuture<Self, Result<usize, ()>>; fn handle(&mut self, _: Msg3, _: &mut Context<Self>) -> Self::Result { Box::pin( async { println!("will return 42"); // Some async computation 42 } .into_actor(self) // converts future to ActorFuture .map(|res, _act, _ctx| { println!("map"); // Do some computation with actor's state or context Ok(res) }), ) } } #[derive(Message)] #[rtype(result = "Result<u16, ()>")] // return http status code struct Msg4; struct MyActor4; impl Actor for MyActor4 { type Context = Context<Self>; } impl Handler<Msg4> for MyActor4 { // type Result = ResponseActFuture<Self, Result<usize, ()>>; type Result = ResponseActFuture<Self, Result<u16, ()>>; fn handle(&mut self, _: Msg4, _: &mut Context<Self>) -> Self::Result { // let res = reqwest::get("https://hyper.rs").await?; // println!("Status: {}", res.status()); // let body = res.text().await?; Box::pin( async { println!("will return 42"); let status_code = match reqwest::get("https://hyper.rs").await { Ok(response) => { println!("Got status from hyper.rs {}", response.status()); response.status().as_u16() }, Err(err) => { println!("get response error : {err}"); 42 as u16 }, }; status_code } .into_actor(self) // converts future to ActorFuture .map(|res, _act, _ctx| { println!("result in map process : {res}"); // Do some computation with actor's state or context Ok(res) }), ) } } #[derive(Message)] #[rtype(result = "Result<String, ()>")] // return http reponse body struct Msg5; struct MyActor5; impl Actor for MyActor5 { type Context = Context<Self>; } impl Handler<Msg5> for MyActor5 { // type Result = ResponseActFuture<Self, Result<usize, ()>>; type Result = ResponseActFuture<Self, Result<String, ()>>; fn handle(&mut self, _: Msg5, _: &mut Context<Self>) -> Self::Result { // let res = reqwest::get("https://hyper.rs").await?; // println!("Status: {}", res.status()); // let body = res.text().await?; Box::pin( async { let status_code = match reqwest::get("https://hyper.rs").await { Ok(response) => { println!("Reponse Ok from hyper.rs {}", response.status()); match response.text().await { Ok(body) => body, Err(err) => { format!("Convert Reposne to string error : {err}") } } }, Err(err) => { format!("Reposne error from hyper.rs, error : {err}") }, }; status_code } .into_actor(self) // converts future to ActorFuture .map(|res, _act, _ctx| { println!("result in map process : {res}"); // Do some computation with actor's state or context Ok(res) }), ) } } fn main() -> Result<()> { let mut sys = actix::System::new(); sys.block_on(async { // let _addr = MyActor {}.start(); // let _addr = MyActor2 {}.start(); // let addr = MyActor3 {}.start(); // addr.do_send(Msg3 {}) // OK // let addr = MyActor4 {}.start(); // addr.do_send(Msg4 {}) // OK let addr = MyActor5 {}.start(); addr.do_send(Msg5 {}) }); sys.run()?; Ok(()) }
Send http request in started function
use actix::prelude::*; use actix::utils::IntervalFunc; use std::sync::Arc; use std::time::Duration; use tokio::sync::oneshot::channel; use tokio::sync::Mutex; #[derive(Clone)] struct MyActor { status_code: Option<u16>, } impl MyActor { fn tick(&mut self, context: &mut Context<Self>) { println!("tick"); } fn print_status_code(&mut self, context: &mut Context<Self>) { println!("status code: {:?}", self.status_code); } } impl Actor for MyActor { type Context = Context<Self>; fn started(&mut self, context: &mut Context<Self>) { println!("In started"); // ✅NOTE: This will run context.wait( async move { // send http reqwest let status_code = match reqwest::get("https://hyper.rs").await { Ok(response) => { println!( "Got status from hyper.rs {}", response.status() ); response.status().as_u16() } Err(err) => { println!("get response error : {err}"); 42 as u16 } }; println!("status code: {status_code}"); status_code } .into_actor(self) .then(|output, s, ctx| { s.status_code = Some(output); fut::ready(()) }), ); IntervalFunc::new(Duration::from_millis(5000), Self::print_status_code) .finish() .spawn(context); context.run_later(Duration::from_millis(20000), |_, _| { System::current().stop() }); } } fn main() { let mut sys = System::new(); let addr = sys.block_on(async { MyActor { status_code: None }.start() }); sys.run(); }
Appendix
Actor trait
/// Actors are objects which encapsulate state and behavior. /// /// Actors run within a specific execution context /// [`Context<A>`](struct.Context.html). The context object is available /// only during execution. Each actor has a separate execution /// context. The execution context also controls the lifecycle of an /// actor. /// /// Actors communicate exclusively by exchanging messages. The sender /// actor can wait for a response. Actors are not referenced directly, /// but by address [`Addr`](struct.Addr.html) To be able to handle a /// specific message actor has to provide a /// [`Handler<M>`](trait.Handler.html) implementation for this /// message. All messages are statically typed. A message can be /// handled in asynchronous fashion. An actor can spawn other actors /// or add futures or streams to the execution context. The actor /// trait provides several methods that allow controlling the actor /// lifecycle. /// /// # Actor lifecycle /// /// ## Started /// /// An actor starts in the `Started` state, during this state the /// `started` method gets called. /// /// ## Running /// /// After an actor's `started` method got called, the actor /// transitions to the `Running` state. An actor can stay in the /// `running` state for an indefinite amount of time. /// /// ## Stopping /// /// The actor's execution state changes to `stopping` in the following /// situations: /// /// * `Context::stop` gets called by actor itself /// * all addresses to the actor get dropped /// * no evented objects are registered in its context. /// /// An actor can return from the `stopping` state to the `running` /// state by creating a new address or adding an evented object, like /// a future or stream, in its `Actor::stopping` method. /// /// If an actor changed to a `stopping` state because /// `Context::stop()` got called, the context then immediately stops /// processing incoming messages and calls the `Actor::stopping()` /// method. If an actor does not return back to a `running` state, /// all unprocessed messages get dropped. /// /// ## Stopped /// /// If an actor does not modify execution context while in stopping /// state, the actor state changes to `Stopped`. This state is /// considered final and at this point the actor gets dropped. #[allow(unused_variables)] pub trait Actor: Sized + Unpin + 'static { /// Actor execution context type type Context: ActorContext; /// Called when an actor gets polled the first time. fn started(&mut self, ctx: &mut Self::Context) {} /// Called after an actor is in `Actor::Stopping` state. /// /// There can be several reasons for stopping: /// /// - `Context::stop` gets called by the actor itself. /// - All addresses to the current actor get dropped and no more /// evented objects are left in the context. /// /// An actor can return from the stopping state to the running /// state by returning `Running::Continue`. fn stopping(&mut self, ctx: &mut Self::Context) -> Running { Running::Stop } /// Called after an actor is stopped. /// /// This method can be used to perform any needed cleanup work or /// to spawn more actors. This is the final state, after this /// method got called, the actor will be dropped. fn stopped(&mut self, ctx: &mut Self::Context) {} /// Start a new asynchronous actor, returning its address. /// /// # Examples /// /// ``` /// use actix::prelude::*; /// /// struct MyActor; /// impl Actor for MyActor { /// type Context = Context<Self>; /// } /// /// #[actix::main] /// async fn main() { /// // start actor and get its address /// let addr = MyActor.start(); /// # System::current().stop(); /// } /// ``` fn start(self) -> Addr<Self> where Self: Actor<Context = Context<Self>>, { Context::new().run(self) } /// Construct and start a new asynchronous actor, returning its /// address. /// /// This is constructs a new actor using the `Default` trait, and /// invokes its `start` method. fn start_default() -> Addr<Self> where Self: Actor<Context = Context<Self>> + Default, { Self::default().start() } /// Start new actor in arbiter's thread. fn start_in_arbiter<F>(wrk: &ArbiterHandle, f: F) -> Addr<Self> where Self: Actor<Context = Context<Self>>, F: FnOnce(&mut Context<Self>) -> Self + Send + 'static, { let (tx, rx) = channel::channel(DEFAULT_CAPACITY); // create actor wrk.spawn_fn(move || { let mut ctx = Context::with_receiver(rx); let act = f(&mut ctx); let fut = ctx.into_future(act); actix_rt::spawn(fut); }); Addr::new(tx) } /// Start a new asynchronous actor given a `Context`. /// /// Use this method if you need the `Context` object during actor /// initialization. /// /// # Examples /// /// ``` /// use actix::prelude::*; /// /// struct MyActor { /// val: usize, /// } /// impl Actor for MyActor { /// type Context = Context<Self>; /// } /// /// #[actix::main] /// async fn main() { /// let addr = MyActor::create(|ctx: &mut Context<MyActor>| MyActor { val: 10 }); /// # System::current().stop(); /// } /// ``` fn create<F>(f: F) -> Addr<Self> where Self: Actor<Context = Context<Self>>, F: FnOnce(&mut Context<Self>) -> Self, { let mut ctx = Context::new(); let act = f(&mut ctx); ctx.run(act) } }
How Hyper Server setup
hello.rs from offcial hyper repository
Below is a simple example of how to set up a Hyper server that listens for incoming HTTP requests and responds with "Hello World !". This example uses Tokio for asynchronous I/O and is structured to run in an asynchronous context.
#![deny(warnings)] use std::convert::Infallible; use std::net::SocketAddr; use bytes::Bytes; use http_body_util::Full; use hyper::server::conn::http1; use hyper::service::service_fn; use hyper::{Request, Response}; use tokio::net::TcpListener; // This would normally come from the `hyper-util` crate, but we can't depend // on that here because it would be a cyclical dependency. #[path = "../benches/support/mod.rs"] mod support; use support::{TokioIo, TokioTimer}; // An async function that consumes a request, does nothing with it and returns a // response. async fn hello(_: Request<impl hyper::body::Body>) -> Result<Response<Full<Bytes>>, Infallible> { Ok(Response::new(Full::new(Bytes::from("Hello World !")))) } #[tokio::main] pub async fn main() -> Result<(), Box<dyn std::error::Error + Send + Sync>> { pretty_env_logger::init(); // This address is localhost let addr: SocketAddr = ([127, 0, 0, 1], 3000).into(); // Bind to the port and listen for incoming TCP connections let listener = TcpListener::bind(addr).await?; println!("Listening on http://{}", addr); loop { // When an incoming TCP connection is received grab a TCP stream for // client<->server communication. // // Note, this is a .await point, this loop will loop forever but is not a busy loop. The // .await point allows the Tokio runtime to pull the task off of the thread until the task // has work to do. In this case, a connection arrives on the port we are listening on and // the task is woken up, at which point the task is then put back on a thread, and is // driven forward by the runtime, eventually yielding a TCP stream. let (tcp, _) = listener.accept().await?; // Use an adapter to access something implementing `tokio::io` traits as if they implement // `hyper::rt` IO traits. let io = TokioIo::new(tcp); // Spin up a new task in Tokio so we can continue to listen for new TCP connection on the // current task without waiting for the processing of the HTTP1 connection we just received // to finish tokio::task::spawn(async move { // Handle the connection from the client using HTTP1 and pass any // HTTP requests received on that connection to the `hello` function if let Err(err) = http1::Builder::new() .timer(TokioTimer::new()) .serve_connection(io, service_fn(hello)) .await { println!("Error serving connection: {:?}", err); } }); } }
First look
- use tokio::main macro to wrapper up async main function
- use SocketAddr to define the address to bind to
- use TcpListener to bind to a port and listen for incoming connections
- use loop to continuously accept incoming connections
- use listener.accept() to wait for an incoming connection
- use TokioIo to adapt the TCP stream to the hyper IO traits
- use tokio::task::spawn to handle each connection in a separate task
- use http1::Builder to create an HTTP1 connection handler
- use service_fn to create a service that handles requests
- use serve_connection from Builder to create Connection to handle client requests
Deep dive
TokioIo
TokioIo is a wrapper that implements Tokio's IO traits for an inner type that implements hyper's IO traits, or vice versa.
It allows you to use hyper's IO traits with types that implement Tokio's IO traits, and vice versa.
#![allow(unused)] fn main() { pin_project! { /// A wrapper that implements Tokio's IO traits for an inner type that /// implements hyper's IO traits, or vice versa (implements hyper's IO /// traits for a type that implements Tokio's IO traits). #[derive(Debug)] pub struct TokioIo<T> { #[pin] inner: T, } } impl<T> hyper::rt::Read for TokioIo<T> where T: tokio::io::AsyncRead, { fn poll_read( self: Pin<&mut Self>, cx: &mut Context<'_>, mut buf: hyper::rt::ReadBufCursor<'_>, ) -> Poll<Result<(), std::io::Error>> { let n = unsafe { let mut tbuf = tokio::io::ReadBuf::uninit(buf.as_mut()); match tokio::io::AsyncRead::poll_read(self.project().inner, cx, &mut tbuf) { Poll::Ready(Ok(())) => tbuf.filled().len(), other => return other, } }; unsafe { buf.advance(n); } Poll::Ready(Ok(())) } } impl<T> hyper::rt::Write for TokioIo<T> where T: tokio::io::AsyncWrite, { fn poll_write( self: Pin<&mut Self>, cx: &mut Context<'_>, buf: &[u8], ) -> Poll<Result<usize, std::io::Error>> { tokio::io::AsyncWrite::poll_write(self.project().inner, cx, buf) } fn poll_flush(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), std::io::Error>> { tokio::io::AsyncWrite::poll_flush(self.project().inner, cx) } fn poll_shutdown( self: Pin<&mut Self>, cx: &mut Context<'_>, ) -> Poll<Result<(), std::io::Error>> { tokio::io::AsyncWrite::poll_shutdown(self.project().inner, cx) } fn is_write_vectored(&self) -> bool { tokio::io::AsyncWrite::is_write_vectored(&self.inner) } fn poll_write_vectored( self: Pin<&mut Self>, cx: &mut Context<'_>, bufs: &[std::io::IoSlice<'_>], ) -> Poll<Result<usize, std::io::Error>> { tokio::io::AsyncWrite::poll_write_vectored(self.project().inner, cx, bufs) } } impl<T> tokio::io::AsyncRead for TokioIo<T> where T: hyper::rt::Read, { fn poll_read( self: Pin<&mut Self>, cx: &mut Context<'_>, tbuf: &mut tokio::io::ReadBuf<'_>, ) -> Poll<Result<(), std::io::Error>> { //let init = tbuf.initialized().len(); let filled = tbuf.filled().len(); let sub_filled = unsafe { let mut buf = hyper::rt::ReadBuf::uninit(tbuf.unfilled_mut()); match hyper::rt::Read::poll_read(self.project().inner, cx, buf.unfilled()) { Poll::Ready(Ok(())) => buf.filled().len(), other => return other, } }; let n_filled = filled + sub_filled; // At least sub_filled bytes had to have been initialized. let n_init = sub_filled; unsafe { tbuf.assume_init(n_init); tbuf.set_filled(n_filled); } Poll::Ready(Ok(())) } } impl<T> tokio::io::AsyncWrite for TokioIo<T> where T: hyper::rt::Write, { fn poll_write( self: Pin<&mut Self>, cx: &mut Context<'_>, buf: &[u8], ) -> Poll<Result<usize, std::io::Error>> { hyper::rt::Write::poll_write(self.project().inner, cx, buf) } fn poll_flush(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), std::io::Error>> { hyper::rt::Write::poll_flush(self.project().inner, cx) } fn poll_shutdown( self: Pin<&mut Self>, cx: &mut Context<'_>, ) -> Poll<Result<(), std::io::Error>> { hyper::rt::Write::poll_shutdown(self.project().inner, cx) } fn is_write_vectored(&self) -> bool { hyper::rt::Write::is_write_vectored(&self.inner) } fn poll_write_vectored( self: Pin<&mut Self>, cx: &mut Context<'_>, bufs: &[std::io::IoSlice<'_>], ) -> Poll<Result<usize, std::io::Error>> { hyper::rt::Write::poll_write_vectored(self.project().inner, cx, bufs) } } }
Builder
Builder is used to configure the HTTP/1 server connection. It allows you to set various options such as half-close behavior, keep-alive settings, header case sensitivity, maximum buffer size, and more.
/// A configuration builder for HTTP/1 server connections. /// /// **Note**: The default values of options are *not considered stable*. They /// are subject to change at any time. /// /// # Example /// /// ``` /// # use std::time::Duration; /// # use hyper::server::conn::http1::Builder; /// # fn main() { /// let mut http = Builder::new(); /// // Set options one at a time /// http.half_close(false); /// /// // Or, chain multiple options /// http.keep_alive(false).title_case_headers(true).max_buf_size(8192); /// /// # } /// ``` /// /// Use [`Builder::serve_connection`](struct.Builder.html#method.serve_connection) /// to bind the built connection to a service. #[derive(Clone, Debug)] pub struct Builder { h1_parser_config: httparse::ParserConfig, timer: Time, h1_half_close: bool, h1_keep_alive: bool, h1_title_case_headers: bool, h1_preserve_header_case: bool, h1_max_headers: Option<usize>, h1_header_read_timeout: Dur, h1_writev: Option<bool>, max_buf_size: Option<usize>, pipeline_flush: bool, date_header: bool, }
Let's see how serve_connection is used to create a Connection future that processes all HTTP state for the IO object.
impl Builder { /// Bind a connection together with a [`Service`](crate::service::Service). /// /// This returns a Future that must be polled in order for HTTP to be /// driven on the connection. /// /// # Panics /// /// If a timeout option has been configured, but a `timer` has not been /// provided, calling `serve_connection` will panic. /// /// # Example /// /// ``` /// # use hyper::{body::Incoming, Request, Response}; /// # use hyper::service::Service; /// # use hyper::server::conn::http1::Builder; /// # use hyper::rt::{Read, Write}; /// # async fn run<I, S>(some_io: I, some_service: S) /// # where /// # I: Read + Write + Unpin + Send + 'static, /// # S: Service<hyper::Request<Incoming>, Response=hyper::Response<Incoming>> + Send + 'static, /// # S::Error: Into<Box<dyn std::error::Error + Send + Sync>>, /// # S::Future: Send, /// # { /// let http = Builder::new(); /// let conn = http.serve_connection(some_io, some_service); /// /// if let Err(e) = conn.await { /// eprintln!("server connection error: {}", e); /// } /// # } /// # fn main() {} /// ``` pub fn serve_connection<I, S>(&self, io: I, service: S) -> Connection<I, S> where S: HttpService<IncomingBody>, S::Error: Into<Box<dyn StdError + Send + Sync>>, S::ResBody: 'static, <S::ResBody as Body>::Error: Into<Box<dyn StdError + Send + Sync>>, I: Read + Write + Unpin, { let mut conn = proto::Conn::new(io); conn.set_h1_parser_config(self.h1_parser_config.clone()); conn.set_timer(self.timer.clone()); if !self.h1_keep_alive { conn.disable_keep_alive(); } if self.h1_half_close { conn.set_allow_half_close(); } if self.h1_title_case_headers { conn.set_title_case_headers(); } if self.h1_preserve_header_case { conn.set_preserve_header_case(); } if let Some(max_headers) = self.h1_max_headers { conn.set_http1_max_headers(max_headers); } if let Some(dur) = self .timer .check(self.h1_header_read_timeout, "header_read_timeout") { conn.set_http1_header_read_timeout(dur); }; if let Some(writev) = self.h1_writev { if writev { conn.set_write_strategy_queue(); } else { conn.set_write_strategy_flatten(); } } conn.set_flush_pipeline(self.pipeline_flush); if let Some(max) = self.max_buf_size { conn.set_max_buf_size(max); } if !self.date_header { conn.disable_date_header(); } let sd = proto::h1::dispatch::Server::new(service); let proto = proto::h1::Dispatcher::new(sd, conn); Connection { conn: proto } } }
There are several steps to create a Connection from the Builder:
#![allow(unused)] fn main() { let mut conn = proto::Conn::new(io); let sd = proto::h1::dispatch::Server::new(service); let proto = proto::h1::Dispatcher::new(sd, conn); Connection { conn: proto } }
Conn
The Conn struct is a low-level representation of an HTTP connection. It wrappers an IO object that implements Read and Write, and manages the state of the connection, including parsing incoming messages and writing responses.
The Buffered type is used to handle buffered I/O, allowing for efficient reading and writing of data.
#![allow(unused)] fn main() { /// This handles a connection, which will have been established over an /// `Read + Write` (like a socket), and will likely include multiple /// `Transaction`s over HTTP. /// /// The connection will determine when a message begins and ends as well as /// determine if this connection can be kept alive after the message, /// or if it is complete. pub(crate) struct Conn<I, B, T> { io: Buffered<I, EncodedBuf<B>>, state: State, _marker: PhantomData<fn(T)>, } }
Server
The Server struct is a wrapper around a service(service: S) that handles HTTP requests.
We've implemented the Dispatch trait for Server, which allows dispatcher to receive messages, poll incoming messages.
recv_msg is used to receive a message, which includes the request head and body.
It creates a new request and calls the service with it, setting the in_flight future to the service's response.
Later, poll_msg is used to poll the in-flight future and return the response when it's ready.
#![allow(unused)] fn main() { use crate::service::HttpService; pub(crate) struct Server<S: HttpService<B>, B> { in_flight: Pin<Box<Option<S::Future>>>, pub(crate) service: S, } impl<S, B> Server<S, B> where S: HttpService<B>, { pub(crate) fn new(service: S) -> Server<S, B> { Server { in_flight: Box::pin(None), service, } } pub(crate) fn into_service(self) -> S { self.service } } // Service is never pinned impl<S: HttpService<B>, B> Unpin for Server<S, B> {} impl<S, Bs> Dispatch for Server<S, IncomingBody> where S: HttpService<IncomingBody, ResBody = Bs>, S::Error: Into<Box<dyn StdError + Send + Sync>>, Bs: Body, { type PollItem = MessageHead<http::StatusCode>; type PollBody = Bs; type PollError = S::Error; type RecvItem = RequestHead; fn poll_msg( mut self: Pin<&mut Self>, cx: &mut Context<'_>, ) -> Poll<Option<Result<(Self::PollItem, Self::PollBody), Self::PollError>>> { let mut this = self.as_mut(); let ret = if let Some(ref mut fut) = this.in_flight.as_mut().as_pin_mut() { let resp = ready!(fut.as_mut().poll(cx)?); let (parts, body) = resp.into_parts(); let head = MessageHead { version: parts.version, subject: parts.status, headers: parts.headers, extensions: parts.extensions, }; Poll::Ready(Some(Ok((head, body)))) } else { unreachable!("poll_msg shouldn't be called if no inflight"); }; // Since in_flight finished, remove it this.in_flight.set(None); ret } fn recv_msg(&mut self, msg: crate::Result<(Self::RecvItem, IncomingBody)>) -> crate::Result<()> { let (msg, body) = msg?; let mut req = Request::new(body); *req.method_mut() = msg.subject.0; *req.uri_mut() = msg.subject.1; *req.headers_mut() = msg.headers; *req.version_mut() = msg.version; *req.extensions_mut() = msg.extensions; let fut = self.service.call(req); self.in_flight.set(Some(fut)); Ok(()) } fn poll_ready(&mut self, _cx: &mut Context<'_>) -> Poll<Result<(), ()>> { if self.in_flight.is_some() { Poll::Pending } else { Poll::Ready(Ok(())) } } fn should_poll(&self) -> bool { self.in_flight.is_some() } } }
Dispatcher
Dispatcher is a struct that stores the connection(Conn) and the dispatch(Server).
We also implement the Future trait for Dispatcher, allowing it to be polled for incoming requests.
It will call poll_catch to handle the incoming messages and process them.
#![allow(unused)] fn main() { pub(crate) struct Dispatcher<D, Bs: Body, I, T> { conn: Conn<I, Bs::Data, T>, dispatch: D, body_tx: Option<crate::body::Sender>, body_rx: Pin<Box<Option<Bs>>>, is_closing: bool, } impl<D, Bs, I, T> Future for Dispatcher<D, Bs, I, T> where D: Dispatch< PollItem = MessageHead<T::Outgoing>, PollBody = Bs, RecvItem = MessageHead<T::Incoming>, > + Unpin, D::PollError: Into<Box<dyn StdError + Send + Sync>>, I: Read + Write + Unpin, T: Http1Transaction + Unpin, Bs: Body + 'static, Bs::Error: Into<Box<dyn StdError + Send + Sync>>, { type Output = crate::Result<Dispatched>; #[inline] fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { self.poll_catch(cx, true) } } impl<D, Bs, I, T> Dispatcher<D, Bs, I, T> where D: Dispatch< PollItem = MessageHead<T::Outgoing>, PollBody = Bs, RecvItem = MessageHead<T::Incoming>, > + Unpin, D::PollError: Into<Box<dyn StdError + Send + Sync>>, I: Read + Write + Unpin, T: Http1Transaction + Unpin, Bs: Body + 'static, Bs::Error: Into<Box<dyn StdError + Send + Sync>>, { fn poll_catch( &mut self, cx: &mut Context<'_>, should_shutdown: bool, ) -> Poll<crate::Result<Dispatched>> { Poll::Ready(ready!(self.poll_inner(cx, should_shutdown)).or_else(|e| { // Be sure to alert a streaming body of the failure. if let Some(mut body) = self.body_tx.take() { body.send_error(crate::Error::new_body("connection error")); } // An error means we're shutting down either way. // We just try to give the error to the user, // and close the connection with an Ok. If we // cannot give it to the user, then return the Err. self.dispatch.recv_msg(Err(e))?; Ok(Dispatched::Shutdown) })) } fn poll_inner( &mut self, cx: &mut Context<'_>, should_shutdown: bool, ) -> Poll<crate::Result<Dispatched>> { T::update_date(); ready!(self.poll_loop(cx))?; if self.is_done() { if let Some(pending) = self.conn.pending_upgrade() { self.conn.take_error()?; return Poll::Ready(Ok(Dispatched::Upgrade(pending))); } else if should_shutdown { ready!(self.conn.poll_shutdown(cx)).map_err(crate::Error::new_shutdown)?; } self.conn.take_error()?; Poll::Ready(Ok(Dispatched::Shutdown)) } else { Poll::Pending } } fn poll_loop(&mut self, cx: &mut Context<'_>) -> Poll<crate::Result<()>> { // Limit the looping on this connection, in case it is ready far too // often, so that other futures don't starve. // // 16 was chosen arbitrarily, as that is number of pipelined requests // benchmarks often use. Perhaps it should be a config option instead. for _ in 0..16 { let _ = self.poll_read(cx)?; let _ = self.poll_write(cx)?; let _ = self.poll_flush(cx)?; // This could happen if reading paused before blocking on IO, // such as getting to the end of a framed message, but then // writing/flushing set the state back to Init. In that case, // if the read buffer still had bytes, we'd want to try poll_read // again, or else we wouldn't ever be woken up again. // // Using this instead of task::current() and notify() inside // the Conn is noticeably faster in pipelined benchmarks. if !self.conn.wants_read_again() { //break; return Poll::Ready(Ok(())); } } trace!("poll_loop yielding (self = {:p})", self); task::yield_now(cx).map(|never| match never {}) } fn poll_read(&mut self, cx: &mut Context<'_>) -> Poll<crate::Result<()>> { loop { if self.is_closing { return Poll::Ready(Ok(())); } else if self.conn.can_read_head() { ready!(self.poll_read_head(cx))?; } else if let Some(mut body) = self.body_tx.take() { if self.conn.can_read_body() { match body.poll_ready(cx) { Poll::Ready(Ok(())) => (), Poll::Pending => { self.body_tx = Some(body); return Poll::Pending; } Poll::Ready(Err(_canceled)) => { // user doesn't care about the body // so we should stop reading trace!("body receiver dropped before eof, draining or closing"); self.conn.poll_drain_or_close_read(cx); continue; } } match self.conn.poll_read_body(cx) { Poll::Ready(Some(Ok(frame))) => { if frame.is_data() { let chunk = frame.into_data().unwrap_or_else(|_| unreachable!()); match body.try_send_data(chunk) { Ok(()) => { self.body_tx = Some(body); } Err(_canceled) => { if self.conn.can_read_body() { trace!("body receiver dropped before eof, closing"); self.conn.close_read(); } } } } else if frame.is_trailers() { let trailers = frame.into_trailers().unwrap_or_else(|_| unreachable!()); match body.try_send_trailers(trailers) { Ok(()) => { self.body_tx = Some(body); } Err(_canceled) => { if self.conn.can_read_body() { trace!("body receiver dropped before eof, closing"); self.conn.close_read(); } } } } else { // we should have dropped all unknown frames in poll_read_body error!("unexpected frame"); } } Poll::Ready(None) => { // just drop, the body will close automatically } Poll::Pending => { self.body_tx = Some(body); return Poll::Pending; } Poll::Ready(Some(Err(e))) => { body.send_error(crate::Error::new_body(e)); } } } else { // just drop, the body will close automatically } } else { return self.conn.poll_read_keep_alive(cx); } } } fn poll_read_head(&mut self, cx: &mut Context<'_>) -> Poll<crate::Result<()>> { // can dispatch receive, or does it still care about other incoming message? match ready!(self.dispatch.poll_ready(cx)) { Ok(()) => (), Err(()) => { trace!("dispatch no longer receiving messages"); self.close(); return Poll::Ready(Ok(())); } } // dispatch is ready for a message, try to read one match ready!(self.conn.poll_read_head(cx)) { Some(Ok((mut head, body_len, wants))) => { let body = match body_len { DecodedLength::ZERO => IncomingBody::empty(), other => { let (tx, rx) = IncomingBody::new_channel(other, wants.contains(Wants::EXPECT)); self.body_tx = Some(tx); rx } }; if wants.contains(Wants::UPGRADE) { let upgrade = self.conn.on_upgrade(); debug_assert!(!upgrade.is_none(), "empty upgrade"); debug_assert!( head.extensions.get::<OnUpgrade>().is_none(), "OnUpgrade already set" ); head.extensions.insert(upgrade); } self.dispatch.recv_msg(Ok((head, body)))?; Poll::Ready(Ok(())) } Some(Err(err)) => { debug!("read_head error: {}", err); self.dispatch.recv_msg(Err(err))?; // if here, the dispatcher gave the user the error // somewhere else. we still need to shutdown, but // not as a second error. self.close(); Poll::Ready(Ok(())) } None => { // read eof, the write side will have been closed too unless // allow_read_close was set to true, in which case just do // nothing... debug_assert!(self.conn.is_read_closed()); if self.conn.is_write_closed() { self.close(); } Poll::Ready(Ok(())) } } } fn poll_write(&mut self, cx: &mut Context<'_>) -> Poll<crate::Result<()>> { loop { if self.is_closing { return Poll::Ready(Ok(())); } else if self.body_rx.is_none() && self.conn.can_write_head() && self.dispatch.should_poll() { if let Some(msg) = ready!(Pin::new(&mut self.dispatch).poll_msg(cx)) { let (head, body) = msg.map_err(crate::Error::new_user_service)?; let body_type = if body.is_end_stream() { self.body_rx.set(None); None } else { let btype = body .size_hint() .exact() .map(BodyLength::Known) .or(Some(BodyLength::Unknown)); self.body_rx.set(Some(body)); btype }; self.conn.write_head(head, body_type); } else { self.close(); return Poll::Ready(Ok(())); } } else if !self.conn.can_buffer_body() { ready!(self.poll_flush(cx))?; } else { // A new scope is needed :( if let (Some(mut body), clear_body) = OptGuard::new(self.body_rx.as_mut()).guard_mut() { debug_assert!(!*clear_body, "opt guard defaults to keeping body"); if !self.conn.can_write_body() { trace!( "no more write body allowed, user body is_end_stream = {}", body.is_end_stream(), ); *clear_body = true; continue; } let item = ready!(body.as_mut().poll_frame(cx)); if let Some(item) = item { let frame = item.map_err(|e| { *clear_body = true; crate::Error::new_user_body(e) })?; if frame.is_data() { let chunk = frame.into_data().unwrap_or_else(|_| unreachable!()); let eos = body.is_end_stream(); if eos { *clear_body = true; if chunk.remaining() == 0 { trace!("discarding empty chunk"); self.conn.end_body()?; } else { self.conn.write_body_and_end(chunk); } } else { if chunk.remaining() == 0 { trace!("discarding empty chunk"); continue; } self.conn.write_body(chunk); } } else if frame.is_trailers() { *clear_body = true; self.conn.write_trailers( frame.into_trailers().unwrap_or_else(|_| unreachable!()), ); } else { trace!("discarding unknown frame"); continue; } } else { *clear_body = true; self.conn.end_body()?; } } else { // If there's no body_rx, end the body if self.conn.can_write_body() { self.conn.end_body()?; } else { return Poll::Pending; } } } } } } }
pollwill callpoll_catchto process the connection and handle incoming messages.poll_catchwill callpoll_inner, except when an error occurs, it will send an error to the body and returnDispatched::Shutdown.poll_innerwill callpoll_loopand check if the connection is done. If it is done, it will check for pending upgrades or shutdown the connection.poll_loopwill loop up to 16 times, polling for read, write, and flush operations on the connection. Thepoll_read,poll_write, andpoll_flushmethods are responsible for handling the actual I/O operations.
Connection
Now, let's look at how Connection is defined and how it uses the Dispatcher.
Connection is a future that processes all HTTP state for the IO object.
Internally, it uses a Dispatcher to manage the state of the connection and handle incoming and outgoing messages.
The Connection future is designed to be spawned into an executor, allowing it to process requests asynchronously.
The inner field of Connection is an instance of Dispatcher, which handles the actual HTTP processing.
#![allow(unused)] fn main() { /// A future that processes all HTTP state for the IO object. /// /// In most cases, this should just be spawned into an executor, so that it /// can process incoming and outgoing messages, notice hangups, and the like. /// /// Instances of this type are typically created via the [`handshake`] function #[must_use = "futures do nothing unless polled"] pub struct Connection<T, B> where T: Read + Write, B: Body + 'static, { // The inner dispatcher we creaed earlier, which implements the Future trait. // So that we can poll it to process the connection. inner: Dispatcher<T, B>, } impl<T, B> Future for Connection<T, B> where T: Read + Write + Unpin, B: Body + 'static, B::Data: Send, B::Error: Into<Box<dyn StdError + Send + Sync>>, { type Output = crate::Result<()>; fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { match ready!(Pin::new(&mut self.inner).poll(cx))? { proto::Dispatched::Shutdown => Poll::Ready(Ok(())), proto::Dispatched::Upgrade(pending) => { // With no `Send` bound on `I`, we can't try to do // upgrades here. In case a user was trying to use // `upgrade` with this API, send a special // error letting them know about that. pending.manual(); Poll::Ready(Ok(())) } } } } }
Serialize time::OffsetDataTime type using serde_as in serde_with crate
- Table design
- Database management using sqlx
- Writing Data Access Layer
- Write actix handler
- Request data through api
- Choose correct serialize method
- Request data through api after using serde_as
Table design
When we develop backend api using postgres and sqlx, you will definitely use date in your database design. Take user table as an example:
-- Add migration script here
CREATE TYPE gender AS ENUM ('male', 'female', 'other');
-- Table `users`
CREATE TABLE
IF NOT EXISTS users (
id BIGSERIAL PRIMARY KEY,
username TEXT UNIQUE NOT NULL,
gender GENDER NOT NULL,
disabled BOOLEAN NOT NULL DEFAULT FALSE,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW ()
);
In the provided example, the users table includes a created_at column of type TIMESTAMPTZ.
In PostgreSQL, the TIMESTAMPTZ data type stands for "timestamp with time zone."
Database management using sqlx
We can also use sqlx to generate migration and add the sql above to the migration script.
The following example will use sqlx, which is SQLx's associated command-line utility for managing databases, migrations, to create database and generate the migration.
# create database
DATABASE_URL=postgres://localhost/test sqlx database create
# create migration
DATABASE_URL=postgres://localhost/test sqlx migrate add user
We can list all migration scripts in migrations direction, which is generated by sqlx migrate add user command.
drwxr-xr-x - username 22 Aug 14:22 migrations
.rw-r--r-- 334 username 22 Aug 14:22 └── 20230822062052_user.sql
We added above sql to file 20230822062052_user.sql and sqlx will handle the migration.
Writing Data Access Layer
We can write an all_users function to fetch data from database using sqlx crate.
#![allow(unused)] fn main() { use serde::Serialize; use sqlx::PgPool; use time::OffsetDateTime; #[derive(Debug, Serialize)] pub struct User { pub id: i64, pub username: String, pub disabled: bool, pub gender: Gender, pub created_at: OffsetDateTime, } #[derive(Clone, PartialEq, PartialOrd, Serialize, sqlx::Type, Debug)] #[sqlx(type_name = "gender")] #[sqlx(rename_all = "lowercase")] pub enum Gender { Male, Female, Other, } impl User { pub async fn all(connection: &PgPool) -> Result<Vec<User>, sqlx::Error> { let users = sqlx::query_as!( User, r#" SELECT id, username, gender as "gender: _", disabled, created_at FROM users "# ) .fetch_all(connection) .await?; Ok(users) } } }
The code snippet above uses the sqlx crate to interact with a PostgreSQL database and retrieve user data.
- The
Userstruct represents a user entity and is serialized using the serde crate. It contains fields such asid,username,disabled,gender, andcreated_at, representing the corresponding columns in the database table. - The
Genderenum represents the possible genders a user can have. It is derived from Clone, PartialEq, PartialOrd, and Serialize. Thesqlx::Typetrait is implemented to specify that thisenumshould be treated as a PostgreSQL custom type named "gender". Thesqlx(rename_all)attribute is used to specify that the enum variants should be serialized in lowercase. You can refer to rename_all for more details. If you don't specifysqlx(rename_all), an error will occur:
thread 'actix-rt|system:0|arbiter:0' panicked at 'called `Result::unwrap()` on an `Err` value: ColumnDecode { index: "2", source: "invalid value \"male\" for enum Gender" }', enum-example/src/bin/enum.rs:33:45
- The
Userstruct also contains anallfunction that retrieves all users from the database. It takes a reference to aPgPoolconnection pool as a parameter and returns aResultwith a vector ofUserinstances or ansqlx::Errorif an error occurs. - Inside the
allfunction, a SQL query is defined using thesqlx::query_as!macro. It selects the necessary columns from theuserstable, including mapping thegendercolumn to theGenderenum using the as"gender: _"syntax. - Finally, the
fetch_allmethod is called on the query to execute it and retrieve all rows as a vector of User instances. The result is then returned as a Result.
Write actix handler
AppState
Once we have the code implemented, let's see how we can use it to retrieve user data from a PostgreSQL database.
First, we define AppState struct to represent the server's state, which contains two fields: app_name, a string representing the application name, and pool, a PgPool instance representing the connection pool to the PostgreSQL database.
You can also add more to AppState, i.e. redis client to exchange data from Redis or kafka client to send or receive messages from Kafka, etc.
#![allow(unused)] fn main() { // This struct represents state struct AppState { app_name: String, pool: PgPool, } }
Actix handler
Then, we define a handler for retrieving all users.
#![allow(unused)] fn main() { async fn all_users(data: web::Data<AppState>) -> Result<impl Responder> { let connection = &data.pool; let users = User::all(connection).await.unwrap(); Ok(web::Json(users)) } }
The all_users function is an asynchronous handler that retrieves all users from the database. It takes a web::Data parameter containing the shared AppState data. Inside the function, it accesses the PgPool instance from the shared data and uses the User model to fetch all users from the database asynchronously.
HttpServer setup
Next, we will create a PgPool instance and store the pool in application state variable, pass in a Data::new(AppState { ... }) instance using app_data method.
use sqlx::postgres::{PgPool, PgPoolOptions}; async fn main() -> std::io::Result<()> { env::set_var("RUST_LOG", "info"); env_logger::init(); let db_url = "postgres://localhost/test"; let pool = connect(db_url).await.unwrap(); HttpServer::new(move || { App::new() // .app_data(pool.clone()) .app_data(Data::new(AppState { app_name: "enum".into(), pool: pool.clone(), })) .service(web::scope("/api/v1").configure(config)) .route("/health", web::get().to(health)) }) .bind(("0.0.0.0", 8080))? .run() .await } /// Open a connection to a database pub async fn connect(db_url: &str) -> sqlx::Result<PgPool> { // NOTE: older version of sqlx use PgPool, for newer version use // PgPoolOptions::new to create a pool // // let pool = PgPool::new(db_url).await?; // Create a connection pool let pool = PgPoolOptions::new() .max_connections(5) // .connect("postgres://localhost/test") // .connect(&env::var("DATABASE_URL")?) .connect(db_url) .await?; Ok(pool) }
Config routes
Finally, we will configure routes for the application.
We can use configure method to configure routes by passing an function with F: FnOnce(&mut ServiceConfig) trait bound like this:
#![allow(unused)] fn main() { HttpServer::new(move || { App::new() // .app_data(pool.clone()) .app_data(Data::new(AppState { app_name: "enum".into(), pool: pool.clone(), })) // config routers .service(web::scope("/api/v1").configure(config)) .route("/health", web::get().to(health)) }) .bind(("0.0.0.0", 8080))? .run() .await }
Here is the signature for configure method:
#![allow(unused)] fn main() { pub fn configure<F>(mut self, cfg_fn: F) -> Self where F: FnOnce(&mut ServiceConfig); }
And our config method:
#![allow(unused)] fn main() { use actix_web::{ web::{self, Data, ServiceConfig}, web::{get, post, resource as r, scope}, App, Error, HttpRequest, HttpResponse, HttpServer, Responder, Result, }; // this function could be located in different module pub fn config(cfg: &mut ServiceConfig) { cfg // users .service(scope("/users").service( r("").route(get().to(all_users)), // .route(post().to(delete_user)), )); } }
Run the application
The application is configured with routes using the service and route methods. It includes a scope for API versioning with /api/v1 and sets up a route for a health check endpoint ("/health") and a route to retrieve all users ("/users").
With all things tied up, we can run application using cargo run or cargo run --bin <binary> if you have multiple binaries in you project:
Finished dev [unoptimized + debuginfo] target(s) in 2.73s
Running `target/debug/enum`
[2023-08-23T02:00:37Z INFO actix_server::builder] starting 10 workers
[2023-08-23T02:00:37Z INFO actix_server::server] Actix runtime found; starting in Actix runtime
Request data through api
Now it's time to test the api.
We can request the user data through /api/v1/users endpoint:
curl '0:8080/api/v1/users' | jq
Output:
[
{
"id": 1,
"username": "john_doe",
"disabled": false,
"gender": "Male",
"created_at": [2023, 234, 15, 3, 34, 422482000, 0, 0, 0]
},
{
"id": 2,
"username": "jane_smith",
"disabled": true,
"gender": "Female",
"created_at": [2023, 234, 15, 3, 34, 422482000, 0, 0, 0]
},
{
"id": 3,
"username": "alex_jones",
"disabled": false,
"gender": "Other",
"created_at": [2023, 234, 15, 3, 34, 422482000, 0, 0, 0]
}
]
We have some trouble. The created_at is returned as an array, which should be a string like this: 2023-08-22T15:03:34.422482Z. How to solve this problem?
Choose correct serialize method
To fix the serialization problem of OffsetDataTime data type in User struct, we need to specify corrent serialization method for created_at field.
We can use serce_with crate and use Rfc3339 in serde_as macro, which will serialize OffsetDataTime like this 1985-04-12T23:20:50.52Z instead of an array of integers [2023, 234, 15, 3, 34, 422482000, 0, 0, 0].
#![allow(unused)] fn main() { /// Well-known formats, typically standards. pub mod well_known { pub mod iso8601; mod rfc2822; mod rfc3339; #[doc(inline)] pub use iso8601::Iso8601; pub use rfc2822::Rfc2822; pub use rfc3339::Rfc3339; } }
You can use serde_with crate as follows:
- Place the
#[serde_as]attribute before the#[derive]attribute. - Use
#[serde_as(as = "...")] instead of#[serde(with = "...")]to annotate field in struct
Below is an example of using serde_with together with serde_as for User struct.
#![allow(unused)] fn main() { use time::format_description::well_known::Rfc3339; #[serde_with::serde_as] #[derive(Debug, Serialize)] pub struct User { pub id: i64, pub username: String, pub disabled: bool, pub gender: Gender, #[serde_as(as = "Rfc3339")] pub created_at: OffsetDateTime, } #[derive(Clone, PartialEq, PartialOrd, Serialize, sqlx::Type, Debug)] #[sqlx(type_name = "gender")] #[sqlx(rename_all = "lowercase")] pub enum Gender { Male, Female, Other, } }
Notice, we use #[serde_as(as = "Rfc3339")] to annotate created_at field with OffsetDataTime type.
It's quite convenient to use.
Request data through api after using serde_as
Now, when we request the data, we get the datetime as we wanted.
curl '0:8080/api/v1/users' | jq
Output:
[
{
"id": 1,
"username": "john_doe",
"disabled": false,
"gender": "Male",
"created_at": "2023-08-22T15:03:34.422482Z"
},
{
"id": 2,
"username": "jane_smith",
"disabled": true,
"gender": "Female",
"created_at": "2023-08-22T15:03:34.422482Z"
},
{
"id": 3,
"username": "alex_jones",
"disabled": false,
"gender": "Other",
"created_at": "2023-08-22T15:03:34.422482Z"
}
]
🎉🎉🎉
How to organise application Error in actix-web application
Into
In this article, we will learn how to organise application Error in actix-web application.
Every backend application has a dao layer(or data access object) and a http layer.
For dao layer, usually we use lib::Result as return type. Below is an example of fetching all users when using clickhosue-rs crate:
#![allow(unused)] fn main() { use clickhouse::error::{Error, Result}; pub async fn get_all_users(client: &Client) -> Result<Vec<User>> { let users = client .query("SELECT ?fields FROM users") .fetch_all::<User>() .await?; Ok(users) } }
Notice, the Result is not std::result::Result type, it is a type that use clickhouse::error::Error as the error type in Result generic type.
#![allow(unused)] fn main() { use std::{error::Error as StdError, fmt, io, result, str::Utf8Error}; use serde::{de, ser}; /// A result with a specified [`Error`] type. pub type Result<T, E = Error> = result::Result<T, E>; /// Represents all possible errors. #[derive(Debug, thiserror::Error)] #[non_exhaustive] #[allow(missing_docs)] pub enum Error { #[error("invalid params: {0}")] InvalidParams(#[source] Box<dyn StdError + Send + Sync>), #[error("network error: {0}")] Network(#[source] Box<dyn StdError + Send + Sync>), #[error("compression error: {0}")] Compression(#[source] Box<dyn StdError + Send + Sync>), #[error("decompression error: {0}")] Decompression(#[source] Box<dyn StdError + Send + Sync>), #[error("no rows returned by a query that expected to return at least one row")] RowNotFound, #[error("sequences must have a known size ahead of time")] SequenceMustHaveLength, #[error("`deserialize_any` is not supported")] DeserializeAnyNotSupported, #[error("not enough data, probably a row type mismatches a database schema")] NotEnoughData, #[error("string is not valid utf8")] InvalidUtf8Encoding(#[from] Utf8Error), #[error("tag for enum is not valid")] InvalidTagEncoding(usize), #[error("a custom error message from serde: {0}")] Custom(String), #[error("bad response: {0}")] BadResponse(String), #[error("timeout expired")] TimedOut, // Internally handled errors, not part of public API. // XXX: move to another error? #[error("internal error: too small buffer, need another {0} bytes")] #[doc(hidden)] TooSmallBuffer(usize), } }
Actix-web http layer
Actix-web framework requires the error type is actix_web::error::Error if actix_web::Result is used as the return type.
Result type in actix-web :
#![allow(unused)] fn main() { pub use self::error::Error; pub use self::internal::*; pub use self::response_error::ResponseError; pub(crate) use macros::{downcast_dyn, downcast_get_type_id}; /// A convenience [`Result`](std::result::Result) for Actix Web operations. /// /// This type alias is generally used to avoid writing out `actix_http::Error` directly. pub type Result<T, E = Error> = std::result::Result<T, E>; }
Error type in actix-web :
#![allow(unused)] fn main() { /// General purpose Actix Web error. /// /// An Actix Web error is used to carry errors from `std::error` through actix in a convenient way. /// It can be created through converting errors with `into()`. /// /// Whenever it is created from an external object a response error is created for it that can be /// used to create an HTTP response from it this means that if you have access to an actix `Error` /// you can always get a `ResponseError` reference from it. pub struct Error { cause: Box<dyn ResponseError>, } }
Normally, we write actix-web handler and call dao functions like this:
#![allow(unused)] fn main() { pub async fn get_all_users(data: web::Data<AppState>) -> actix_web::Result<impl Responder> { let db = &data.db; // call dao function to fetch data let users = users::get_all_users(db).await?; Ok(web::Json(users)) } }
If you write a http handler like this and call function in dao(i.e. dao::get_all_users) function, which returns an error from the dao crate, error will happen.
#![allow(unused)] fn main() { --> src/user/http.rs:348:54 | 348 | let users = users::get_all(db).await?; | ^ the trait `ResponseError` is not implemented for `clickhouse::error::Error` | = help: the following other types implement trait `ResponseError`: AppError BlockingError Box<(dyn StdError + 'static)> HttpError Infallible InvalidHeaderValue JsonPayloadError PathError and 17 others = note: required for `actix_web::Error` to implement `std::convert::From<clickhouse::error::Error>` = note: required for `Result<_, actix_web::Error>` to implement `FromResidual<Result<Infallible, clickhouse::error::Error>>` }
It means that you cannot convert clickhouse::error::Error to actix_web::Error.
The reason is that the error type in dao function is clickhouse::error::Error, not actix_web::Error. While in http handler, the error type is actix_web::Error . You have to implement From trait as rust compiler told you.
Solution
Solution 1: implement From trait manually
One possible solution is to define application error and implement From trait, which will convert clickhouse::error::Error to AppError:
#![allow(unused)] fn main() { // Define your application error in enum #[derive(Debug)] pub enum AppError { ClickhouseError(ClickhouseError), // ... other error variants } impl ResponseError for AppError { fn error_response(&self) -> HttpResponse { HttpResponse::InternalServerError().body(self.to_string()) // We can also use match to handle specific error define in clickhouse::error::Error // match *self { // AppError::ClickhouseError(ref err) => match err { // ClickhouseError::Timeout(err) => HttpResponse::InternalServerError() // .body(format!("Clickhouse server error: {}", err)), // ClickhouseError::Network(err) => { // HttpResponse::BadRequest().body(format!("Clickhouse client error: {}", err)) // } // _ => HttpResponse::InternalServerError().body("Unknown error"), // }, // ... handle other error variants // } } } use std::fmt; impl fmt::Display for AppError { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { match *self { AppError::ClickhouseError(ref err) => { write!(f, "Clickhouse error: {}", err) } // ... handle other error variants } } } impl From<ClickhouseError> for AppError { fn from(error: ClickhouseError) -> Self { AppError::ClickhouseError(error) } } }
Finally, you need to modify actix-web handler:
#![allow(unused)] fn main() { use clickhouse::error::{Error, Result}; // Previous function signature // pub async fn get_all_users(data: web::Data<AppState>) -> actix_web::Result<impl Responder> { // Pass AppError to handler's return type pub async fn get_all_users(data: web::Data<AppState>) -> actix_web::Result<impl Responder, AppError> { let db = &data.db; // call dao function to fetch data let users = users::get_all_users(db).await?; Ok(web::Json(users)) } }
🎉🎉🎉
Solution 2: use thiserror crate
Another solution is to use thiserror crate.
This crate will automatically implement From trait, which will do the conversion.
#![allow(unused)] fn main() { use thiserror::Error; use clickhouse::error::Error as ClickhouseError; use actix_web::{HttpResponse, ResponseError}; #[derive(Debug, Error)] pub enum AppError { #[error("Clickhouse error: {0}")] ClickhouseError(#[from] ClickhouseError), // You can add more error variants as needed #[error("Database connection error")] DatabaseConnectionError, #[error("Internal server error: {0}")] InternalError(String), } impl ResponseError for AppError { fn error_response(&self) -> HttpResponse { match self { AppError::ClickhouseError(_) => { HttpResponse::InternalServerError().body(self.to_string()) } AppError::DatabaseConnectionError => { HttpResponse::ServiceUnavailable().body(self.to_string()) } AppError::InternalError(_) => { HttpResponse::InternalServerError().body(self.to_string()) } } } } }
Here is the key improvements with thiserror:
- The
#[derive(Error)]automatically implementsstd::error::Error. #[error("...")]provides a convenient way to implementDisplaytrait.#[from]attribute automatically implementsFromtrait for error conversion.- The code is more concise and readable.
- You can easily add more error variants with custom error messages.
Benefits of this approach:
- Automatic error conversion
- Clear, descriptive error messages
- Easy to extend with new error types
- Consistent error handling across the application
The ResponseError implementation allows you to:
- Map different error types to appropriate HTTP status codes
- Provide meaningful error responses
- Easily customize error handling for different error variants
Note: Make sure to import necessary types and traits from the appropriate modules (actix-web, thiserror, etc.).
Below is the example of using thiserror crate:
// use actix_web::{get, post, web, App, HttpRequest, HttpResponse, HttpServer, Responder}; use actix_web::{ web, App, HttpServer, Responder}; use clickhouse::Client; use clickhouse_example::{dao::get_all_users, error::AppError}; // This struct represents state pub(crate) struct AppState { pub app_name: String, pub db: Client, } // NOTE: This function is not working because of error type mismatch // async fn get_users( // data: web::Data<AppState>, // ) -> actix_web::Result<impl Responder> { // let db = &data.db; // // call dao function to fetch data // let users = get_all_users(db).await?; // Ok(web::Json(users)) // } // Handler function pub(crate) async fn get_users(data: web::Data<AppState>) -> actix_web::Result<impl Responder, AppError> { let db = &data.db; // call dao function to fetch data let users = get_all_users(db).await?; Ok(web::Json(users)) } #[actix_web::main] async fn main() -> std::io::Result<()> { let url = "http://localhost:8123"; let database = "default"; let user = "test"; let password = "secret"; let client = Client::default() .with_url(url) .with_user(user) .with_password(password) .with_database(database); HttpServer::new(move || { App::new() .app_data(web::Data::new(AppState {db:client.clone(), app_name: "My App".into() })) .route("/users", web::get().to(get_users)) }) .bind(("127.0.0.1", 8080))? .run() .await }
Return error when unwrap Option when None
Intro
In this blog, we will learn how to handle optional values and return errors in Actix-Web Handlers.
In Rust, dealing with optional values (Option) and converting them to errors in web handlers is a common task. This blog explores different strategies to handle cases where an expected value is None.
When working with optional values, you have several idiomatic Rust approaches:
-
Using
matchto ConvertNoneto an Error- Explicitly match on the
Optiontype - Explicitly return an error when the value is
None
- Explicitly match on the
-
Using
ok_or_else()Method- Provides a concise way to convert
OptiontoResult - Allows lazy error generation
- Avoids unnecessary error creation if not needed
- Provides a concise way to convert
Let's explore these approaches with practical examples.
Application error
Suppose we define our application error like this:
#![allow(unused)] fn main() { use actix_web::{HttpResponse, ResponseError}; use clickhouse::error::Error as ClickhouseError; use std::fmt; #[derive(Debug)] pub enum AppError { ClickhouseError(ClickhouseError), ScheduleError(String), SQLGenError(String), } impl ResponseError for AppError { fn error_response(&self) -> HttpResponse { HttpResponse::InternalServerError().body(self.to_string()) // match *self { // AppError::ClickhouseError(ref err) => match err { // ClickhouseError::Server(err) => HttpResponse::InternalServerError() // .body(format!("Clickhouse server error: {}", err)), // ClickhouseError::Client(err) => { // HttpResponse::BadRequest().body(format!("Clickhouse client error: {}", err)) // } // _ => HttpResponse::InternalServerError().body("Unknown error"), // }, // ... handle other error variants // } } } impl fmt::Display for AppError { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { match *self { AppError::ClickhouseError(ref err) => { write!(f, "Clickhouse error: {}", err) } AppError::ScheduleError(ref err) => { write!(f, "Schedule error: {}", err) } AppError::SQLGenError(ref err) => { write!(f, "SQLGen error: {}", err) } } } } impl From<ClickhouseError> for AppError { fn from(error: ClickhouseError) -> Self { AppError::ClickhouseError(error) } } }
Function returns Result<String, AppError>
If we have a function which will return Result<String, AppError> type:
#![allow(unused)] fn main() { fn sql_gen_visualization_barchart( query: &VisualizationQuery, table_name: &str, //) -> Result<String, Box<dyn std::error::Error>> { //) -> anyhow::Result<String> { ) -> anyhow::Result<String, AppError> { // gen sql for visualization let mut sql = String::new(); let field = query.field.as_ref(); // ... } }
Solution
If we would like to return error when one of parameters is empty, we can do as follows.
Use match
#![allow(unused)] fn main() { let field = match field { Some(field) => field, None => return Err(AppError::SQLGenError("Field is empty".to_string())), }; }
By using match, we can easily return an error when field is None.
Use ok_or_else
If we don't like the match, we can leverage ok_or_else method, which will do the same way as using match.
#![allow(unused)] fn main() { let field = query .field .as_ref() .ok_or_else(|| AppError::SQLGenError("Field is empty".to_string()))?; }
Below is the source code of ok_or_else method:
#![allow(unused)] fn main() { impl<T> Option<T> { /// Transforms the `Option<T>` into a [`Result<T, E>`], mapping [`Some(v)`] to /// [`Ok(v)`] and [`None`] to [`Err(err())`]. /// /// [`Ok(v)`]: Ok /// [`Err(err())`]: Err /// [`Some(v)`]: Some /// /// # Examples /// /// ``` /// let x = Some("foo"); /// assert_eq!(x.ok_or_else(|| 0), Ok("foo")); /// /// let x: Option<&str> = None; /// assert_eq!(x.ok_or_else(|| 0), Err(0)); /// ``` #[inline] #[stable(feature = "rust1", since = "1.0.0")] pub fn ok_or_else<E, F>(self, err: F) -> Result<T, E> where F: FnOnce() -> E, { match self { Some(v) => Ok(v), None => Err(err()), } } } }
Extract Enum Variants in Rust
When working with large Rust enums, sometimes we need to extract just the variant names without their associated data. In this tutorial, we'll explore two approaches to extract enum variants: using Rust with the syn crate and using Python with regex.
The Problem
Let's say we have a large enum like TokenInstruction that looks like this:
#![allow(unused)] fn main() { pub enum TokenInstruction<'a> { InitializeMint { decimals: u8, mint_authority: Pubkey, freeze_authority: COption<Pubkey>, }, InitializeAccount, // ... many more variants } }
And we want to extract just the variant names to get something like:
#![allow(unused)] fn main() { pub enum TokenInstruction<'a> { InitializeMint {}, InitializeAccount {}, // ... other variants } }
Solution 1: Using Rust with syn
The first approach uses Rust's syn crate to parse the code as an AST (Abstract Syntax Tree) and extract the variants. Here's how we can do it:
use proc_macro2::TokenStream; use quote::quote; use std::env; use std::fs; use syn::parse_str; use syn::Item; fn main() { let args: Vec<String> = env::args().collect(); if args.len() != 2 { eprintln!("Usage: {} <rust_file>", args[0]); std::process::exit(1); } let file_path = &args[1]; let content = match fs::read_to_string(file_path) { Ok(content) => content, Err(e) => { eprintln!("Error reading file: {}", e); std::process::exit(1); } }; let ast = match syn::parse_file(&content) { Ok(ast) => ast, Err(e) => { eprintln!("Error parsing Rust file: {}", e); std::process::exit(1); } }; // Iterate AST to search for enum for item in ast.items { if let Item::Enum(item_enum) = item { let enum_name = &item_enum.ident; let generics = &item_enum.generics; // print enum header part println!("pub enum {}{} {{", enum_name, quote!(#generics)); // print each variant for variant in &item_enum.variants { let variant_name = &variant.ident; println!(" {} {{}},", variant_name); } // print end println!("}}"); } } }
This approach is more robust as it properly handles Rust syntax and preserves the enum's generic parameters.
Solution 2: Using Python with Regex
For a simpler but less robust approach, we can use Python with regular expressions:
import sys
from pathlib import Path
import re
def clean_rust_code(content):
# remove multiline comments
content = re.sub(r'///.*?\n', '\n', content, flags=re.MULTILINE)
# remove single comments
content = re.sub(r'//.*?\n', '\n', content)
return content
def extract_enum_variants(file_path):
with open(file_path, 'r') as f:
content = f.read()
# clean comments
content = clean_rust_code(content)
# extract enum name and generic parameter
enum_pattern = re.compile(r'pub\s+enum\s+(\w+)(<.*?>)?')
enum_match = enum_pattern.search(content)
if not enum_match:
print("No enum found")
return
enum_name = enum_match.group(1)
enum_generic = enum_match.group(2) or ''
# extract variants
variant_pattern = re.compile(r'\s+(\w+)(?:\s*{[^}]*}|\s*,)')
variants = variant_pattern.findall(content)
# build the output
output = [f"pub enum {enum_name}{enum_generic} {{"]
for variant in variants:
output.append(f" {variant} {{}},")
output.append("}")
print("\n".join(output))
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python extract_enum.py <file>")
sys.exit(1)
file_path = sys.argv[1]
if not Path(file_path).exists():
print(f"File {file_path} does not exist")
sys.exit(1)
extract_enum_variants(file_path)
Comparing the Approaches
| Approach | Pros | Cons |
|---|---|---|
| Rust with syn | • Properly handles Rust syntax • Maintains generic parameters • More reliable for complex enums | • Requires additional dependencies • More complex implementation |
| Python with regex | • Simpler implementation • No Rust-specific dependencies • Faster to implement | • Less robust • May break with complex Rust syntax • Regex patterns might need adjustment for edge cases |
Conclusion
Both approaches can help you extract enum variants, but choose based on your needs:
- Use the Rust approach for production code or when dealing with complex Rust syntax
- Use the Python approach for quick scripts or simple enums
Remember that the Rust approach using syn is generally more reliable as it properly parses the Rust syntax tree, while the Python regex approach is more suitable for quick, one-off tasks.
Macro Recusive Call
Understanding Recursive Macros in Rust
Rust macros are a powerful feature that allows for metaprogramming, enabling developers to write code that writes other code. One interesting aspect of macros is their ability to perform recursive calls. In this post, we will explore how to create a recursive macro in Rust, using a simple example.
What is a Macro?
A macro in Rust is a way to define code that can be reused and expanded at compile time. Macros can take a variable number of arguments and can generate complex code structures based on those arguments.
Example of a Recursive Macro
Let's consider a simple example of a recursive macro that generates functions. The macro will take a list of function names and create a corresponding function for each name. Here's how it works:
Macro Definition
#![allow(unused)] fn main() { macro_rules! example_macro { // Base case ($name:ident) => { fn $name() { println!("Function: {}", stringify!($name)); } }; // Recursive case ($name:ident, $($rest:ident),+) => { example_macro!($name); // Call the base case example_macro!($($rest),+); // Call recursively for the rest }; } }
In this macro definition:
- The base case handles a single identifier and generates a function that prints its name.
- The recursive case handles multiple identifiers, calling itself for the first identifier and then for the rest.
Using the Macro
To use the macro, we can define a main function that calls it with a list of function names:
fn main() { // Usage example_macro!(foo, bar, baz); foo(); bar(); baz(); }
Output
When we run this code, we will see the following output:
Function: foo
Function: bar
Function: baz
This output confirms that our macro successfully generated the functions and called them.
Conclusion
Recursive macros in Rust provide a powerful way to generate repetitive code patterns. By leveraging the macro system, developers can create cleaner and more maintainable code. This example illustrates the basic principles of defining and using a recursive macro, but the possibilities are endless.
Feel free to experiment with the macro and modify it to suit your needs. Happy coding!
Using cbindgen to Create C and C++ Bindings for Rust Code
- What is cbindgen?
- Setting Up a Project
- Writing Rust Code with FFI Exports
- Configuring Cargo.toml
- Installing cbindgen
- Configuring cbindgen
- Generating Bindings
- Using the Generated Bindings in C
- Using the Generated Bindings in C++
- Building and Linking
- Advanced cbindgen Features
- Conclusion
Rust's safety guarantees and performance make it an excellent choice for systems programming, but sometimes you need to interface with existing C or C++ codebases. This is where cbindgen comes in - a tool that automatically generates C/C++ bindings for your Rust code. In this post, I'll walk you through how to use cbindgen effectively.
What is cbindgen?
cbindgen is a tool that parses your Rust crate and generates C or C++ header files, allowing you to call Rust functions from C or C++ code. It handles the translation of Rust types to their C/C++ equivalents and manages the FFI (Foreign Function Interface) boundary.
Setting Up a Project
Let's start by setting up a simple project:
mkdir -p cbindgen_example
cd cbindgen_example
cargo init --lib
Writing Rust Code with FFI Exports
First, let's create some Rust functions that we want to expose to C/C++:
#![allow(unused)] fn main() { #[unsafe(no_mangle)] pub extern "C" fn add(left: u64, right: u64) -> u64 { left + right } #[unsafe(no_mangle)] pub extern "C" fn add_in_place(left: *mut u64, right: u64) { // check for nullity of `left` // and takes a mutable reference on it if it's non-null if let Some(left) = unsafe { left.as_mut() } { *left += right; } } }
The key elements here are:
#[no_mangle]- Prevents Rust from mangling the function name#[unsafe(no_mangle)]- Calling from other language is unsafe, so we addedunsafehereextern "C"- Specifies the C calling convention- Using C-compatible types (like raw pointers)
Handling Complex Types
Let's add a more complex example with a custom type:
#![allow(unused)] fn main() { pub struct Counter(u32); impl Counter { fn new() -> Self { Counter(0) } fn get(&self) -> u32 { self.0 } fn incr(&mut self) -> bool { if let Some(n) = self.0.checked_add(1) { self.0 = n; true } else { false } } } // C-compatible API #[unsafe(no_mangle)] pub extern "C" fn counter_new() -> *mut Counter { // Box allocates memory on the heap and Box::into_raw converts it to a raw pointer Box::into_raw(Box::new(Counter::new())) } #[unsafe(no_mangle)] pub extern "C" fn counter_incr(counter: *mut Counter) -> std::os::raw::c_int { if let Some(counter) = unsafe { counter.as_mut() } { if counter.incr() { 0 } else { -1 } } else { -2 } } #[unsafe(no_mangle)] pub extern "C" fn counter_get(counter: *const Counter) -> u32 { if let Some(counter) = unsafe { counter.as_ref() } { return counter.get(); } return 0; } #[unsafe(no_mangle)] pub extern "C" fn counter_destory(counter: *mut Counter) -> std::os::raw::c_int { if !counter.is_null() { let _ = unsafe { Box::from_raw(counter) }; // get box and drop return 0; } return -1; } }
This example demonstrates how to expose a Rust struct to C/C++ by providing C-compatible functions that operate on raw pointers to the struct.
Configuring Cargo.toml
To build your Rust code as a C-compatible library, you need to add cbindgen as a build dependency.
Run cargo add cbindgen --build to add cbindgen to dependency.
Click to see output!
cargo add cbindgen --build
Updating crates.io index
Adding cbindgen v0.28.0 to build-dependencies
Features:
+ clap
- unstable_ir
Updating crates.io index
Locking 56 packages to latest Rust 1.85.1 compatible versions
Adding anstream v0.6.18
Adding anstyle v1.0.10
Adding anstyle-parse v0.2.6
Adding anstyle-query v1.1.2
Adding anstyle-wincon v3.0.7
Adding bitflags v2.9.0
Adding cbindgen v0.28.0
Adding cfg-if v1.0.0
Adding clap v4.5.36
Adding clap_builder v4.5.36
Adding clap_lex v0.7.4
Adding colorchoice v1.0.3
Adding equivalent v1.0.2
Adding errno v0.3.11
Adding fastrand v2.3.0
Adding getrandom v0.3.2
Adding hashbrown v0.15.2
Adding heck v0.4.1
Adding indexmap v2.9.0
Adding is_terminal_polyfill v1.70.1
Adding itoa v1.0.15
Adding libc v0.2.172
Adding linux-raw-sys v0.9.4
Adding log v0.4.27
Adding memchr v2.7.4
Adding once_cell v1.21.3
Adding proc-macro2 v1.0.95
Adding quote v1.0.40
Adding r-efi v5.2.0
Adding rustix v1.0.5
Adding ryu v1.0.20
Adding serde v1.0.219
Adding serde_derive v1.0.219
Adding serde_json v1.0.140
Adding serde_spanned v0.6.8
Adding strsim v0.11.1
Adding syn v2.0.100
Adding tempfile v3.19.1
Adding toml v0.8.20
Adding toml_datetime v0.6.8
Adding toml_edit v0.22.24
Adding unicode-ident v1.0.18
Adding utf8parse v0.2.2
Adding wasi v0.14.2+wasi-0.2.4
Adding windows-sys v0.59.0
Adding windows-targets v0.52.6
Adding windows_aarch64_gnullvm v0.52.6
Adding windows_aarch64_msvc v0.52.6
Adding windows_i686_gnu v0.52.6
Adding windows_i686_gnullvm v0.52.6
Adding windows_i686_msvc v0.52.6
Adding windows_x86_64_gnu v0.52.6
Adding windows_x86_64_gnullvm v0.52.6
Adding windows_x86_64_msvc v0.52.6
Adding winnow v0.7.6
Adding wit-bindgen-rt v0.39.0
The Cargo.toml file will looks like this:
[package]
name = "cbindgen_example"
version = "0.1.0"
edition = "2024"
[lib]
crate-type = ["cdylib"]
[build-dependencies]
cbindgen = "0.28.0"
The crate-type = ["cdylib"] line tells Cargo to build a dynamic library that can be used from C.
Installing cbindgen
Add cbindgen to your development dependencies, so that you can call cbindgen manually to generate c/cpp header files:
cargo install cbindgen
Configuring cbindgen
Create a cbindgen.toml file in your project root to configure how your bindings are generated:
# Basic configuration
language = "C++" # or "C" for C bindings
# Header customization
header = "/* Copyright (c) 2023 Your Name */"
include_guard = "RUST_BINDINGS_H"
pragma_once = true
autogen_warning = "/* Warning, this file is autogenerated by cbindgen. Don't modify this manually. */"
# Code style
braces = "SameLine"
line_length = 100
tab_width = 2
documentation = true
# C++ specific options (ignored when generating C bindings)
namespace = "rust"
namespaces = []
You can also refer to https://raw.githubusercontent.com/mozilla/cbindgen/refs/heads/master/template.toml for more configuration.
Generating Bindings
Now you can generate the bindings manually by running cbindgen binary:
cbindgen --config cbindgen.toml --output bindings.h
Or, for more automation, add a build script (build.rs) to your project:
extern crate cbindgen; use std::env; fn main() { let crate_dir = env::var("CARGO_MANIFEST_DIR").unwrap(); // Generate C bindings cbindgen::Builder::new() .with_crate(&crate_dir) .with_language(cbindgen::Language::C) .generate() .expect("Unable to generate bindings") .write_to_file("bindings.h"); // Generate C++ bindings cbindgen::Builder::new() .with_crate(&crate_dir) .generate() .expect("Unable to generate bindings") .write_to_file("bindings.hpp"); }
This build script will automatically generate both C and C++ bindings whenever you build your Rust project.
Using the Generated Bindings in C
Here's how you might use your Rust functions from C:
#include <stdio.h>
#include "bindings.h"
int main() {
// Call the add function
uint64_t result = add(5, 7);
printf("5 + 7 = %llu\n", result);
// Use the add_in_place function
uint64_t value = 10;
add_in_place(&value, 5);
printf("10 + 5 = %llu\n", value);
// Use the Counter API
struct Counter *counter = counter_new();
counter_incr(counter);
counter_incr(counter);
printf("Counter value: %u\n", counter_get(counter));
counter_destory(counter);
return 0;
}
Using the Generated Bindings in C++
And here's how you might use them from C++:
#include <iostream>
#include "bindings.hpp"
int main() {
// Call the add function
uint64_t result = add(5, 10);
std::cout << "5 + 10 = " << result << std::endl;
// Use the add_in_place function
uint64_t value = 10;
add_in_place(&value, 20);
std::cout << "10 + 20 = " << value << std::endl;
// Use the Counter API
Counter *counter = counter_new();
counter_incr(counter);
counter_incr(counter);
counter_incr(counter);
std::cout << "Counter value: " << counter_get(counter) << std::endl;
counter_destory(counter);
return 0;
}
Building and Linking
To compile and link your C/C++ code with your Rust library:
- Build your Rust library:
cargo build --release
- Compile your C/C++ code and link against the Rust library:
# For C
gcc main.c -o add-c -L./target/release -lcbindgen_example
# For C++
g++ main.cpp -o add-cpp -L./target/release -lcbindgen_example
You can also use a Makefile to automate this process:
build:
cargo build
build-cpp:
g++ main.cpp -o add-cpp -L./target/debug -lcbindgen_example
build-c:
gcc main.c -o add-c -L./target/release -lcbindgen_example
run-cpp: build-cpp
./add-cpp
run-c: build-c
./add-c
Advanced cbindgen Features
Type Mapping
You can customize how Rust types are mapped to C/C++ types:
[export]
# Prefix all exported symbols
prefix = "RUST_"
[export.rename]
# Rename specific items
"RustStruct" = "CStruct"
[parse]
# Parse dependencies
parse_deps = true
# Include only specific items
include = ["my_module"]
# Exclude specific items
exclude = ["internal_module"]
Handling Opaque Types
Sometimes you want to expose a Rust type to C/C++ without exposing its internal structure. You can do this by using opaque types:
#![allow(unused)] fn main() { // In Rust #[repr(C)] pub struct OpaqueType { // Fields not visible to C/C++ private_field: i32, } #[no_mangle] pub extern "C" fn create_opaque() -> *mut OpaqueType { Box::into_raw(Box::new(OpaqueType { private_field: 42 })) } }
In the generated C header, OpaqueType will be declared as an incomplete type:
// In C
typedef struct OpaqueType OpaqueType;
OpaqueType* create_opaque(void);
Handling Callbacks
You can also pass callbacks from C/C++ to Rust:
#![allow(unused)] fn main() { // In Rust pub type Callback = extern "C" fn(i32) -> i32; #[no_mangle] pub extern "C" fn call_with_callback(callback: Callback, arg: i32) -> i32 { callback(arg) } }
// In C
typedef int (*Callback)(int);
int call_with_callback(Callback callback, int arg);
int my_callback(int x) {
return x * 2;
}
int main() {
int result = call_with_callback(my_callback, 5);
printf("Result: %d\n", result); // Prints "Result: 10"
return 0;
}
Conclusion
cbindgen is a powerful tool that makes it easy to create C and C++ bindings for your Rust code. By following the steps outlined in this post, you can seamlessly integrate Rust into your existing C/C++ projects or create new libraries that can be used from multiple languages.
Remember that when working with FFI, you're responsible for ensuring memory safety across the language boundary. Rust's safety guarantees only apply within Rust code, so be careful when passing pointers or handling resources that cross the FFI boundary.
Happy coding!
GRPC golang output path
go code output path
The protocol buffer compiler produces Go output when invoked with the go_out flag. The argument to the go_out flag is the directory where you want the compiler to write your Go output. The compiler creates a single source file for each .proto file input. The name of the output file is created by replacing the .proto extension with .pb.go.
Where in the output directory the generated .pb.go file is placed depends on the compiler flags. There are several output modes:
- If the
paths=importflag is specified, the output file is placed in a directory named after the Go package’s import path. For example, an input file protos/buzz.proto with a Go import path ofexample.com/project/protos/fizzresults in an output file atexample.com/project/protos/fizz/buzz.pb.go. This is the default output mode if a paths flag is not specified. - If the
module=$PREFIXflag is specified, the output file is placed in a directory named after the Go package’s import path, but with the specified directory prefix removed from the output filename. For example, an input fileprotos/buzz.protowith a Go import path ofexample.com/project/protos/fizzandexample.com/projectspecified as the module prefix results in an output file atprotos/fizz/buzz.pb.go. Generating any Go packages outside the module path results in an error. This mode is useful for outputting generated files directly into a Go module. - If the
paths=source_relativeflag is specified, the output file is placed in the same relative directory as the input file. For example, an input fileprotos/buzz.protoresults in an output file atprotos/buzz.pb.go
code structure
The directory tree looks like this:
❯ exa -l --tree
drwxr-xr-x - dylan 15 Feb 10:49 .
drwxr-xr-x - dylan 15 Feb 10:27 ├── cmd
drwxr-xr-x - dylan 15 Feb 10:28 │ └── greeting-server
.rw-r--r-- 30 dylan 15 Feb 10:28 │ └── main.go
.rw-r--r-- 250 dylan 15 Feb 10:49 ├── Makefile
drwxr-xr-x - dylan 15 Feb 10:49 ├── protos
.rw-r--r-- 365 dylan 15 Feb 10:48 │ └── greeting.proto
.rw-r--r-- 1.4k dylan 15 Feb 10:40 └── README.md
--go_out=paths=import
Using --go_out=paths=import to generate code into import path.
❯ protoc --go_out=. --go_opt=paths=import --go-grpc_out=. --go-grpc_opt=paths=import protos/*.proto
❯ exa -l --tree
drwxr-xr-x - dylan 15 Feb 11:21 .
drwxr-xr-x - dylan 15 Feb 10:27 ├── cmd
drwxr-xr-x - dylan 15 Feb 10:28 │ └── greeting-server
.rw-r--r-- 30 dylan 15 Feb 10:28 │ └── main.go
drwxr-xr-x - dylan 15 Feb 11:21 ├── github.com
drwxr-xr-x - dylan 15 Feb 11:21 │ └── grpc-greeting
drwxr-xr-x - dylan 15 Feb 11:21 │ └── greeting
.rw-r--r-- 7.2k dylan 15 Feb 11:21 │ ├── greeting.pb.go
.rw-r--r-- 3.7k dylan 15 Feb 11:21 │ └── greeting_grpc.pb.go
.rw-r--r-- 250 dylan 15 Feb 10:49 ├── Makefile
drwxr-xr-x - dylan 15 Feb 11:20 ├── protos
.rw-r--r-- 365 dylan 15 Feb 10:48 │ └── greeting.proto
.rw-r--r-- 1.4k dylan 15 Feb 10:40 └── README.md
You can write generated code into different places. Here we put in whatever folder.
mkdir -p whatever
protoc --go_out=whatever --go_opt=paths=import --go-grpc_out=. --go-grpc_opt=paths=import protos/*.proto
The directory tree looks like this:
drwxr-xr-x - dylan 15 Feb 11:22 .
drwxr-xr-x - dylan 15 Feb 10:27 ├── cmd
drwxr-xr-x - dylan 15 Feb 10:28 │ └── greeting-server
.rw-r--r-- 30 dylan 15 Feb 10:28 │ └── main.go
drwxr-xr-x - dylan 15 Feb 11:21 ├── github.com
drwxr-xr-x - dylan 15 Feb 11:21 │ └── grpc-greeting
drwxr-xr-x - dylan 15 Feb 11:21 │ └── greeting
.rw-r--r-- 7.2k dylan 15 Feb 11:21 │ ├── greeting.pb.go
.rw-r--r-- 3.7k dylan 15 Feb 11:22 │ └── greeting_grpc.pb.go
.rw-r--r-- 250 dylan 15 Feb 10:49 ├── Makefile
drwxr-xr-x - dylan 15 Feb 11:20 ├── protos
.rw-r--r-- 365 dylan 15 Feb 10:48 │ └── greeting.proto
.rw-r--r-- 1.4k dylan 15 Feb 10:40 ├── README.md
drwxr-xr-x - dylan 15 Feb 11:22 └── whatever
drwxr-xr-x - dylan 15 Feb 11:22 └── github.com
drwxr-xr-x - dylan 15 Feb 11:22 └── grpc-greeting
drwxr-xr-x - dylan 15 Feb 11:22 └── greeting
.rw-r--r-- 7.2k dylan 15 Feb 11:22 └── greeting.pb.go
--go_out=module=$PREFIX
We can put generated go code and grpc code into path, with specific directory prefix removed. Here we remove github.com directory and use grpc-greeting as the root path.
protoc --go_out=. --go_opt=module=github.com --go-grpc_out=. --go-grpc_opt=paths=import protos/*.proto
The directory tree looks like this:
drwxr-xr-x - dylan 15 Feb 11:31 .
drwxr-xr-x - dylan 15 Feb 10:27 ├── cmd
drwxr-xr-x - dylan 15 Feb 10:28 │ └── greeting-server
.rw-r--r-- 30 dylan 15 Feb 10:28 │ └── main.go
drwxr-xr-x - dylan 15 Feb 11:31 ├── grpc-greeting
drwxr-xr-x - dylan 15 Feb 11:31 │ └── greeting
.rw-r--r-- 7.2k dylan 15 Feb 11:31 │ ├── greeting.pb.go
.rw-r--r-- 3.7k dylan 15 Feb 11:31 │ └── greeting_grpc.pb.go
.rw-r--r-- 250 dylan 15 Feb 10:49 ├── Makefile
drwxr-xr-x - dylan 15 Feb 11:20 ├── protos
.rw-r--r-- 365 dylan 15 Feb 10:48 │ └── greeting.proto
.rw-r--r-- 1.4k dylan 15 Feb 10:40 └── README.md
We can also put generated go code and grpc code into different path.
protoc --go_out=. --go_opt=module=github.com --go-grpc_out=. --go-grpc_opt=paths=import protos/*.proto
The directory tree looks like this:
❯ exa -l --tree
drwxr-xr-x - dylan 15 Feb 11:27 .
drwxr-xr-x - dylan 15 Feb 10:27 ├── cmd
drwxr-xr-x - dylan 15 Feb 10:28 │ └── greeting-server
.rw-r--r-- 30 dylan 15 Feb 10:28 │ └── main.go
drwxr-xr-x - dylan 15 Feb 11:27 ├── github.com
drwxr-xr-x - dylan 15 Feb 11:27 │ └── grpc-greeting
drwxr-xr-x - dylan 15 Feb 11:27 │ └── greeting
.rw-r--r-- 3.7k dylan 15 Feb 11:27 │ └── greeting_grpc.pb.go
drwxr-xr-x - dylan 15 Feb 11:27 ├── grpc-greeting
drwxr-xr-x - dylan 15 Feb 11:27 │ └── greeting
.rw-r--r-- 7.2k dylan 15 Feb 11:27 │ └── greeting.pb.go
.rw-r--r-- 250 dylan 15 Feb 10:49 ├── Makefile
drwxr-xr-x - dylan 15 Feb 11:20 ├── protos
.rw-r--r-- 365 dylan 15 Feb 10:48 │ └── greeting.proto
.rw-r--r-- 1.4k dylan 15 Feb 10:40 └── README.md
--go_out=paths=source_relative
Using --go_out=paths=source_relative to generate code into the same relative directory as the input path.
protoc --go_out=. --go_opt=paths=source_relative --go-grpc_out=. --go-grpc_opt=paths=source_relative protos/*.proto
The directory tree looks like this:
❯ exa -l --tree
drwxr-xr-x - dylan 15 Feb 10:49 .
drwxr-xr-x - dylan 15 Feb 10:27 ├── cmd
drwxr-xr-x - dylan 15 Feb 10:28 │ └── greeting-server
.rw-r--r-- 30 dylan 15 Feb 10:28 │ └── main.go
.rw-r--r-- 250 dylan 15 Feb 10:49 ├── Makefile
drwxr-xr-x - dylan 15 Feb 11:19 ├── protos
.rw-r--r-- 7.2k dylan 15 Feb 11:19 │ ├── greeting.pb.go
.rw-r--r-- 365 dylan 15 Feb 10:48 │ ├── greeting.proto
.rw-r--r-- 3.7k dylan 15 Feb 11:19 │ └── greeting_grpc.pb.go
.rw-r--r-- 1.4k dylan 15 Feb 10:40 └── README.md
Go mod gitlab subgroup module
- Intro
- Create go mod in gitlab subgroup
- Test use go mod in gitlab subgroup
- Config ~/.netrc
- Add go module in gitlab subgroup
- Test in main.go
Intro
In this article, we will learn how to use go mod to get private gitlab subgroup module.
Create go mod in gitlab subgroup
First, let's create subgroup with name group1 in aoaojiaoaoaojiao gitlab group.
Next, we will create a new project named math under subgroup group1 in gitlab.
After that, we initialize the project using go mod init gitlab.com/aoaojiaoaoaojiao/group1/math in the math project.
Now, here is the go.mod file:
module gitlab.com/aoaojiaoaoaojiao/group1/math
go 1.20
We add a Add function in add.go:
add.go:
package math
func Add(a int, b int) int {
return a + b
}
Test use go mod in gitlab subgroup
Create a golang project:
mkdir -p test-go-module-in-gitlab-subgroup
cd test-go-module-in-gitlab-subgroup
go mod init test
Config ~/.netrc
Before you can pull dependency using go get, you need to add configure to ~/.netrc:
machine gitlab.com login <gitlab login email address, i.e myname@gmail.com> password <gitlab private token>
Add go module in gitlab subgroup
Then add math as dependency:
go get gitlab.com/aoaojiaoaoaojiao/group1/math
You expected everything goes well, but you didn't. Error occurred.
gitlab.com/aoaojiaoaoaojiao/group1/math@v0.0.0-20230530092926-88bf01cac6da: verifying module: gitlab.com/aoaojiaoaoaojiao/group1/math@v0.0.0-20230530092926-88bf01cac6da: reading https://goproxy.io/sumdb/sum.golang.org/lookup/gitlab.com/aoaojiaoaoaojiao/group1/math@v0.0.0-20230530092926-88bf01cac6da: 404 Not Found
server response:
not found: gitlab.com/aoaojiaoaoaojiao/group1/math@v0.0.0-20230530092926-88bf01cac6da: invalid version: git ls-remote -q origin in /tmp/gopath/pkg/mod/cache/vcs/b401f5b06f1a57210edcb631d77909880fab25833fcdeab7b9341e5d4617599b: exit status 128:
fatal: could not read Username for 'https://gitlab.com': terminal prompts disabled
Confirm the import path was entered correctly.
If this is a private repository, see https://golang.org/doc/faq#git_https for additional information.
You need to tell to by using export GOPRIVATE='gitlab.com' or go env -w GOPRIVATE=gitlab.com:
export GOPRIVATE='gitlab.com'
go get gitlab.com/aoaojiaoaoaojiao/group1/math
Why this happens is that go get tries to discover the modules at a given path in order to find the requested Go module repository. Only after the repository is found, the tools will do git clone or git checkout and the SSH keys will be used for authentication. The issue comes down to the fact that private Gitlab subgroups cannot be listed/viewed without a Gitlab Access Token.
Output:
go: added gitlab.com/aoaojiaoaoaojiao/group1/math v0.0.0-20230530092926-88bf01cac6da
Test in main.go
Write code in main.go to call Add function in math module.
main.go
package main
import (
"fmt"
"gitlab.com/aoaojiaoaoaojiao/group1/math"
)
func main() {
res := math.Add(1, 2)
fmt.Printf("1 + 2 = %d\n", res)
}
Output:
1 + 2 = 3
Write password encryption package using ChatGPT
The full chat history with chatgpt is here:
https://docs.google.com/document/d/e/2PACX-1vSiMi4cbOwsHbBChlIum8yrq80h6K1rYRll2v0pYlzIwKM7ugTiMN8tnUkSItCFeSWrISYsjsDmDfYq/pub
Title: Upgrading Material-UI from v4 to v5: A Comprehensive Guide
- Introduction:
- Step 1: Upgrade React to 17.0.0:
- Step 2: Update MUI packages and peer dependencies:
- Step 3: Run codemods:
- Step 4: Fix broken code:
- Step 5: Replace all imports:
- Step 6: Test and finalize:
- References:
Introduction:
Material-UI is a popular React component library that provides a set of pre-built UI components for building modern and responsive web applications. With the release of Material-UI v5, there have been significant changes and improvements, making it essential for developers to upgrade from v4 to v5. In this blog post, we will walk you through the step-by-step process of upgrading Material-UI to its latest version.
Step 1: Upgrade React to 17.0.0:
To start the upgrade process, it is necessary to update React to version 17.0.0 or above. This can be done using the following command:
yarn upgrade @material-ui/core@^4.11.2 react@^17.0.0
Step 2: Update MUI packages and peer dependencies:
Next, we need to update the Material-UI packages and their peer dependencies. Run the following commands to install the required packages:
yarn add @mui/material @mui/styles
yarn add @mui/lab
yarn add @mui/icons-material
yarn add @emotion/react @emotion/styled
Step 3: Run codemods:
Material-UI provides codemods that automatically adjust your code to account for breaking changes in v5. These codemods help in migrating your codebase efficiently. Run the following command to apply the preset-safe codemod:
npx @mui/codemod v5.0.0/preset-safe <path>
Additionally, you can run specific codemods for individual components or pages if needed. For example:
npx @mui/codemod v5.0.0/preset-safe components
npx @mui/codemod v5.0.0/preset-safe pages
Step 4: Fix broken code:
After running the codemods, it's important to review your codebase for any broken code. One common issue is the usage of the theme.spacing() function, which has changed in v5. Replace instances of theme.spacing(2) with 2, theme.spacing(4) with 4, and so on, to fix this issue.
Step 5: Replace all imports:
With the release of v5, the package names have changed from @material-ui/* to @mui/*. To ensure compatibility with the latest version, replace all imports accordingly. Here are some examples:
yarn remove @material-ui/core
yarn remove @material-ui/icons
yarn remove @material-ui/lab
yarn remove @material-ui/pickers
yarn remove @mui/x-data-grid
yarn add @mui/x-data-grid
Step 6: Test and finalize:
After completing the above steps, thoroughly test your application to ensure that it runs without any errors. Make any necessary adjustments or fixes as required. Once you are confident that your application is functioning correctly, commit the changes and finalize the upgrade process.
Conclusion: Upgrading Material-UI from v4 to v5 is an important step to take advantage of the latest features, bug fixes, and improvements. By following the steps outlined in this guide, you can smoothly upgrade your Material-UI-based application to the latest version. Remember to thoroughly test your application after the upgrade to ensure everything is functioning as expected. Happy coding with Material-UI v5!
References:
- Material-UI Migration Guide: Migrating to v5: getting started
Register gitlab runner on Amazon Linux 2
- Intro
- Start AWS EC2 Instance
- Install gitlab runner on Amazon Linux 2
- Register gitlab runner
- Set GITLAB_PORT to 443
- Write .gitlab-ci.yml for go project
- Test the runner
Intro
In this article, we will show you how to register gitlab runner on Amazon Linux 2 and setup gitlab ci for go project.
Start AWS EC2 Instance
You can create aws ec2 instance either in aws console or using aws cli.
Notice you should enable public ip address if your aws ec2 instance is in public subnet of you VPC, otherwise you will not be able to access the internet!
Install gitlab runner on Amazon Linux 2
Next, we'll install gitlab runner on Amazon Linux 2. Run the following bash script:
# install on amazon linux 2
# refs: https://github.com/beda-software/FAQ/blob/master/aws-ec2-gitlab-runner.md
curl -L "https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.rpm.sh" | sudo bash
sudo -E yum install gitlab-runner
sudo amazon-linux-extras install docker
sudo service docker start
sudo usermod -a -G docker ec2-user
sudo systemctl enable docker.service
sudo systemctl enable containerd.service
sudo usermod -a -G docker ec2-user
sudo yum install -y git
Register gitlab runner
You can register gitlab runner by using gitlab-ci-multi-runner command:
# register runner
# sudo gitlab-ci-multi-runner register -n --url GITLAB_URL --registration-token "TOKEN" --executor docker --description "Name of docker runner" --docker-image "docker:latest" --docker-privileged
Replace GITLAB_URL and TOKEN with your self-hosted gitlab url and gitlab token. You can go to https://gitlab.mycompany.com/admin/runners and click Register an instance runner button, and you will see the TOKEN in the popup.
# register runner in gitlab ccc
sudo gitlab-ci-multi-runner register -n --url https://gitlab.mycompany.com/ --registration-token "A____TOKEN_____A" --executor docker --description "Name of docker runner" --docker-image "docker:latest" --docker-privileged
Output:
Runtime platform arch=amd64 os=linux pid=8095 revision=865283c5 version=16.1.0
Running in system-mode.
WARNING: Support for registration tokens and runner parameters in the 'register' command has been deprecated in GitLab Runner 15.6 and will be replaced with support for authentication tokens. For more information, see https://gitlab.com/gitlab-org/gitlab/-/issues/380872
Registering runner... succeeded runner=paaaaaaa
Runner registered successfully. Feel free to start it, but if it's running already the config should be automatically reloaded!
Configuration (with the authentication token) was saved in "/etc/gitlab-runner/config.toml"
You will see a runner with name paaaaaaa is registered successfully.
And you can also config the runner in /etc/gitlab-runner/config.toml.
You can go to runners page in gitlab Admin and check if the runner is registered successfully.
Set GITLAB_PORT to 443
As the runner is registered successfully, you may encounter an error like this:
gitlab-runner version 14.10.1 fails to clone a repo configured with a https repo URL, stating HTTP Basic: Access denied.
As we deploy gitlab using https://github.com/sameersbn/docker-gitlab, you may need to set GITLAB_PORT to 443 based on your configuration for load balancer above gitlab service, or add clone_url to the runner config file /etc/gitlab-runner/config.toml. Also, don't forget to restart docker servcie sudo service docker restart.
concurrent = 1
check_interval = 0
shutdown_timeout = 0
[session_server]
session_timeout = 1800
[[runners]]
name = "Name of docker runner"
url = "https://gitlab.mycompany.com/"
clone_url = "https://gitlab.mycompany.com/"
id = 1
token = "s_____________n"
token_obtained_at = 2023-07-22T01:20:41Z
token_expires_at = 0001-01-01T00:00:00Z
executor = "docker"
[runners.cache]
MaxUploadedArchiveSize = 0
[runners.docker]
tls_verify = false
image = "docker:latest"
privileged = true
disable_entrypoint_overwrite = false
oom_kill_disable = false
disable_cache = false
volumes = ["/cache"]
shm_size = 0
Write .gitlab-ci.yml for go project
For go project, you can write a gitlab ci file and test the runner.
Here is a simple gitlab ci file .gitlab-ci.yml for go project:
# You can copy and paste this template into a new `.gitlab-ci.yml` file.
# You should not add this template to an existing `.gitlab-ci.yml` file by using the `include:` keyword.
#
# To contribute improvements to CI/CD templates, please follow the Development guide at:
# https://docs.gitlab.com/ee/development/cicd/templates.html
# This specific template is located at:
# https://gitlab.com/gitlab-org/gitlab/-/blob/master/lib/gitlab/ci/templates/Go.gitlab-ci.yml
image: golang:latest
stages:
- test
- build
- deploy
format:
stage: test
script:
- go fmt $(go list ./... | grep -v /vendor/)
- go vet $(go list ./... | grep -v /vendor/)
- go test -race $(go list ./... | grep -v /vendor/)
compile:
stage: build
script:
- mkdir -p mybinaries
- go build -o mybinaries ./...
artifacts:
paths:
- mybinaries
deploy:
stage: deploy
script: echo "Define your deployment script!"
environment: production
Test the runner
You can trigger ci either by committing on main branch or clicking Run Pipeline in your project's pipeline page, i.e https://gitlab.mycompany.com/myname/go-ci-test/-/pipelines
If the pipeline is passed, your gitlab runner is runner successfully.
Install gitlab runner on ubuntu
- Intro
- Start gitlab-runner in container
- Register gitlab runner in non-interactive mode
- stop gitlab-runner
- Refs
Intro
I've been using GitLab CI/CD for a while now, and I have to say that it's an amazing tool for code management and automating builds and deployments.
In this blog post, I'll share my experience installing and using GitLab Runner on Ubuntu with GPU instance.
Check GPU info on instance
First, check the GPU info on the instance:
(base) smolai@smolai-Z790-UD-AX:~$ nvidia-smi
Mon Sep 18 15:57:06 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.116.04 Driver Version: 525.116.04 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | Off |
| 0% 35C P8 5W / 450W | 3754MiB / 24564MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 13290 C python 3752MiB |
+-----------------------------------------------------------------------------+
Install gitlab runner
Next, we can install gitlab runner using the following command:
wget -qO - https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.deb.sh | sudo bash
sudo apt install -y gitlab-runner
Register gitlab runner
After installation, we can register gitlab runner using the following command:
# register gitlab runner
sudo gitlab-runner register \
--non-interactive \
--url "https://gitlab.planetsmol.com" \
--registration-token "glrt-ooooooiiiiiiiiii" \
--description "docker-runner" \
--executor "docker" \
--docker-image ubuntu:latest
Here is the output of the command:
Runtime platform arch=amd64 os=linux pid=74044 revision=f5dfa4d1 version=16.3.1
Running in system-mode.
Verifying runner... is valid runner=eooovvviii
Runner registered successfully. Feel free to start it, but if it's running already the config should be automatically reloaded!
Configuration (with the authentication token) was saved in "/etc/gitlab-runner/config.toml"
root@smolai:/tmp# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.gitlab.com/gitlab-org/gitlab-runner/gitlab-runner-helper x86_64-f5dfa4d1 4af7e8dd8eb7 18 seconds ago 64.1MB
meet latest 7d62cb955a7f 5 weeks ago 915MB
busybox latest a416a98b71e2 2 months ago 4.26MB
Uninstall GitLab Runner
If you want to completely remove GitLab Runner, run the following command:
# If you want to completely remove GitLab Runner, run the following command:
sudo apt purge --autoremove -y gitlab-runner
# Remove GPG key and repository:
sudo apt-key del 513111FF
sudo rm -rf /etc/apt/sources.list.d/runner_gitlab-runner.list
# Remove GitLab Runner user:
sudo deluser --remove-home gitlab-runner
#You can also remove GitLab Runner configuration:
sudo rm -rf /etc/gitlab-runner
Start gitlab-runner in container
You have two options to start gitlab-runner in container.
To store gitlab-runner config in docker volume, you can either use docker volume or use local system volume.
After install gitlab-runner, you can start gitlab-runner in container.
You have to register gitlab runner after start gitlab-runner in container.
As the docs said:
Runner registration is the process that links the runner with one or more GitLab instances. You must register the runner so that it can pick up jobs from the GitLab instance.
Gitlab runner token
You have to obtain gitlab runner token from gitlab to register the runner.
Here is how to obtain the token from gitlab:
- Login to gitlab
- Click on the "Runners" button
- Click on the "Tokens" button
- Click on the "Create token" button
- Copy the token
Notice, the gitlab runner authentication tokens have the prefix glrt-.
Use local volume
Let's see how to use local system volume mounts to start the Runner container.
# Create the directory to mount the docker volume
mkdir -p /srv/gitlab-runner/config
# Start the GitLab Runner container
docker run -d --name gitlab-runner --restart always \
-v /srv/gitlab-runner/config:/etc/gitlab-runner \
-v /var/run/docker.sock:/var/run/docker.sock \
gitlab/gitlab-runner:latest
Now the runner is started, let's see how to register it.
docker run --rm -it -v /srv/gitlab-runner/config:/etc/gitlab-runner gitlab/gitlab-runner register
docker volume
If you want to use docker volume to start the Runner container, you can use the following command:
# Create the Docker volume
docker volume create gitlab-runner-config
# Start the GitLab Runner container using the volume we just created
docker run -d --name gitlab-runner --restart always \
-v /var/run/docker.sock:/var/run/docker.sock \
-v gitlab-runner-config:/etc/gitlab-runner \
gitlab/gitlab-runner:latest
Register gitlab runner in non-interactive mode
You can use non-interactive mode to register the runner, refer to https://docs.gitlab.com/runner/commands/index.html#non-interactive-registration for more details.
If you want to register the runner on linux, you can use the following command:
sudo gitlab-runner register \
--non-interactive \
--url "https://gitlab.com/" \
--token "$RUNNER_TOKEN" \
--executor "docker" \
--docker-image alpine:latest \
--description "docker-runner"
If you want to register the runner through docker, you can use the following command:
docker run --rm -v /srv/gitlab-runner/config:/etc/gitlab-runner gitlab/gitlab-runner register \
--non-interactive \
--executor "docker" \
--docker-image alpine:latest \
--url "https://gitlab.com/" \
--token "$RUNNER_TOKEN" \
--description "docker-runner"
stop gitlab-runner
To stop the gitlab-runner container, you can use the following command:
docker stop gitlab-runner && docker rm gitlab-runner
Refs
Install https://lindevs.com/install-gitlab-runner-on-ubuntu
Install gitlab runner https://docs.gitlab.com/runner/install/docker.html
Another install doc https://docs.gitlab.com/runner/install/linux-repository.html
Register runner https://docs.gitlab.com/runner/register/index.html#docker
Build multi-arch docker image using buildx
- Setup simple golang project using go mod
- .gitlab-ci.yml
- Setup CI variable to authenticate gitlab to aws ecr
- Run ci
- Inspect the image
Setup simple golang project using go mod
Iniit golang project using go mod:
go mod init gitlab.com/aoaojiaoaoaojiao/go-multi-arch
Write main.go:
package main
import "fmt"
func main() {
fmt.Println("vim-go")
}
.gitlab-ci.yml
# You can override the included template(s) by including variable overrides
# SAST customization: https://docs.gitlab.com/ee/user/application_security/sast/#customizing-the-sast-settings
# Secret Detection customization: https://docs.gitlab.com/ee/user/application_security/secret_detection/#customizing-settings
# Dependency Scanning customization: https://docs.gitlab.com/ee/user/application_security/dependency_scanning/#customizing-the-dependency-scanning-settings Container Scanning customization: https://docs.gitlab.com/ee/user/application_security/container_scanning/#customizing-the-container-scanning-settings
# Note that environment variables can be set in several places
# See https://docs.gitlab.com/ee/ci/variables/#cicd-variable-precedence
# stages:
# - test
# sast:
# stage: test
# include:
# - template: Security/SAST.gitlab-ci.yml
image: docker:20.10.8
stages:
- build-push
variables:
DOCKER_DRIVER: overlay2
BUILDX_VERSION: "v0.6.1"
BUILDX_ARCH: "linux-amd64"
AWS_DEFAULT_REGION: us-east-1
AWS_ECR_NAME: 444333555686.dkr.ecr.us-east-1.amazonaws.com/orders/orders
AWS_ACCOUNT_ID: 444333555686
#DOCKER_IMAGE_NAME: your-docker-image-name
#DOCKER_USERNAME: AWS
GIT_COMMIT_SHA: ${CI_COMMIT_SHORT_SHA}
build and push:
stage:
build-push
#image: docker:dind
image: docker:20.10.8-dind
services:
- docker:dind
before_script:
- apk update
- apk add --no-cache curl python3 py3-pip git
- pip3 install awscli
- wget -O /usr/bin/docker-buildx https://github.com/docker/buildx/releases/download/${BUILDX_VERSION}/buildx-${BUILDX_VERSION}.${BUILDX_ARCH}
- chmod +x /usr/bin/docker-buildx
- aws ecr get-login-password --region $AWS_DEFAULT_REGION | docker login --username AWS --password-stdin $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com
script:
#- docker buildx create --use
#- docker buildx build --platform linux/amd64,linux/arm64 -t $AWS_ECR_NAME:$GIT_COMMIT_SHA --push .
- docker-buildx create --use
- docker-buildx build --platform linux/amd64,linux/arm64 -t $AWS_ECR_NAME:$GIT_COMMIT_SHA --push .
Setup CI variable to authenticate gitlab to aws ecr
In your GitLab project, go to Settings > CI/CD. Set the following CI/CD variables:
Environment variable name Value
AWS_ACCESS_KEY_IDYour Access key ID.AWS_SECRET_ACCESS_KEYYour secret access key.AWS_DEFAULT_REGIONYour region code. You might want to confirm that the AWS service you intend to use is available in the chosen region.
Variables are protected by default. To use GitLab CI/CD with branches or tags that are not protected, clear the Protect variable checkbox.
Run ci
Any time you push code into the repo, gitlab runn run ci pipieline and images with two platforms will be push to AWS ECR, based on the arguments of docker-buildx build: --platform linux/amd64,linux/arm64
Inspect the image
Inspect the image:
docker manifest inspect 444333555686.dkr.ecr.us-east-1.amazonaws.com/orders/orders:71db070c
Output:
{
"schemaVersion": 2,
"mediaType": "application/vnd.docker.distribution.manifest.list.v2+json",
"manifests": [
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 1682,
"digest": "sha256:65666a6rbcccc7er7we7w7238238d7ds7fd7sdfs7fs7ds7s7s7",
"platform": {
"architecture": "amd64",
"os": "linux"
}
},
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 1681,
"digest": "sha256:i23iwejfdsadfasjdsapfsdaphfdasusdahudshisadhoasdodshd",
"platform": {
"architecture": "arm64",
"os": "linux"
}
}
]
}
Start gitlab using terraform
如何在 AWS 中快速部署一台 GitLab 服务?利用 terraform,我们可以自由调配云服务的资源,并快速将 GitLab 部署到 AWS 中。
aws
aws provider
在我们使用 terraform 创建云服务器时,我们需要指定 provider。
首先,我们定义 aws provider。
aws provider 是 terraform 的一个特殊的资源类型,它提供了一个简单的 API,用于访问 AWS 中的服务。
以下配置是 aws provider 的配置:
provider "aws" {
region = "cn-northwest-1"
}
我们指定了 AWS 的 region 为 cn-northwest-1,这个 region 就是我们的云服务器所在的地区。
vpc
运行 GitLab 的 EC2 放在哪里呢?一般来讲,服务器需要一个 VPC,这个 VPC 就是我们的云服务器所在的网络,而我们的 EC2 instance 就是在这个 VPC 中的一个虚拟机。
一般我们会利用现有的 vpc 而不是新建 vpc,从 AWS console 中查询以下 vpc 的 id,我们把它放到名为 vpc 的 variable 中。
EN: As we have already have a vpc, we can use it to deploy our application. Here we use variable to define the vpc id.
variable "vpc" {
type = string
default = "vpc-0f0f0f0f0f0f0f0f"
description = "The VPC ID of "
}
ec2 instance
在确定了 VPC 的 id 之后,我们就可以创建 EC2 instance 了。
我们使用 aws_instance 资源来创建 EC2 instance,并且指定了一个名为 gitlab 的实例。
此外,我们还指定了一个实例的类型,这个类型是 m5a.large,这个类型是 AWS 中的一个预定义的类型,我们可以在 AWS console 中查询到。
ami 为版本为 Ubuntu 20.04 的镜像,key_name 为登录 EC2 的 key,root_block_device 为系统盘,我们此时分配了 40G 的磁盘空间,subnet_id 为 vpc 下的一个子网,它也是预先就创建好的。
vpc_security_group_ids 为我们创建 EC2 所需的安全组,下面我们会讲它开启了哪些规则。
EN: We can use the ec2 resource to deploy our application. We use aws_instance resource and specify the vpc id, subnet id, instance type(m5a.large ), key_name(gitlab), Ubuntu 20.04 server(ami-ffff111db56e65f8d), 40GiB root block size volume.
resource "aws_instance" "gitlab" {
# Ubuntu Server 20.04 LTS (HVM), SSD Volume Type - ami-ffff111db56e65f8d (64-bit x86) / ami-0429c857c8db3027a (64-bit Arm)
ami = "ami-ffff111db56e65f8d"
instance_type = "m5a.large"
key_name = "gitlab"
root_block_device {
volume_size = "40"
volume_type = "gp3"
}
# (subnet-public1-cn-north-1a)
subnet_id = "subnet-2222333344445555"
vpc_security_group_ids = ["${aws_security_group.gitlab.id}"]
# associate_public_ip_address = true
tags = {
Name = "gitlab"
}
}
在 EC2 创建好之后,我们可以这样登录:
EN: After provisioning, you can access the GitLab instance.
ssh -i ~/.ssh/gitlab.pem <public_ip>
security group
EC2 实例需要一个安全组,用来控制它的 ingress 规则和 egress 规则。可以把 security group 看成是防火墙。
通过配置文件可知,我们允许 ssh 登录 EC2,允许访问 GitLab http 的端口 80 和 https 的端口 443。
对于出口的规则,我们不做任何限制,可以访问任何地方。
resource "aws_security_group" "gitlab" {
description = "Security group for gitlab"
vpc_id = var.vpc
egress {
cidr_blocks = ["0.0.0.0/0"]
description = "Allow all outbound traffic"
from_port = 0
protocol = "-1"
self = false
to_port = 0
}
ingress {
cidr_blocks = ["0.0.0.0/0"]
description = "ssh"
from_port = 22
protocol = "tcp"
self = false
to_port = 22
}
ingress {
cidr_blocks = ["0.0.0.0/0"]
description = "allow public access http"
from_port = 80
protocol = "tcp"
self = false
to_port = 80
}
ingress {
cidr_blocks = ["0.0.0.0/0"]
description = "allow public access https"
from_port = 443
protocol = "tcp"
self = false
to_port = 443
}
name = "gitlab"
revoke_rules_on_delete = false
tags = {
"Name" = "gitlab"
}
tags_all = {
"Name" = "gitlab"
}
timeouts {}
}
ebs volume
为了存储 git repository,我们可以利用 aws_ebs_volume 给 EC2 实例分配一个 EBS 磁盘,并且指定它的大小为 40GiB,再通过 aws_volume_attachment 将 EBS 磁盘与 EC2 实例进行绑定。
resource "aws_ebs_volume" "gitlab" {
availability_zone = "cn-north-1a"
size = 40
type = "gp3"
tags = {
Name = "gitlab"
}
}
resource "aws_volume_attachment" "ebs_attachment_gitlab" {
device_name = "/dev/sdh"
volume_id = aws_ebs_volume.gitlab.id
instance_id = aws_instance.gitlab.id
}
好了,就这样就差不都了,我们来执行一下 terraform plan 命令,看看有没有错误。
下面是添加了 aws_ebs_volume 和 aws_volume_attachment 之后执行 terraform plan 的结果:
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# aws_ebs_volume.gitlab will be created
+ resource "aws_ebs_volume" "gitlab" {
+ arn = (known after apply)
+ availability_zone = "cn-north-1a"
+ encrypted = (known after apply)
+ id = (known after apply)
+ iops = (known after apply)
+ kms_key_id = (known after apply)
+ size = 40
+ snapshot_id = (known after apply)
+ tags = {
+ "Name" = "gitlab"
}
+ tags_all = {
+ "Name" = "gitlab"
}
+ throughput = (known after apply)
+ type = "gp3"
}
# aws_instance.gitlab will be created
+ resource "aws_instance" "gitlab" {
+ ami = "ami-ffff111db56e65f8d"
+ arn = (known after apply)
+ associate_public_ip_address = (known after apply)
+ availability_zone = (known after apply)
+ cpu_core_count = (known after apply)
+ cpu_threads_per_core = (known after apply)
+ disable_api_termination = (known after apply)
+ ebs_optimized = (known after apply)
+ get_password_data = false
+ host_id = (known after apply)
+ id = (known after apply)
+ instance_initiated_shutdown_behavior = (known after apply)
+ instance_state = (known after apply)
+ instance_type = "m5a.large"
+ ipv6_address_count = (known after apply)
+ ipv6_addresses = (known after apply)
+ key_name = "gitlab"
+ monitoring = (known after apply)
+ outpost_arn = (known after apply)
+ password_data = (known after apply)
+ placement_group = (known after apply)
+ placement_partition_number = (known after apply)
+ primary_network_interface_id = (known after apply)
+ private_dns = (known after apply)
+ private_ip = (known after apply)
+ public_dns = (known after apply)
+ public_ip = (known after apply)
+ secondary_private_ips = (known after apply)
+ security_groups = (known after apply)
+ source_dest_check = true
+ subnet_id = "subnet-88ff88ff88ff"
+ tags = {
+ "Name" = "gitlab"
}
+ tags_all = {
+ "Name" = "gitlab"
}
+ tenancy = (known after apply)
+ user_data = (known after apply)
+ user_data_base64 = (known after apply)
+ user_data_replace_on_change = false
+ vpc_security_group_ids = (known after apply)
+ capacity_reservation_specification {
+ capacity_reservation_preference = (known after apply)
+ capacity_reservation_target {
+ capacity_reservation_id = (known after apply)
}
}
+ ebs_block_device {
+ delete_on_termination = (known after apply)
+ device_name = (known after apply)
+ encrypted = (known after apply)
+ iops = (known after apply)
+ kms_key_id = (known after apply)
+ snapshot_id = (known after apply)
+ tags = (known after apply)
+ throughput = (known after apply)
+ volume_id = (known after apply)
+ volume_size = (known after apply)
+ volume_type = (known after apply)
}
+ enclave_options {
+ enabled = (known after apply)
}
+ ephemeral_block_device {
+ device_name = (known after apply)
+ no_device = (known after apply)
+ virtual_name = (known after apply)
}
+ metadata_options {
+ http_endpoint = (known after apply)
+ http_put_response_hop_limit = (known after apply)
+ http_tokens = (known after apply)
+ instance_metadata_tags = (known after apply)
}
+ network_interface {
+ delete_on_termination = (known after apply)
+ device_index = (known after apply)
+ network_interface_id = (known after apply)
}
+ root_block_device {
+ delete_on_termination = true
+ device_name = (known after apply)
+ encrypted = (known after apply)
+ iops = (known after apply)
+ kms_key_id = (known after apply)
+ throughput = (known after apply)
+ volume_id = (known after apply)
+ volume_size = 60
+ volume_type = "standard"
}
}
# aws_security_group.gitlab will be created
+ resource "aws_security_group" "gitlab" {
+ arn = (known after apply)
+ description = "Security group for gitlab"
+ egress = [
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ description = "Allow all outbound traffic"
+ from_port = 0
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "-1"
+ security_groups = []
+ self = false
+ to_port = 0
},
]
+ id = (known after apply)
+ ingress = [
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ description = "allow public access http"
+ from_port = 80
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "tcp"
+ security_groups = []
+ self = false
+ to_port = 80
},
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ description = "allow public access https"
+ from_port = 443
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "tcp"
+ security_groups = []
+ self = false
+ to_port = 443
},
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ description = "test"
+ from_port = 22
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "tcp"
+ security_groups = []
+ self = false
+ to_port = 22
},
+ {
+ cidr_blocks = [
+ "10.0.0.0/16",
]
+ description = "allow ssh"
+ from_port = 22
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "tcp"
+ security_groups = []
+ self = false
+ to_port = 22
},
]
+ name = "gitlab"
+ name_prefix = (known after apply)
+ owner_id = (known after apply)
+ revoke_rules_on_delete = false
+ tags = {
+ "Name" = "gitlab"
}
+ tags_all = {
+ "Name" = "gitlab"
}
+ vpc_id = "vpc-0afafafafaf"
+ timeouts {}
}
# aws_volume_attachment.ebs_attachment_gitlab will be created
+ resource "aws_volume_attachment" "ebs_attachment_gitlab" {
+ device_name = "/dev/sdh"
+ id = (known after apply)
+ instance_id = (known after apply)
+ volume_id = (known after apply)
}
Plan: 4 to add, 0 to change, 0 to destroy.
Note: You didn't use the -out option to save this plan, so Terraform can't guarantee to take exactly these actions if you run "terraform apply" now.
以上显示,terraform 会创建以下 4 种资源:
aws_instance.gitlabaws_volume.gitlabaws_volume_attachment.ebs_attachment_gitlabaws_security_group.gitlab
下面执行 terraform apply 命令,4 个资源都会被创建,并且资源的属性都会被设置为预期的值。
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# aws_ebs_volume.gitlab will be created
+ resource "aws_ebs_volume" "gitlab" {
+ arn = (known after apply)
+ availability_zone = "cn-north-1a"
+ encrypted = (known after apply)
+ id = (known after apply)
+ iops = (known after apply)
+ kms_key_id = (known after apply)
+ size = 40
+ snapshot_id = (known after apply)
+ tags = {
+ "Name" = "gitlab"
}
+ tags_all = {
+ "Name" = "gitlab"
}
+ throughput = (known after apply)
+ type = "gp3"
}
# aws_instance.gitlab will be created
+ resource "aws_instance" "gitlab" {
+ ami = "ami-ffff111db56e65f8d"
+ arn = (known after apply)
+ associate_public_ip_address = (known after apply)
+ availability_zone = (known after apply)
+ cpu_core_count = (known after apply)
+ cpu_threads_per_core = (known after apply)
+ disable_api_termination = (known after apply)
+ ebs_optimized = (known after apply)
+ get_password_data = false
+ host_id = (known after apply)
+ id = (known after apply)
+ instance_initiated_shutdown_behavior = (known after apply)
+ instance_state = (known after apply)
+ instance_type = "m5a.large"
+ ipv6_address_count = (known after apply)
+ ipv6_addresses = (known after apply)
+ key_name = "gitlab"
+ monitoring = (known after apply)
+ outpost_arn = (known after apply)
+ password_data = (known after apply)
+ placement_group = (known after apply)
+ placement_partition_number = (known after apply)
+ primary_network_interface_id = (known after apply)
+ private_dns = (known after apply)
+ private_ip = (known after apply)
+ public_dns = (known after apply)
+ public_ip = (known after apply)
+ secondary_private_ips = (known after apply)
+ security_groups = (known after apply)
+ source_dest_check = true
+ subnet_id = "subnet-069a0f9b9c9f9f9f9"
+ tags = {
+ "Name" = "gitlab"
}
+ tags_all = {
+ "Name" = "gitlab"
}
+ tenancy = (known after apply)
+ user_data = (known after apply)
+ user_data_base64 = (known after apply)
+ user_data_replace_on_change = false
+ vpc_security_group_ids = (known after apply)
+ capacity_reservation_specification {
+ capacity_reservation_preference = (known after apply)
+ capacity_reservation_target {
+ capacity_reservation_id = (known after apply)
}
}
+ ebs_block_device {
+ delete_on_termination = (known after apply)
+ device_name = (known after apply)
+ encrypted = (known after apply)
+ iops = (known after apply)
+ kms_key_id = (known after apply)
+ snapshot_id = (known after apply)
+ tags = (known after apply)
+ throughput = (known after apply)
+ volume_id = (known after apply)
+ volume_size = (known after apply)
+ volume_type = (known after apply)
}
+ enclave_options {
+ enabled = (known after apply)
}
+ ephemeral_block_device {
+ device_name = (known after apply)
+ no_device = (known after apply)
+ virtual_name = (known after apply)
}
+ metadata_options {
+ http_endpoint = (known after apply)
+ http_put_response_hop_limit = (known after apply)
+ http_tokens = (known after apply)
+ instance_metadata_tags = (known after apply)
}
+ network_interface {
+ delete_on_termination = (known after apply)
+ device_index = (known after apply)
+ network_interface_id = (known after apply)
}
+ root_block_device {
+ delete_on_termination = true
+ device_name = (known after apply)
+ encrypted = (known after apply)
+ iops = (known after apply)
+ kms_key_id = (known after apply)
+ throughput = (known after apply)
+ volume_id = (known after apply)
+ volume_size = 60
+ volume_type = "standard"
}
}
# aws_security_group.gitlab will be created
+ resource "aws_security_group" "gitlab" {
+ arn = (known after apply)
+ description = "Security group for gitlab"
+ egress = [
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ description = "Allow all outbound traffic"
+ from_port = 0
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "-1"
+ security_groups = []
+ self = false
+ to_port = 0
},
]
+ id = (known after apply)
+ ingress = [
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ description = "allow public access http"
+ from_port = 80
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "tcp"
+ security_groups = []
+ self = false
+ to_port = 80
},
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ description = "allow public access https"
+ from_port = 443
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "tcp"
+ security_groups = []
+ self = false
+ to_port = 443
},
+ {
+ cidr_blocks = [
+ "0.0.0.0/0",
]
+ description = "test"
+ from_port = 22
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "tcp"
+ security_groups = []
+ self = false
+ to_port = 22
},
+ {
+ cidr_blocks = [
+ "10.0.0.0/16",
]
+ description = "allow ssh"
+ from_port = 22
+ ipv6_cidr_blocks = []
+ prefix_list_ids = []
+ protocol = "tcp"
+ security_groups = []
+ self = false
+ to_port = 22
},
]
+ name = "gitlab"
+ name_prefix = (known after apply)
+ owner_id = (known after apply)
+ revoke_rules_on_delete = false
+ tags = {
+ "Name" = "gitlab"
}
+ tags_all = {
+ "Name" = "gitlab"
}
+ vpc_id = "vpc-02fefefefefe"
+ timeouts {}
}
# aws_volume_attachment.ebs_attachment_gitlab will be created
+ resource "aws_volume_attachment" "ebs_attachment_gitlab" {
+ device_name = "/dev/sdh"
+ id = (known after apply)
+ instance_id = (known after apply)
+ volume_id = (known after apply)
}
Plan: 4 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
输入 yes 之后,我们的 4 种资源都会被创建好了。
aws_instance.gitlab: Creating...
aws_instance.gitlab: Still creating... [10s elapsed]
aws_instance.gitlab: Creation complete after 13s [id=i-0afefefefe]
aws_volume_attachment.ebs_attachment_gitlab: Creating...
aws_volume_attachment.ebs_attachment_gitlab: Still creating... [10s elapsed]
aws_volume_attachment.ebs_attachment_gitlab: Still creating... [20s elapsed]
aws_volume_attachment.ebs_attachment_gitlab: Creation complete after 21s [id=vai-28fefefe]
Apply complete! Resources: 4 added, 0 changed, 0 destroyed.
eip
下面我们给 gitlab 机器分配一个 EIP,它是一个 public ip 地址,我们可以通过这个 EIP 来访问 gitlab 机器。
EN: Add public ip for ec2 instance
resource "aws_eip" "gitlab" {
vpc = true
tags = {
Name = "gitlab"
}
}
resource "aws_eip_association" "eip_association_gitlab" {
instance_id = aws_instance.gitlab.id
allocation_id = aws_eip.gitlab.id
}
执行 terraform plan 后,我们会看到下面的输出:
# aws_eip.gitlab will be created
+ resource "aws_eip" "gitlab" {
+ allocation_id = (known after apply)
+ association_id = (known after apply)
+ carrier_ip = (known after apply)
+ customer_owned_ip = (known after apply)
+ domain = (known after apply)
+ id = (known after apply)
+ instance = (known after apply)
+ network_border_group = (known after apply)
+ network_interface = (known after apply)
+ private_dns = (known after apply)
+ private_ip = (known after apply)
+ public_dns = (known after apply)
+ public_ip = (known after apply)
+ public_ipv4_pool = (known after apply)
+ tags = {
+ "Name" = "gitlab"
}
+ tags_all = {
+ "Name" = "gitlab"
}
+ vpc = true
}
# aws_eip_association.eip_association_gitlab will be created
+ resource "aws_eip_association" "eip_association_gitlab" {
+ allocation_id = (known after apply)
+ id = (known after apply)
+ instance_id = (known after apply)
+ network_interface_id = (known after apply)
+ private_ip_address = (known after apply)
+ public_ip = (known after apply)
}
它会创建两个资源:一个 EIP 和一个 EIP 关联,这样,我们的 gitlab 机器就可以通过这个 EIP 访问了。
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# aws_eip.gitlab will be created
+ resource "aws_eip" "gitlab" {
+ allocation_id = (known after apply)
+ association_id = (known after apply)
+ carrier_ip = (known after apply)
+ customer_owned_ip = (known after apply)
+ domain = (known after apply)
+ id = (known after apply)
+ instance = (known after apply)
+ network_border_group = (known after apply)
+ network_interface = (known after apply)
+ private_dns = (known after apply)
+ private_ip = (known after apply)
+ public_dns = (known after apply)
+ public_ip = (known after apply)
+ public_ipv4_pool = (known after apply)
+ tags = {
+ "Name" = "gitlab"
}
+ tags_all = {
+ "Name" = "gitlab"
}
+ vpc = true
}
# aws_eip_association.eip_association_gitlab will be created
+ resource "aws_eip_association" "eip_association_gitlab" {
+ allocation_id = (known after apply)
+ id = (known after apply)
+ instance_id = "i-0afefefefe"
+ network_interface_id = (known after apply)
+ private_ip_address = (known after apply)
+ public_ip = (known after apply)
}
Plan: 2 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
aws_eip.gitlab: Creating...
aws_eip.gitlab: Creation complete after 0s [id=eipalloc-ppp-kkk-0xff0xff]
aws_eip_association.eip_association_gitlab: Creating...
aws_eip_association.eip_association_gitlab: Creation complete after 1s [id=eipassoc-kukukulala]
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
gitlab setup
在结束了基础设施的创建之后,我们需要安装及设置 gitlab 软件本身。
我们使用 https://github.com/sameersbn/docker-gitlab 这个作为 GitLab 的镜像来安装 gitlab。
准备 docker-compose.yml 文件,运行 docker-compose up -d 命令,这样我们就可以看到 gitlab 在运行了。
version: "2.3"
services:
redis:
restart: always
image: redis:6.2.6
command:
- --loglevel warning
volumes:
- ./redis-data:/data:Z
postgresql:
restart: always
image: sameersbn/postgresql:12-20200524
volumes:
- ./postgresql-data:/var/lib/postgresql:Z
environment:
- DB_USER=gitlab
- DB_PASS=password
- DB_NAME=gitlabhq_production
- DB_EXTENSION=pg_trgm,btree_gist
gitlab:
restart: always
image: sameersbn/gitlab:14.9.2
depends_on:
- redis
- postgresql
ports:
- "10080:80"
# - "443:443"
- "10022:22"
volumes:
- ./gitlab-data:/home/git/data:Z
healthcheck:
test: ["CMD", "/usr/local/sbin/healthcheck"]
interval: 5m
timeout: 10s
retries: 3
start_period: 5m
environment:
- DEBUG=true
- DB_ADAPTER=postgresql
- DB_HOST=postgresql
- DB_PORT=5432
- DB_USER=gitlab
- DB_PASS=password
- DB_NAME=gitlabhq_production
- REDIS_HOST=redis
- REDIS_PORT=6379
- GITLAB_HTTPS=false
#- SSL_SELF_SIGNED=true
- GITLAB_HOST=<eip ipv4 address>
#- GITLAB_PORT=443
- GITLAB_SSH_PORT=10022
- GITLAB_RELATIVE_URL_ROOT=
- GITLAB_SECRETS_DB_KEY_BASE=FF11111
- GITLAB_SECRETS_SECRET_KEY_BASE=FF22222
- GITLAB_SECRETS_OTP_KEY_BASE=FF33333
volumes:
redis-data:
postgresql-data:
gitlab-data:
GitLab clone
因为我们在 docker-compose.yml 中指定了 10022:22 这样的端口映射,在克隆代码时,所以我们需要指定端口信息:
git clone ssh://git@<public_ip>:10022/<username>/<repo>.git
GitLab administration
gitlab 运行之后,我们可以对 gitlab 进行管理以增加其安全性,比如:
- 开启两步认证
MFA - 禁用注册功能,只允许用户通过邮箱登录,取消勾选
Menu > Admin > Settings > General > Sign-up restrictions > Sign-up enabled - 进入
Menu > Admin > Settings > General > Visibility and access controls section,限制Restricted visibility levels为public,这样可以限制只有登录用户才能查看 user profile - 取消用户注册,设置
Sign-up restrictions为disabled - 限制两步认证才能登录,勾选
Sign-in restrictions > Two-factor authentication > Enforce two-factor authentication
好了,说到这里 GitLab 已经初步搭建完成,下面就可以自由的写 bug 啦。
Manage AWS DMS resource using terraform
我们如何管理云服务中现有的资源呢?此时需要 terraform import 来帮忙。
我们拿 AWS DMS(Data Migration Service)来举例。
一般来讲,DMS 会有复制实例(Replication Instance)用来执行数据的迁移,下面我们来通过 terraform 来管理一个现有的复制实例。
从 AWS console 中查询需要管理的复制实例的 ARN:arn:aws-cn:dms:cn-northwest-1:501502503504:rep:DOYOUTHINKTERRAFORMISAGOODTOOL,因为 import 需要用到这个资源 ID。
下面开始 import。
首先,给 terraform 来个 alias:
alias t=terraform
其次,运行 terraform import:
t import aws_dms_replication_instance.feature arn:aws-cn:dms:cn-northwest-1:501502503504:rep:DOYOUTHINKTERRAFORMISAGOODTOOL
输出:
aws_dms_replication_instance.feature: Importing from ID "arn:aws-cn:dms:cn-northwest-1:501502503504:rep:DOYOUTHINKTERRAFORMISAGOODTOOL"...
aws_dms_replication_instance.feature: Import prepared!
Prepared aws_dms_replication_instance for import
aws_dms_replication_instance.feature: Refreshing state... [id=arn:aws-cn:dms:cn-northwest-1:501502503504:rep:DOYOUTHINKTERRAFORMISAGOODTOOL]
╷
│ Error: error describing DMS Replication Instance (arn:aws-cn:dms:cn-northwest-1:501502503504:rep:DOYOUTHINKTERRAFORMISAGOODTOOL): InvalidParameterValueException: The parameter value arn:aws-cn:dms:cn-northwest-1:501502503504:rep:DOYOUTHINKTERRAFORMISAGOODTOOL is not valid for argument Filter: replication-instance-id due to its length 86 exceeds 63.
│ status code: 400, request id: a6aaaaa3-1aaf-4aa6-aaa3-1aaaaaaaaaa5
│
│
Not set region correctly.
什么?竟然出错了: replication-instance-id due to its length 86 exceeds 63:
│ Error: error describing DMS Replication Instance (arn:aws-cn:dms:cn-northwest-1:501502503504:rep:DOYOUTHINKTERRAFORMISAGOODTOOL): InvalidParameterValueException: The parameter value arn:aws-cn:dms:cn-northwest-1:501502503504:rep:DOYOUTHINKTERRAFORMISAGOODTOOL is not valid for argument Filter: replication-instance-id due to its length 86 exceeds 63.
这个长度超过 63 的错是什么意思?
经过 google 半小时的查询,终于恍然大悟,原来 import 的参数不是 ARN,而是一个 ID。那这个 ID 在 AWS 里就是资源的 identifier。
于是修改 import 参数,传递 DMS 复制实例的 identifier,再次运行 terraform import。
t import aws_dms_replication_instance.feature featrue-dms-test
发现还是出错了:
aws_dms_replication_instance.feature: Importing from ID "featrue-dms-test"...
aws_dms_replication_instance.feature: Import prepared!
Prepared aws_dms_replication_instance for import
aws_dms_replication_instance.feature: Refreshing state... [id=featrue-dms-test]
╷
│ Error: Cannot import non-existent remote object
│
│ While attempting to import an existing object to "aws_dms_replication_instance.feature", the provider detected that no object
│ exists with the given id. Only pre-existing objects can be imported; check that the id is correct and that it is associated with
│ the provider's configured region or endpoint, or use "terraform apply" to create a new remote object for this resource.
╵
这次不是报长度的错了,而是 the provider detected that no object exists with the given id。
这个错误又是什么意思呢?
再经历了又半小时的 google 之后,发现可能是没有设置正确的 region 导致的,于是讲 AWS_DEFAULT_REGION 设置成正确的值之后,运行 import:
set_up_aws_profile_sandbox_and_region
t import aws_dms_replication_instance.feature featrue-dms-test
输出:
aws_dms_replication_instance.feature: Importing from ID "featrue-dms-test"...
aws_dms_replication_instance.feature: Import prepared!
Prepared aws_dms_replication_instance for import
aws_dms_replication_instance.feature: Refreshing state... [id=featrue-dms-test]
Import successful!
The resources that were imported are shown above. These resources are now in
your Terraform state and will henceforth be managed by Terraform.
Congratulations! 终于成功了!
下面看看我们有什么:
ls -lh
.rw-r--r-- 57 William Shakespear 27 Jun 13:47 main.tf
.rw-r--r-- 2.1k William Shakespear 30 Jun 10:27 terraform.tfstate
我们有一个 main.tf 的配置文件和 terraform.tfstate 的状态文件。于是我们可以运行 terraform plan 和 terraform apply 来创建或修改基础设施的变更了。值得注意的是,在执行 terraform apply 之前,会创建一个 plan ,这个 plan 是本地状态和云服务之间的差异,而 apply 则会将本地配置同步到云服务(此处为 AWS)。
下面我们运行 terraform plan。
就像 terraform plan --help 命令所说的:
Generates a speculative execution plan, showing what actions Terraform would take to apply the current configuration. This command will not actually perform the planned actions.
You can optionally save the plan to a file, which you can then pass to the "apply" command to perform exactly the actions described in the plan.
我们运行 terraform plan:
╷
│ Error: Missing required argument
│
│ on main.tf line 2, in resource "aws_dms_replication_instance" "feature":
│ 2: resource "aws_dms_replication_instance" "feature" {
│
│ The argument "replication_instance_id" is required, but no definition was found.
╵
╷
│ Error: Missing required argument
│
│ on main.tf line 2, in resource "aws_dms_replication_instance" "feature":
│ 2: resource "aws_dms_replication_instance" "feature" {
│
│ The argument "replication_instance_class" is required, but no definition was found.
出错啦!执行 terraform plan 提示了两个错: replication_instance_class 和 replication_instance_id 是必须的,我们没有提供。当然啦,我们的 main.tf 还是空空的状态。
There's error when executing
terraform plan, it shows"replication_instance_id" is required, but no definition was found. What isreplication_instance_idanyway?
resource "aws_dms_replication_instance" "feature" {
}
在调查了 terraform 文档之后,我们补齐这两个必须参数。
resource "aws_dms_replication_instance" "feature" {
replication_instance_id = "feature-dms-test"
replication_instance_class = "dms.r5.xlarge"
}
执行 terraform plan:
aws_dms_replication_instance.feature: Refreshing state... [id=featrue-dms-test]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
-/+ destroy and then create replacement
Terraform will perform the following actions:
# aws_dms_replication_instance.feature must be replaced
-/+ resource "aws_dms_replication_instance" "feature" {
~ allocated_storage = 500 -> (known after apply)
~ auto_minor_version_upgrade = true -> (known after apply)
~ availability_zone = "cn-northwest-1c" -> (known after apply)
~ engine_version = "3.4.6" -> (known after apply)
~ id = "featrue-dms-test" -> (known after apply)
~ kms_key_arn = "arn:aws-cn:kms:cn-northwest-1:501502503504:key/39999999-9999-9999-9999-999999999999" -> (known after apply)
~ multi_az = false -> (known after apply)
~ preferred_maintenance_window = "mon:11:50-mon:12:20" -> (known after apply)
~ publicly_accessible = false -> (known after apply)
~ replication_instance_arn = "arn:aws-cn:dms:cn-northwest-1:501502503504:rep:ILOVEREADALLPOEMSOFWILLIAMSHAKESPEAR" -> (known after apply)
~ replication_instance_id = "featrue-dms-test" -> "feature-dms-test" # forces replacement
~ replication_instance_private_ips = [
- "100.200.100.1",
] -> (known after apply)
~ replication_instance_public_ips = [
- "",
] -> (known after apply)
~ replication_subnet_group_id = "default-vpc-010203040506070809" -> (known after apply)
- tags = {
- "description" = "featrue-dms-test"
} -> null
~ tags_all = {
- "description" = "featrue-dms-test"
} -> (known after apply)
~ vpc_security_group_ids = [
- "sg-a0b0c0d0a0b0c0d0",
] -> (known after apply)
# (1 unchanged attribute hidden)
- timeouts {}
}
Plan: 1 to add, 0 to change, 1 to destroy.
────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Note: You didn't use the -out option to save this plan, so Terraform can't guarantee to take exactly these actions if you run
"terraform apply" now.
太好了!终于像模像样的输出了!
可是,等等!为什么有 1 to add 和 1 to destroy 呢?难不成要摧毁我云服务的资源嘛?太可怕了。我先冷静冷静,下一步到底改干啥,可不要发生 rm -rf / 的惨剧。
在喝完咖啡,思索了一阵之后,得知一个重要结论。
我本地的配置 main.tf 和云服务的配置不匹配,但是本地只配置了 replication_instance_id 和 replication_instance_class,如果我执行 terraform apply,我就告诉 terraform:请给我创建一个 dms replication instance 资源,它的 replication_instance_id 和 replication_instance_class 分别如配置所说,其他参数看着给。于是 terraform 比较来比较去,发现只能先云服务现有的给删了(1 to destroy)再给我们创建一个(1 to add)。
这当然不是我们需要的。
那么我们应该怎么做呢?当然是拷贝 terraform plan 的输出(主要是波浪线的部分,这部分是 change)到 main.tf,完成手动云服务到本地配置的反向同步。
resource "aws_dms_replication_instance" "feature" {
replication_instance_id = "feature-dms-test"
replication_instance_class = "dms.r5.xlarge"
~ allocated_storage = 500 -> (known after apply)
~ auto_minor_version_upgrade = true -> (known after apply)
~ availability_zone = "cn-northwest-1c" -> (known after apply)
~ engine_version = "3.4.6" -> (known after apply)
~ id = "featrue-dms-test" -> (known after apply)
~ kms_key_arn = "arn:aws-cn:kms:cn-northwest-1:501502503504:key/39999999-9999-9999-9999-999999999999" -> (known after apply)
~ multi_az = false -> (known after apply)
~ preferred_maintenance_window = "mon:11:50-mon:12:20" -> (known after apply)
~ publicly_accessible = false -> (known after apply)
~ replication_instance_arn = "arn:aws-cn:dms:cn-northwest-1:501502503504:rep:ILOVEREADALLPOEMSOFWILLIAMSHAKESPEAR" -> (known after apply)
~ replication_instance_id = "featrue-dms-test" -> "feature-dms-test" # forces replacement
~ replication_instance_private_ips = [
- "100.200.100.1",
] -> (known after apply)
~ replication_instance_public_ips = [
- "",
] -> (known after apply)
~ replication_subnet_group_id = "default-vpc-010203040506070809" -> (known after apply)
- tags = {
- "description" = "featrue-dms-test"
} -> null
~ tags_all = {
- "description" = "featrue-dms-test"
} -> (known after apply)
~ vpc_security_group_ids = [
- "sg-a0b0c0d0a0b0c0d0",
] -> (known after apply)
# (1 unchanged attribute hidden)
- timeouts {}
}
于是,我们根据 terraform plan 的输出,填充到 main.tf 文件里:
resource "aws_dms_replication_instance" "feature" {
replication_instance_class = "dms.r5.xlarge"
allocated_storage = 500
auto_minor_version_upgrade = true
availability_zone = "cn-northwest-1c"
engine_version = "3.4.6"
id = "featrue-dms-test"
kms_key_arn = "arn:aws-cn:kms:cn-northwest-1:501502503504:key/39999999-9999-9999-9999-999999999999"
multi_az = false
preferred_maintenance_window = "mon:11:50-mon:12:20"
publicly_accessible = false
replication_instance_arn = "arn:aws-cn:dms:cn-northwest-1:501502503504:rep:ILOVEREADALLPOEMSOFWILLIAMSHAKESPEAR"
replication_instance_id = "feature-dms-test" # forces replacement
replication_instance_private_ips = [
"100.200.100.1",
]
replication_instance_public_ips = [
"",
]
replication_subnet_group_id = "default-vpc-010203040506070809"
tags = null
tags_all = {
"description" = "featrue-dms-test"
}
vpc_security_group_ids = [
"sg-a0b0c0d0a0b0c0d0",
]
timeouts {}
}
此时再次运行 terraform plan
╷
│ Error: Invalid or unknown key
│
│ with aws_dms_replication_instance.feature,
│ on main.tf line 9, in resource "aws_dms_replication_instance" "feature":
│ 9: id = "featrue-dms-test"
│
╵
╷
│ Error: Value for unconfigurable attribute
│
│ with aws_dms_replication_instance.feature,
│ on main.tf line 14, in resource "aws_dms_replication_instance" "feature":
│ 14: replication_instance_arn = "arn:aws-cn:dms:cn-northwest-1:501502503504:rep:ILOVEREADALLPOEMSOFWILLIAMSHAKESPEAR"
│
│ Can't configure a value for "replication_instance_arn": its value will be decided automatically based on the result of applying
│ this configuration.
╵
╷
│ Error: Value for unconfigurable attribute
│
│ with aws_dms_replication_instance.feature,
│ on main.tf line 16, in resource "aws_dms_replication_instance" "feature":
│ 16: replication_instance_private_ips = [
│ 17: "100.200.100.1",
│ 18: ]
│
│ Can't configure a value for "replication_instance_private_ips": its value will be decided automatically based on the result of
│ applying this configuration.
╵
╷
│ Error: Value for unconfigurable attribute
│
│ with aws_dms_replication_instance.feature,
│ on main.tf line 19, in resource "aws_dms_replication_instance" "feature":
│ 19: replication_instance_public_ips = [
│ 20: "",
│ 21: ]
│
│ Can't configure a value for "replication_instance_public_ips": its value will be decided automatically based on the result of
│ applying this configuration.
╵
它会提示一些错,意思是有些参数会在创建时决定,所以我们无须提供,注释掉对应的行如 replication_instance_private_ips 和 replication_instance_public_ips,再次运行 terraform plan。
Fix error by comment error line. As
replication_instance_private_ipsandreplication_instance_public_ipswill be decided automatically based on the result of applying this configuration. We comment it out and run plan again.
resource "aws_dms_replication_instance" "feature" {
publicly_accessible = false
# replication_instance_arn = "arn:aws-cn:dms:cn-northwest-1:501502503504:rep:ILOVEREADALLPOEMSOFWILLIAMSHAKESPEAR"
replication_instance_id = "feature-dms-test" # forces replacement
# replication_instance_private_ips = [
# "100.200.100.1",
# ]
# replication_instance_public_ips = [
# "",
# ]
}
但是我们还是会发现出错了,这是为什么呢?
But we also encounter an error, saying we will destroy the resource and recreate it.
aws_dms_replication_instance.feature: Refreshing state... [id=featrue-dms-test]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
-/+ destroy and then create replacement
Terraform will perform the following actions:
# aws_dms_replication_instance.feature must be replaced
-/+ resource "aws_dms_replication_instance" "feature" {
~ id = "featrue-dms-test" -> (known after apply)
~ replication_instance_arn = "arn:aws-cn:dms:cn-northwest-1:501502503504:rep:ILOVEREADALLPOEMSOFWILLIAMSHAKESPEAR" -> (known after apply)
~ replication_instance_id = "featrue-dms-test" -> "feature-dms-test" # forces replacement
~ replication_instance_private_ips = [
- "100.200.100.1",
] -> (known after apply)
~ replication_instance_public_ips = [
- "",
] -> (known after apply)
- tags = {
- "description" = "featrue-dms-test"
} -> null
~ tags_all = {
- "description" = "featrue-dms-test"
} -> (known after apply)
# (11 unchanged attributes hidden)
# (1 unchanged block hidden)
}
Plan: 1 to add, 0 to change, 1 to destroy.
我们尝试这删除本地 terraform.tfstate 文件,运行 terraform plan,发现错误依旧。
Delete terraform.state file and run
t import aws_dms_replication_instance.feature feature-dms-testwith correct name.
aws_dms_replication_instance.feature: Importing from ID "feature-dms-test"...
aws_dms_replication_instance.feature: Import prepared!
Prepared aws_dms_replication_instance for import
aws_dms_replication_instance.feature: Refreshing state... [id=feature-dms-test]
╷
│ Error: Cannot import non-existent remote object
│
│ While attempting to import an existing object to "aws_dms_replication_instance.feature", the provider detected that no object
│ exists with the given id. Only pre-existing objects can be imported; check that the id is correct and that it is associated with
│ the provider's configured region or endpoint, or use "terraform apply" to create a new remote object for this resource.
啊!细心的我终于发现是因为云服务的资源名字被叫错了!云服务的 identifier 叫做 featrue-dms-test,而我们需要 import 的名字叫做 feature-dms-test!我的心里唱起了深深太平洋底深深伤心,于是紧急联系相关人员这个名字是否可以更改,在得知这只是个测试任务可以改名字时,我果断(含泪)敲下了如下的命令:
Change dms replication instance identifier.
aws dms modify-replication-instance --replication-instance-arn arn:aws-cn:dms:cn-northwest-1:501502503504:rep:ILOVEREADALLPOEMSOFWILLIAMSHAKESPEAR --replication-instance-identifier feature-dms-test --apply-immediately
这是它的输出:
{
"ReplicationInstance": {
"ReplicationInstanceIdentifier": "feature-dms-test",
"ReplicationInstanceClass": "dms.r5.xlarge",
"ReplicationInstanceStatus": "available",
"AllocatedStorage": 500,
"InstanceCreateTime": "2022-05-23T12:59:24.006000+08:00",
"VpcSecurityGroups": [
{
"VpcSecurityGroupId": "sg-a0b0c0d0a0b0c0d0",
"Status": "active"
}
],
"AvailabilityZone": "cn-northwest-1c",
"ReplicationSubnetGroup": {
"ReplicationSubnetGroupIdentifier": "default-vpc-010203040506070809",
"ReplicationSubnetGroupDescription": "default group created by console for vpc id vpc-010203040506070809",
"VpcId": "vpc-010203040506070809",
"SubnetGroupStatus": "Complete",
"Subnets": [
{
"SubnetIdentifier": "subnet-0102030405060708",
"SubnetAvailabilityZone": {
"Name": "cn-northwest-1b"
},
"SubnetStatus": "Active"
},
{
"SubnetIdentifier": "subnet-0807060504030201",
"SubnetAvailabilityZone": {
"Name": "cn-northwest-1c"
},
"SubnetStatus": "Active"
},
{
"SubnetIdentifier": "subnet-1213141516171819",
"SubnetAvailabilityZone": {
"Name": "cn-northwest-1a"
},
"SubnetStatus": "Active"
}
]
},
"PreferredMaintenanceWindow": "mon:11:50-mon:12:20",
"PendingModifiedValues": {},
"MultiAZ": false,
"EngineVersion": "3.4.6",
"AutoMinorVersionUpgrade": true,
"KmsKeyId": "arn:aws-cn:kms:cn-northwest-1:501502503504:key/99999999999c6-4999999999999999999999",
"ReplicationInstanceArn": "arn:aws-cn:dms:cn-northwest-1:501502503504:rep:ILOVEREADALLPOEMSOFWILLIAMSHAKESPEAR",
"ReplicationInstancePrivateIpAddress": "100.200.100.1",
"ReplicationInstancePublicIpAddresses": [
null
],
"ReplicationInstancePrivateIpAddresses": [
"100.200.100.1"
],
"PubliclyAccessible": false
}
}
等待了片刻之后,identifier 被修改成功了。赶紧试试 terraform import 吧~
t import aws_dms_replication_instance.feature feature-dms-test
终于 import 成功了:
aws_dms_replication_instance.feature: Importing from ID "feature-dms-test"...
aws_dms_replication_instance.feature: Import prepared!
Prepared aws_dms_replication_instance for import
aws_dms_replication_instance.feature: Refreshing state... [id=feature-dms-test]
Import successful!
The resources that were imported are shown above. These resources are now in
your Terraform state and will henceforth be managed by Terraform.
此时的 main.tf 依旧空空如也,我们仿照先前的做法,将 terraform plan 的输出写到 main.tf 里。
t plan
输出:
aws_dms_replication_instance.feature: Refreshing state... [id=feature-dms-test]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
~ update in-place
Terraform will perform the following actions:
# aws_dms_replication_instance.feature will be updated in-place
~ resource "aws_dms_replication_instance" "feature" {
id = "feature-dms-test"
~ tags = {
- "description" = "featrue-dms-test" -> null
}
~ tags_all = {
- "description" = "featrue-dms-test"
} -> (known after apply)
# (15 unchanged attributes hidden)
# (1 unchanged block hidden)
}
Plan: 0 to add, 1 to change, 0 to destroy.
我们看到,add 和 destroy 都变成 0 了,一个很大的进步!这就是说,我们即使执行 terraform apply 也不会误操作发生删除资源的事故。
下面要做的就是修复那些 modify 的部分(波浪线),如果无关紧要的话(比如 tag 之类的)可以放着不管,如果有洁癖的话(遵循 best practice),可以在 main.tf 里做些调整。
We can see both add and destroy number is 0, we don't need to worry about any resource will be deleted, which may cause desaster, and it's best practice to add description to aws resource.
Now we know there's no add or destroy, we can apply the changes by runing
terraform apply. Notice, you need to enteryesto perform the actions.
此时运行 t apply:
输出:
aws_dms_replication_instance.feature: Refreshing state... [id=feature-dms-test]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
~ update in-place
Terraform will perform the following actions:
# aws_dms_replication_instance.feature will be updated in-place
~ resource "aws_dms_replication_instance" "feature" {
id = "feature-dms-test"
~ tags = {
- "description" = "featrue-dms-test" -> null
}
~ tags_all = {
- "description" = "featrue-dms-test"
} -> (known after apply)
# (15 unchanged attributes hidden)
# (1 unchanged block hidden)
}
Plan: 0 to add, 1 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
aws_dms_replication_instance.feature: Modifying... [id=feature-dms-test]
aws_dms_replication_instance.feature: Modifications complete after 0s [id=feature-dms-test]
Apply complete! Resources: 0 added, 1 changed, 0 destroyed.
此时 apply 成功,我们把一个 AWS DMS 的复制示例通过 terraform 来管理了,是不是很简单(真的有吗)?
After applying the changes, we can check if there's any difference between our local infrastructure and the infrastructure in the cloud by running
terraform planagain.
在执行完 terraform apply 之后,我们再次执行 terraform plan,它会因为检测不到变更(本地配置已经和云服务同步)而不做其他操作。
aws_dms_replication_instance.feature: Refreshing state... [id=feature-dms-test]
No changes. Your infrastructure matches the configuration.
Terraform has compared your real infrastructure against your configuration and found no differences, so no changes are needed.
这样,我们就可以如法炮制 import 其他的资源了。
Life is hard? Life is hard.
terraform doc:
https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/dms_replication_instance
Review terraform import
首先看一下 terraform import 的参数:
The import command expects two arguments.
Usage: terraform [global options] import [options] ADDR ID
Import existing infrastructure into your Terraform state.
This will find and import the specified resource into your Terraform
state, allowing existing infrastructure to come under Terraform
management without having to be initially created by Terraform.
The ADDR specified is the address to import the resource to. Please
see the documentation online for resource addresses. The ID is a
resource-specific ID to identify that resource being imported. Please
reference the documentation for the resource type you're importing to
determine the ID syntax to use. It typically matches directly to the ID
that the provider uses.
The current implementation of Terraform import can only import resources
into the state. It does not generate configuration. A future version of
Terraform will also generate configuration.
Because of this, prior to running terraform import it is necessary to write
a resource configuration block for the resource manually, to which the
imported object will be attached.
This command will not modify your infrastructure, but it will make
network requests to inspect parts of your infrastructure relevant to
the resource being imported.
Options:
-config=path Path to a directory of Terraform configuration files
to use to configure the provider. Defaults to pwd.
If no config files are present, they must be provided
via the input prompts or env vars.
-allow-missing-config Allow import when no resource configuration block exists.
-input=false Disable interactive input prompts.
-lock=false Don't hold a state lock during the operation. This is
dangerous if others might concurrently run commands
against the same workspace.
-lock-timeout=0s Duration to retry a state lock.
-no-color If specified, output won't contain any color.
-var 'foo=bar' Set a variable in the Terraform configuration. This
flag can be set multiple times. This is only useful
with the "-config" flag.
-var-file=foo Set variables in the Terraform configuration from
a file. If "terraform.tfvars" or any ".auto.tfvars"
files are present, they will be automatically loaded.
-ignore-remote-version A rare option used for the remote backend only. See
the remote backend documentation for more information.
-state, state-out, and -backup are legacy options supported for the local
backend only. For more information, see the local backend's documentation.
运行 terraform import,导入安全组(security group):
terraform import aws_security_group.gitlab sg-f2f2f2f2f2f2f2f2
Error: resource address "aws_security_group.gitlab" does not exist in the configuration.
Before importing this resource, please create its configuration in the root module. For example:
resource "aws_security_group" "gitlab" {
# (resource arguments)
}
在导入资源的时候,提示错误,我们必须首先创建资源的配置,然后再导入资源。
在 main.tf 文件里添加以上资源 resource "aws_security_group" "gitlab" {},再次运行 terraform import 命令:
terraform import aws_security_group.gitlab sg-f2f2f2f2f2f2f2f2
输出:
aws_security_group.gitlab: Importing from ID "sg-f2f2f2f2f2f2f2f2"...
aws_security_group.gitlab: Import prepared!
Prepared aws_security_group for import
aws_security_group.gitlab: Refreshing state... [id=sg-f2f2f2f2f2f2f2f2]
Import successful!
The resources that were imported are shown above. These resources are now in
your Terraform state and will henceforth be managed by Terraform.
import 之后,运行 terraform plan 来检查状态:
aws_security_group.gitlab: Refreshing state... [id=sg-f2f2f2f2f2f2f2f2]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
-/+ destroy and then create replacement
Terraform will perform the following actions:
# aws_security_group.gitlab must be replaced
-/+ resource "aws_security_group" "gitlab" {
~ arn = "arn:aws:ec2:us-east-1:81818181888:security-group/sg-f2f2f2f2f2f2f2f2" -> (known after app
ly)
~ description = "Security group for gitlab" -> "Managed by Terraform" # forces replacement
~ egress = [
- {
- cidr_blocks = [
- "0.0.0.0/0",
]
- description = ""
- from_port = 0
- ipv6_cidr_blocks = []
- prefix_list_ids = []
- protocol = "-1"
- security_groups = []
- self = false
- to_port = 0
},
] -> (known after apply)
~ id = "sg-f2f2f2f2f2f2f2f2" -> (known after apply)
~ ingress = [
- {
- cidr_blocks = [
- "55.188.0.0/16",
]
- description = ""
- from_port = 22
- ipv6_cidr_blocks = []
- prefix_list_ids = []
- protocol = "tcp"
- security_groups = []
- self = false
- to_port = 22
},
- {
- cidr_blocks = []
- description = "r2r2-v2"
- from_port = 10080
- ipv6_cidr_blocks = []
- prefix_list_ids = []
- protocol = "tcp"
- security_groups = [
- "sg-0x1231238888",
]
- self = false
- to_port = 10080
},
] -> (known after apply)
~ name = "gitlab" -> (known after apply)
+ name_prefix = (known after apply)
~ owner_id = "81818181888" -> (known after apply)
+ revoke_rules_on_delete = false
- tags = {
- "Name" = "gitlab"
} -> null
~ tags_all = {
- "Name" = "gitlab"
} -> (known after apply)
~ vpc_id = "vpc-0102030401020304" -> (known after apply)
- timeouts {}
}
Plan: 1 to add, 0 to change, 1 to destroy.
Note: You didn't use the -out option to save this plan, so Terraform can't guarantee to take exactly these actions if you run
"terraform apply" now.
可以看到,我们导入的资源没有在 main.tf 配置文件中,如果现在我们运行 terraform apply 则会删除这些资源。
为了让 terraform.tfstate 和 cloud provider 的配置一致,需要手动修改 tf 文件,添加对 import 资源的配置,添加的方法,基本上将 terraform plan 的输出(注意去掉 - ~ 这些)拷贝到对应的 resource 中,并做一些调整。对于 security group,添加资源配置的方法如下:
resource "aws_security_group" "gitlab" {
# arn = "arn:aws:ec2:us-east-1:81818181888:security-group/sg-f2f2f2f2f2f2f2f2" -> (known after apply)
description = "Security group for gitlab"
egress = [
{
cidr_blocks = [
"0.0.0.0/0",
]
description = ""
from_port = 0
ipv6_cidr_blocks = []
prefix_list_ids = []
protocol = "-1"
security_groups = []
self = false
to_port = 0
},
]
# id = "sg-f2f2f2f2f2f2f2f2" -> (known after apply)
ingress = [
{
cidr_blocks = [
"55.188.0.0/16",
]
description = ""
from_port = 22
ipv6_cidr_blocks = []
prefix_list_ids = []
protocol = "tcp"
security_groups = []
self = false
to_port = 22
},
{
cidr_blocks = []
description = "r2r2-v2"
from_port = 10080
ipv6_cidr_blocks = []
prefix_list_ids = []
protocol = "tcp"
security_groups = [
"sg-0x1231238888",
]
self = false
to_port = 10080
},
]
name = "gitlab"
# owner_id = "81818181888" -> (known after apply)
revoke_rules_on_delete = false
tags = {
"Name" = "gitlab"
}
tags_all = {
"Name" = "gitlab"
}
vpc_id = "vpc-0102030401020304"
timeouts {}
}
首先 terraform init:
Initializing the backend...
Initializing provider plugins...
- Finding latest version of hashicorp/aws...
- Installing hashicorp/aws v4.1.0...
- Installed hashicorp/aws v4.1.0 (signed by HashiCorp)
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
refs
https://www.terraform.io/cli/import/usage
一个 s3 bucket 分配权限的 terraform 管理介绍.md
Intro
作为一个 S3 的管理员,一个很常见的场景是,需要对分配给某个用户对某个 bucket 写操作的权限。
针对 bucket 的授权,我们可以使用 bucket policy 或 user policy 或同时使用二者,此时我们采取同时使用二者的方案。
这里涉及到以下几方面:
- IAM User:权限的被授予者,AWS account 下的普通用户
- AWS Account Administrator:权限的授予者,是通过根凭证(Root credentials)创建的具有 Admin 权限的管理员用户
- S3 bucket:需要一定权限访问的 S3 bucket
- bucket policy:附加到 bucket 上的策略
- user policy:附加给用户的策略
操作流程如下,其中 Root credentials 创建 AWS Account Administrator 已省略:
- 1、AWS Account Administrator 创建 bucket(如果测试 bucket 已存在,这步可以省略)
- 2、AWS Account Administrator 创建 IAM User,用户名 testuser,记录 credentials 和 arn
- 3、给测试 bucket 附加 bucket policy,允许 testuser 拥有
s3:GetBucketLocation和s3:ListBucket两个权限,另外允许对 bucket 下子路径s3:GetObject的权限 - 4、给 testuser 附加对 bucket
s3:GetObject的权限,可以上传文件
第一步
创建 bucket 比较简单,我们在 aws 控制台简单创建了一个用于测试目的的 bucket 叫 k8s-cluster-bucket-test。
第二步
创建一个 users module,方便模块化管理。
variables.tf 文件定义了 module 的参数:
variable "username" {
default = ""
}
outputs.tf 定义了模块的输出,为了给 iam user 附加 policy,此时我们需要输出 iam user 的 arn。
output "user_arn" {
value = "${aws_iam_user.user.arn}"
}
如果把 module 看作一个函数的话,user_arn 这个 output 类似 module 的返回值,它将在给 bucket 设置 policy 及 iam user 设置 policy 时都会用到。
利用 aws_iam_user 来创建 iam user:
main.tf
resource "aws_iam_user" "user" { name = "${var.username}" }
我们可以利用这个 module 创建多个符合特定条件的 user,模块化能让代码结构更加清晰。如创建一个叫 testuser 的 iam user 可以这么做:
module "testuser" {
source="./users"
username = "testuser"
}
第三步
因为 bucket policy 需要知晓 iam user 的 arn,所以我们在 variables.tf 做了定义:
variables.tf
variable "user_arn" {
default = ""
}
之后我们使用 aws_iam_policy_document 来定义附加给 bucket 的 policy。
aws_iam_policy_document 是一个 data source,可以理解为它会生成我们需要的 bucket policy。
为了简化,我们 hardcode 了 bucket 的 arn,当然更好的做法是把它作为变量抽象出来,也就是放到 module 的 variables.tf 里
。
data "aws_iam_policy_document" "s3-bucket-policy-document" {
statement {
effect = "Allow"
actions = [
"s3:GetBucketLocation",
"s3:ListBucket"
]
principals {
type = "AWS"
identifiers = [
"${var.user_arn}"
]
}
resources = [
"arn:aws-cn:s3:::k8s-cluster-bucket-test"
]
}
statement {
effect = "Allow"
actions = [
"s3:GetObject"
]
principals {
type = "AWS"
identifiers = [
"${var.user_arn}"
]
}
resources = [
"arn:aws-cn:s3:::k8s-cluster-bucket-test/*"
]
}
}
这里包含两个 statement,如上所述,第一个 statement 允许 testuser 拥有 s3:GetBucketLocation 和 s3:ListBucket 两个权限,第二个 statement 允许对 bucket 下子路径拥有 s3:GetObject 的权限。
Principal 是权限的委托人,此时的例子用来给 IAM User 访问 s3 bucket resource 的权限。除此之外,委托人还包括很多类型如特定 AWS 账户、单个或多个 iam user、iam role 或 aws 的服务,具体可参考 Principal 的官方文档。
利用 aws_s3_bucket_policy 定义资源,这将给我们的目标 bucket 附加 policy。
resource "aws_s3_bucket_policy" "k8s-cluster-bucket-test" {
bucket = "k8s-cluster-bucket-test"
policy = "${data.aws_iam_policy_document.s3-bucket-policy-document.json}"
}
第四步
回到 users module。
我们利用 aws_iam_policy 来创建针对指定 bucket 的写权限 s3:PutObject。
resource "aws_iam_policy" "s3-put-object-policy" {
name = "s3-put-object-policy"
description = "A s3 pub object policy"
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "PermissionForObjectOperations",
"Effect": "Allow",
"Action": [
"s3:PutObject"
],
"Resource": [
"arn:aws-cn:s3:::k8s-cluster-bucket-test/*"
]
}
]
}
EOF
}
然后通过 aws_iam_user_policy_attachment 来给新创建的 iam user 附加 policy。
resource "aws_iam_user_policy_attachment" "s3-put-object-policy-attach" {
user = "${aws_iam_user.user.name}"
policy_arn = "${aws_iam_policy.s3-put-object-policy.arn}"
}
测试
需要在 aws credentials 里使用 testuser 的 credentials 来指定用 testuser 运行 aws 命令。
当我们没有开放权限时(未添加第四步的配置),上传文件会出错:
$ aws s3api put-object --bucket k8s-cluster-bucket-test --key 1.png --body 1.png
An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
添加了对指定 bucket 的 PutObject 权限之后,上传成功了(It works!)。
$ aws s3api put-object --bucket k8s-cluster-bucket-test --key 1.png --body 1.png
{
"ETag": "\"c4df98a9588d3baba05aaa9212e2fe37\""
}
题图 lensinkmitchel from unsplash
摘要
作为一个 aws 的管理员,只需要一个技能让你告别 aws 控制台
Refs
https://docs.aws.amazon.com/AmazonS3/latest/dev/example-walkthroughs-managing-access-example1.html
参考: https://docs.aws.amazon.com/AmazonS3/latest/dev/example-walkthroughs-managing-access.html
更复杂一点的例子:
为 S3 存储桶中的对象授予公共读取访问权限 https://amazonaws-china.com/cn/premiumsupport/knowledge-center/read-access-objects-s3-bucket/
如何将亚马逊 AWS S3 存储桶的访问权限到一个特定 IAM 角色 | 亚马逊 AWS 官方博客 https://amazonaws-china.com/cn/blogs/china/securityhow-to-restrict-amazon-s3-bucket-access-to-a-specific-iam-role/
How to Restrict Amazon S3 Bucket Access to a Specific IAM Role | AWS Security Blog https://amazonaws-china.com/cn/blogs/security/how-to-restrict-amazon-s3-bucket-access-to-a-specific-iam-role/
A Good Developer knows management
没有不好的管理者,只有懒的管理者。
先看下我们在哪里:
$pwd
/home/fantasticmachine/terraform
像我们写 Hello world 的时候,我们需要一个 main 文件,另外的变量文件 variables.tf 体现了编程语言里的模块化思想:
$tree
.
├── main.tf
└── variables.tf
variables.tf 定义了我们需要的变量,如 access_key secret_key 和 region
$cat variables.tf
variable "access_key" {}
variable "secret_key" {}
variable "region" {
default = "cn-north-1"
}
为了让 terraform 访问 aws,需要在 main 文件里加入 iam 配置,即加入 access_key 和 secret_key,配置信息需要放在 terraform 的 aws provider 里:
$cat main.tf
provider "aws" {
access_key = "${var.access_key}"
secret_key = "${var.secret_key}"
region = "${var.region}"
}
为了让 terraform 顺利连接 aws,我们需要在 bash 的环境变量里指定 access_key 和 secret_key:
export TF_VAR_access_key="AKIAPLONGTIMEAGO"
export TF_VAR_secret_key="Lukeskywalkershowmehowtousesword"
export AWS_ACCESS_KEY=$TF_VAR_access_key
export AWS_SECRET_KEY=$TF_VAR_secret_key
export EC2_REGION=cn-north-1
好了,先拿 iam 开刀。
在控制台已经建了几个 group,如 Developer 等,我们现在让 terraform 管理。
导入到 main.tf 配置中:
$terraform import aws_iam_group.Developers developers
Error: resource address "aws_iam_group.Developers" does not exist in the configuration.
Before importing this resource, please create its configuration in the root module. For example:
resource "aws_iam_group" "Developers" {
# (resource arguments)
}
发现出错了!
错误信息说 aws_iam_group.Developers 这个资源不在配置文件中,需要我们手动创建。
$cat >> main.tf <<EOF
resource "aws_iam_group" "Developers" {
# (resource arguments)
}
EOF
按照提示做好之后,再次运行 terraform import:
$terraform import aws_iam_group.Developers developers
Plugin reinitialization required. Please run "terraform init".
Reason: Could not satisfy plugin requirements.
Plugins are external binaries that Terraform uses to access and manipulate
resources. The configuration provided requires plugins which can't be located,
don't satisfy the version constraints, or are otherwise incompatible.
1 error(s) occurred:
* provider.aws: no suitable version installed
version requirements: "(any version)"
versions installed: none
Terraform automatically discovers provider requirements from your
configuration, including providers used in child modules. To see the
requirements and constraints from each module, run "terraform providers".
error satisfying plugin requirements
还是出错,再耐心看下出错信息:plugin 需要重新初始化,我们还要再运行 terraform init:
$terraform init
Initializing provider plugins...
- Checking for available provider plugins on https://releases.hashicorp.com...
- Downloading plugin for provider "aws" (2.3.0)...
The following providers do not have any version constraints in configuration,
so the latest version was installed.
To prevent automatic upgrades to new major versions that may contain breaking
changes, it is recommended to add version = "..." constraints to the
corresponding provider blocks in configuration, with the constraint strings
suggested below.
* provider.aws: version = "~> 2.3"
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
此时插件下载完毕,同时还提示在配置文件中加入 provider.aws: version = "~> 2.3" 来锁版本,防止大版本升级带来的 breaking changes,接触包管理工具,这点我们早已习以为常。
sed -i '/provider "aws" {/a \ \ version = "~> 2.3"' main.tf
那我们再来导入下吧。
$terraform import aws_iam_group.Developers developers
aws_iam_group.Developers: Importing from ID "developers"...
aws_iam_group.Developers: Import complete!
Imported aws_iam_group (ID: developers)
aws_iam_group.Developers: Refreshing state... (ID: developers)
Import successful!
The resources that were imported are shown above. These resources are now in
your Terraform state and will henceforth be managed by Terraform.
功夫不负有心人,终于成功了!
$terraform import aws_iam_group.Developers developers
aws_iam_group.Developers: Importing from ID "developers"...
aws_iam_group.Developers: Import complete!
Imported aws_iam_group (ID: developers)
aws_iam_group.Developers: Refreshing state... (ID: developers)
Import successful!
The resources that were imported are shown above. These resources are now in
your Terraform state and will henceforth be managed by Terraform.
看看我们的 terraform.tfstate 状态吧。
$cat terraform.tfstate
{
"version": 3,
"terraform_version": "0.11.3",
"serial": 1,
"lineage": "95330000-1111-2222-3333-444455556666",
"modules": [
{
"path": [
"root"
],
"outputs": {},
"resources": {
"aws_iam_group.Developers": {
"type": "aws_iam_group",
"depends_on": [],
"primary": {
"id": "developers",
"attributes": {
"arn": "arn:aws-cn:iam::311112222333:group/Developers",
"id": "developers",
"name": "Developers",
"path": "/",
"unique_id": "AGPUNIQUESLASHID"
},
"meta": {},
"tainted": false
},
"deposed": [],
"provider": "provider.aws"
}
},
"depends_on": []
}
]
}
terraform.tfstate 是集群真实状态的一个映射,也就是说,当运行 terraform apply 之后,集群的真实状态和本地配置和 terraform.tfstate 三者是等同的。
接下来,我们可以照猫画虎来导入其他 groups、roles 和 users 等,这样 iam 就可以统一用 terraform 来管理了,我们甚至能管理 ec2、security group 甚至整个 vpc。这样的好处不言而喻,我们可以随时监听真实世界的一草一木,因为 terraform plan 会很容易发现真实世界和本地配置的差异,任何对 iam 的修改都已在我们的掌控之中。
题图
https://unsplash.com/@leonelfdez
CronJob To Restart Deployment
CronJob To Restart Deployment
Here is an example of how to restart deployment using cronjob.
---
# Service account the client will use to reset the deployment,
# by default the pods running inside the cluster can do no such things.
kind: ServiceAccount
apiVersion: v1
metadata:
name: deployment-restart
namespace: default
---
# allow getting status and patching only the one deployment you want to restart
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: deployment-restart
namespace: default
rules:
- apiGroups: ["apps", "extensions"]
resources: ["deployments"]
resourceNames: ["my-fast-and-robust-service"]
verbs:
# "list" and "watch" are only needed if you want to use `rollout status`
["get", "patch", "list", "watch"]
---
# bind the role to the service account
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: deployment-restart
namespace: default
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: deployment-restart
subjects:
- kind: ServiceAccount
name: deployment-restart
namespace: default
---
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: deployment-restart
namespace: default
spec:
concurrencyPolicy: Forbid
# cron spec of time, here, 8 o'clock
schedule: "0 1 * * *"
jobTemplate:
spec:
backoffLimit:
# this has very low chance of failing, as all this does
# is prompt kubernetes to schedule new replica set for
# the deployment
2
activeDeadlineSeconds:
# timeout, makes most sense with "waiting for rollout" variant specified below
600
template:
spec:
serviceAccountName:
# name of the service account configured above
deployment-restart
restartPolicy: Never
containers:
- name: kubectl
image:
# probably any kubectl image will do,
# optionaly specify version, but this
# should not be necessary, as long the
# version of kubectl is new enough to
# have `rollout restart`
bitnami/kubectl
command:
- "kubectl"
- "rollout"
- "restart"
- "deployment/my-fast-and-robust-service"
这是一份 Kubernetes YAML 配置文件,用于创建一个 CronJob,定期重启指定名称的 Deployment。以下是配置文件的解释:
-
通过创建 ServiceAccount,确保 Kubernetes 能够在崩溃时自动重启 Deployment。
-
创建一个 RBAC Role,允许使用
get、patch、list和watch操作,但仅限于指定的 Deployment(即my-fast-and-robust-service)。 -
创建一个 RBAC RoleBinding,将上述角色与先前创建的 ServiceAccount 绑定。
-
创建一个 CronJob,定义了要执行的任务和运行频率。该任务将定期启动一个 Pod,并使用 kubectl 命令重启指定的 Deployment。
总之,这个配置文件实现了一个可以定期重启指定 Deployment 的 CronJob,以确保 Deployment 在运行过程中保持稳定性和可用性。这可能会有助于解决某些资源耗尽或性能问题,以及其他可能导致 Deployment 失败的情况。请注意,这应该被视为一种应急措施,应该在确定没有更好的解决方案之前谨慎使用。
Explain line by line
ServiceAccount
好的,下面是这个 YAML 配置文件中每一行的解释:
---
# Service account the client will use to reset the deployment,
# by default the pods running inside the cluster can do no such things.
kind: ServiceAccount
apiVersion: v1
metadata:
name: deployment-restart
namespace: default
-
---:指示 Kubernetes YAML 文件的开始。 -
# Service account the client will use to reset the deployment,:注释,提供了正在创建的 ServiceAccount 的描述。 -
kind: ServiceAccount:指定 Kubernetes 对象的类型,这里是 ServiceAccount。 -
apiVersion: v1:指定 API 版本,这里是 v1。 -
metadata::定义 Kubernetes 对象的元数据,包括名称和命名空间。 -
name: deployment-restart:指定创建的 ServiceAccount 的名称为 deployment-restart。 -
namespace: default:指定命名空间为 default。
Role
---
# allow getting status and patching only the one deployment you want to restart
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: deployment-restart
namespace: default
rules:
- apiGroups: ["apps", "extensions"]
resources: ["deployments"]
resourceNames: ["my-fast-and-robust-service"]
verbs:
# "list" and "watch" are only needed if you want to use `rollout status`
["get", "patch", "list", "watch"]
-
---:指示 Kubernetes YAML 文件的开始。 -
# allow getting status and patching only the one deployment you want to restart:注释,提供了所创建的 Role 的描述。 -
apiVersion: rbac.authorization.k8s.io/v1:指定 RBAC API 版本,这里是 v1。 -
kind: Role:指定 Kubernetes 对象类型为 Role。 -
metadata::定义 Kubernetes 对象的元数据,包括名称和命名空间。 -
name: deployment-restart:指定创建的 Role 的名称为 deployment-restart。 -
namespace: default:指定命名空间为 default。 -
rules::定义权限规则。 -
- apiGroups: ["apps", "extensions"]:指定 API 组。这里指定了 apps 和 extensions。 -
resources: ["deployments"]:指定资源种类,这里是 deployments。 -
resourceNames: ["my-fast-and-robust-service"]:指定资源名称,这里是 my-fast-and-robust-service。 -
verbs: ["get", "patch", "list", "watch"]:指定允许执行的操作,这里包括 get、patch、list 和 watch。
RoleBinding
---
# bind the role to the service account
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: deployment-restart
namespace: default
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: deployment-restart
subjects:
- kind: ServiceAccount
name: deployment-restart
namespace: default
-
---:指示 Kubernetes YAML 文件的开始。 -
# bind the role to the service account:注释,提供了 RoleBinding 的描述。 -
apiVersion: rbac.authorization.k8s.io/v1:指定 RBAC API 版本,这里是 v1。 -
kind: RoleBinding:指定 Kubernetes 对象类型为 RoleBinding。 -
metadata::定义 Kubernetes 对象的元数据,包括名称和命名空间。 -
name: deployment-restart:指定创建的 RoleBinding 的名称为 deployment-restart。 -
namespace: default:指定命名空间为 default。 -
roleRef::引用要绑定的角色。 -
apiGroup: rbac.authorization.k8s.io:指定 RBAC API 组。 -
kind: Role:指定角色类型为 Role。 -
name: deployment-restart:指定要绑定的角色的名称为 deployment-restart。 -
subjects::指定要绑定角色的主体(例如 ServiceAccount)。 -
- kind: ServiceAccount:指定主体对象的类型为 ServiceAccount。 -
name: deployment-restart:指定主体对象的名称为 deployment-restart。 -
namespace: default:指定主体对象所在的命名空间为 default。
CronJob
---
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: deployment-restart
namespace: default
spec:
concurrencyPolicy: Forbid
# cron spec of time, here, 8 o'clock
schedule: "0 1 * * *"
jobTemplate:
spec:
backoffLimit:
# this has very low chance of failing, as all this does
# is prompt kubernetes to schedule new replica set for
# the deployment
2
activeDeadlineSeconds:
# timeout, makes most sense with "waiting for rollout" variant specified below
600
template:
spec:
serviceAccountName:
# name of the service account configured above
deployment-restart
restartPolicy: Never
containers:
- name: kubectl
image:
# probably any kubectl image will do,
# optionaly specify version, but this
# should not be necessary, as long the
# version of kubectl is new enough to
# have `rollout restart`
bitnami/kubectl
command:
- "kubectl"
- "rollout"
- "restart"
- "deployment/my-fast-and-robust-service"
-
---:指示 Kubernetes YAML 文件的开始。 -
apiVersion: batch/v1beta1:指定批处理 API 版本,这里是 v1beta1。 -
kind: CronJob:指定 Kubernetes 对象类型为 CronJob。 -
metadata::定义 Kubernetes 对象的元数据,包括名称和命名空间。 -
name: deployment-restart:指定创建的CronJob的名称为 deployment-restart。 -
namespace: default:指定命名空间为default。 -
spec::定义 CronJob 的规范。 -
concurrencyPolicy: Forbid:指定并发策略为 Forbid,即如果上一个任务还未完成,则不会启动新的任务。 -
schedule: "0 1 * * *":指定 CronJob 的运行频率,这里是每天的凌晨 1 点。 -
jobTemplate::定义要执行的作业模板。 -
spec::指定作业的规范。 -
backoffLimit::定义作业的退避限制,即在失败后重试此作业的次数。这里设置为 2。 -
activeDeadlineSeconds::定义作业的运行时间截止日期(以秒为单位)。这里设置为 600 秒。 -
template::定义作业的 Pod 模板。 -
spec::指定 Pod 的规范。 -
serviceAccountName::指定 Pod 使用的 ServiceAccount 的名称,这里是 deployment-restart。 -
restartPolicy: Never:定义 Pod 的重启策略为 Never,即当 Pod 终止时不会自动重启。 -
containers::定义 Pod 中的容器列表。 -
- name: kubectl:指定容器的名称为 kubectl。 -
image: bitnami/kubectl:指定使用的 kubectl 容器镜像。 -
command::指定要在容器中执行的命令列表。 -
- "kubectl":指定要执行的第一个命令为 kubectl。 -
- "rollout":指定要执行的第二个命令为 rollout。 -
- "restart":指定要执行的第三个命令为 restart。 -
- "deployment/my-fast-and-robust-service":指定要重启的 Deployment 的名称为my-fast-and-robust-service。
总之,这个 YAML 配置文件定义了 CronJob,并使用 kubectl 命令重启指定的 Deployment。该 CronJob 将定期运行,并确保 Deployment 在运行过程中保持稳定性和可用性。
Pod security to access aws s3 files
- Intro
- 创建
IAM policy - 创建 service account 并和
IAM policy绑定 - 修改 Deployment 的 spec.template.spec.serviceAccountName
- Refs
Intro
部署在 kubernetes 的应用的安全性是值得考量的,为了提高安全性,我们可以通过以下的方式来保证应用的安全性,比如:
- 给
kubernetes的 worker node 添加IAM policy,这样 worker node 上运行的 pod 就可以通过 worker node 的IAM policy的权限来访问应用的资源 - 给
kubernetes的 service account 绑定IAM policy,这样 service account 可以通过IAM policy的权限来访问应用的资源
当然,worker node 添加 IAM policy 这种方式粒度比较粗糙,不太推荐,我们可以通过更精细的方式来保证应用的安全性。
创建 IAM policy
以下的脚本会创建一个 IAM policy,这个 IAM policy 可以被 kubernetes 的 service account 绑定,以便 service account 可以通过 IAM policy 的权限来访问应用的资源。
#!/bin/bash
POLICY_NAME="my-very-sensitive-bucket-service-account-policy"
K8S_SERVICE_ACCOUNT_ACCESS_S3_BUCKET_POLICY_FILE="k8s-service-account-access-s3-bucket-policy.json"
cat > $K8S_SERVICE_ACCOUNT_ACCESS_S3_BUCKET_POLICY_FILE <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "statement1",
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::test-bucket/my-very-sensitive-data/*"
]
}
]
}
EOF
aws iam create-policy \
--policy-name $POLICY_NAME \
--policy-document file://$K8S_SERVICE_ACCOUNT_ACCESS_S3_BUCKET_POLICY_FILE
上面的脚本首先会创建一个 IAM policy,这个 policy 会授予对 S3 的某个 bucket 的权限: ListBucket 和 GetObject。
创建 service account 并和 IAM policy 绑定
有了 IAM policy,我们可以创建一个 service account,并将 IAM policy 绑定到 service account 上。
account_id="12345678999"
cluster="test"
namespace="financial"
name="my-very-sensitive-bucket-service-account"
eksctl create iamserviceaccount \
--name $name \
--namespace $namespace \
--cluster $cluster \
--attach-policy-arn arn:aws:iam::12345678999:policy/$POLICY_NAME \
--approve
上面的脚本会通过 eksctl 创建一个名为 my-very-sensitive-bucket-service-account 的 kubernetes 的 service account,并且将上面创建的 policy 关联到这个 service account 上。
我们可以通过 kubectl 命令来验证这个 service account 的创建成功: kubectl -n financial get sa my-very-sensitive-bucket-service-account -oyaml
输出:
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::12345678999:role/eksctl-test-addon-iamserviceaccount-financial-Role1-3F4F5F6F7F8F
creationTimestamp: "2022-04-18T06:39:41Z"
labels:
app.kubernetes.io/managed-by: eksctl
name: my-very-sensitive-bucket-service-account
namespace: financial
resourceVersion: "123123123"
uid: 13232333-ffee-ffee-ffee-39393929339
secrets:
- name: my-very-sensitive-bucket-service-account-token-ffee33
修改 Deployment 的 spec.template.spec.serviceAccountName
有了 service account,我们可以修改 Deployment 的 spec.template.spec.serviceAccountName,这样 Deployment 就会使用这个 service account 了。
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx
namespace: logging
spec:
replicas: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
serviceAccountName: my-very-sensitive-bucket-service-account #this is where your service account is specified
hostNetwork: true
Refs
https://kubernetes-on-aws.readthedocs.io/en/latest/user-guide/service-accounts.html
assign iam role to service account(eksctl did it) https://docs.amazonaws.cn/en_us/eks/latest/userguide/specify-service-account-role.html
https://mr3docs.datamonad.com/docs/k8s/eks/access-s3/
https://aws.amazon.com/cn/premiumsupport/knowledge-center/eks-restrict-s3-bucket/
https://dzone.com/articles/how-to-use-aws-iam-role-on-aws-eks-pods
Kubebuilder quickstart
Intro
我们知道 k8s 部署应用非常繁琐,首先要配置 deployment, service,外部流量的引入还要使用 ingress,这就要同时维护三个文件,而利用 kubernetes operator 能大大简化部署操作。
我们采用 kuberbuilder 这个 framework 来开发 kubernenetes operator,要完成一个配置文件完成「kubectl apply 新建三连」的功能。
kubebuilder
首先安装 kubebuilder
os=$(go env GOOS)
arch=$(go env GOARCH)
v=2.3.1
# download kubebuilder and extract it to tmp
curl -L https://go.kubebuilder.io/dl/${v}/${os}/${arch} | tar -xz -C /tmp/
# move to a long-term location and put it on your path
# (you'll need to set the KUBEBUILDER_ASSETS env var if you put it somewhere else)
sudo mv /tmp/kubebuilder_${v}_${os}_${arch} /usr/local/kubebuilder
export PATH=$PATH:/usr/local/kubebuilder/bin
其次新建 kubebuilder 工程
kubebuilder init --domain example.com CustomImageDeploy
新建 group version kind
kubebuilder create api --group customimagedeploy --version v1 --kind CustomImageDeploy
定义 CRD Spec
接下来我们需要定义 CRD 的 Spec
// CustomImageDeploySpec defines the desired state of CustomImageDeploy
type CustomImageDeploySpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
// Image is the docker image with version info of CustomImageDeploy.
Image string `json:"image,omitempty"`
// Size is the number of pods to run
Size int32 `json:"size"`
// Port is the port of container
Port int32 `json:"port"`
}
这里定义了要运行的 docker image(Image),数量(Size)和 container 的端口(Port)
实现自定义 CRD 的 Reconcile
func (r *CustomImageDeployReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
}
Reconcile 函数实现了 operator 的功能。
Reconcile 内部实现
Reconcile logic
-
获取 CRD,处理
client.IgnoreNotFound(err),此时表示 CRD 被删除,Reconcile 返回ctrl.Result{}, nil,Reconcile loop 结束 -
处理
finalizer,如果ObjectMeta.DeletionTimestamp.IsZero()则表示未正在被删除,我们需要给 CRD 的ObjectMeta添加finalizer;否则我们判断 CRD 的 ObjectMeta 是否包含 finalizer,并删除其他外部资源,删除成功之后清除 ObjectMeta 中的finalizer,剩下删除的工作交给kubernetes去处理 -
获取
ingress,处理client.IgnoreNotFound(err),此时表示ingress尚未被创建,则需要调用r.Client.Create来创建 -
获取
deployment,处理client.IgnoreNotFound(err),此时表示deployment尚未被创建,则需要调用r.Client.Create来创建 -
获取
service,处理client.IgnoreNotFound(err),此时表示service尚未被创建,则需要调用r.Client.Create来创建 -
其他外部资源的处理,由于我们未使用其他外部资源,这里忽略
处理 CRD
log := r.Log.WithValues("customimagedeploy", req.NamespacedName)
log.Info("[CustomImageDeployReconciler::Reconsile]", "req: ", req)
cid := &customimagedeployv1.CustomImageDeploy{}
err := r.Client.Get(context.TODO(), req.NamespacedName, cid)
log.Info("Begin to use finalizer", "cid : ", cid)
if err != nil {
//if errors.IsNotFound(err) {
// // Request object not found, could have been deleted after reconcile req.
// // Owned objects are automatically garbage collected. For additional cleanup logic use finalizers.
// // Return and don't requeue
// log.Info("CustomImageDeploy resource not found. Ignoring since object must be deleted.")
// return ctrl.Result{}, nil
//}
//return ctrl.Result{}, err
log.Info("[CustomImageDeployReconciler::Reconsile] get err != nil", "err: ", err)
return ctrl.Result{}, client.IgnoreNotFound(err)
}
finalizer
f := "customimagedeploy.finalizers.example.com"
if cid.ObjectMeta.DeletionTimestamp.IsZero() {
log.Info("DeletionTimestamp.IsZero")
// The object is not being deleted, so if it does not have our finalizer,
// then lets add the finalizer and update the object.
if !containsString(cid.ObjectMeta.Finalizers, f) {
cid.ObjectMeta.Finalizers = append(cid.ObjectMeta.Finalizers, f)
if err := r.Update(context.Background(), cid); err != nil {
return reconcile.Result{}, err
}
}
} else {
// The object is being deleted
if containsString(cid.ObjectMeta.Finalizers, f) {
// our finalizer is present, so lets handle our external dependency
if err := r.deleteExternalDependency(cid); err != nil {
// if fail to delete the external dependency here, return with error
// so that it can be retried
return reconcile.Result{}, err
}
// remove our finalizer from the list and update it.
cid.ObjectMeta.Finalizers = removeString(cid.ObjectMeta.Finalizers, f)
if err := r.Update(context.Background(), cid); err != nil {
return reconcile.Result{}, err
}
}
// Our finalizer has finished, so the reconciler can do nothing.
return reconcile.Result{}, nil
}
其中 containsString 方法判断 finalizer 数组里是否包含我们预先定义的 finalizer
func containsString(slice []string, s string) bool {
for _, item := range slice {
if item == s {
return true
}
}
return false
}
deployment
// check if Deployment already exists, if not create a new one
deployment := &appsv1.Deployment{}
log.Info("Getting the deployment.", "cid: ", cid)
err = r.Client.Get(context.Background(), types.NamespacedName{Name: cid.Name, Namespace: cid.Namespace}, deployment)
if errors.IsNotFound(err) {
dep := r.deploymentForCustomImageDeploy(cid)
log.Info("Creating a new deployment.", "Namespace: ", dep.Namespace, "Name: ", dep.Name)
err = r.Client.Create(context.Background(), dep)
if err != nil {
log.Error(err, "Failed to create a new deployment", "Namespace: ", dep.Namespace, "Name: ", dep.Name)
return ctrl.Result{}, err
}
}
if err != nil {
log.Error(err, "Failed to create a new deployment")
return ctrl.Result{}, err
}
// ensure the size
size := cid.Spec.Size
if deployment.Spec.Replicas == nil {
// replicas is nil, requeue
log.Info("deployment.Spec.Replicas is nil")
return ctrl.Result{RequeueAfter: time.Second * 5}, nil
}
if *deployment.Spec.Replicas != size {
deployment.Spec.Replicas = &size
err = r.Client.Update(context.Background(), deployment)
if err != nil {
log.Error(err, "Failed to udpate deployment", "Namespace: ", deployment.Namespace, "Name: ", deployment.Name)
return ctrl.Result{}, err
}
// size not match, requeue
return ctrl.Result{RequeueAfter: time.Second * 5}, nil
}
其中 deploymentForCustomImageDeploy 会准备需要创建 deployment 的 Spec
// deploymentForMemcached returns a Deployment object
func (r *CustomImageDeployReconciler) deploymentForCustomImageDeploy(c *customimagedeployv1.CustomImageDeploy) *appsv1.Deployment {
replicas := c.Spec.Size
image := c.Spec.Image
name := c.Name
port := c.Spec.Port
ls := labelsForCustomImageDeploy(name)
dep := &appsv1.Deployment{
ObjectMeta: metav1.ObjectMeta{
Name: c.Name,
Namespace: c.Namespace,
Labels: ls,
},
Spec: appsv1.DeploymentSpec{
Replicas: &replicas,
Selector: &metav1.LabelSelector{
MatchLabels: ls,
},
Template: corev1.PodTemplateSpec{
ObjectMeta: metav1.ObjectMeta{
Labels: ls,
},
Spec: corev1.PodSpec{
Containers: []corev1.Container{{
Image: image,
Name: name,
Ports: []corev1.ContainerPort{{
ContainerPort: port,
// Name: name, // Name is optinal, no more than 15 characters
}},
}},
},
},
},
}
log := r.Log.WithValues("CustomImageDeployReconciler", "deploymentForCustomImageDeploy")
// Set Memcached instance as the owner of the Deployment.
if err := ctrl.SetControllerReference(c, dep, r.Scheme); err != nil {
log.Info("SetControllerReference", "error : ", err)
} //todo check how to get the schema
return dep
}
其中辅助函数 labelsForCustomImageDeploy 用于生成 labels
// labelsForCustomImageDeploy returns the labels for selecting the resources
// belonging to the given custom-image-deploy CR name.
func labelsForCustomImageDeploy(name string) map[string]string {
return map[string]string{"app": name, "managed_by": "custom-image-deploy"}
}
service
// check if Service already exists, if not create a new one
service := &corev1.Service{}
log.Info("Getting the service.", "cid: ", cid)
err = r.Client.Get(context.Background(), types.NamespacedName{Name: cid.Name, Namespace: cid.Namespace}, service)
if errors.IsNotFound(err) {
svc := r.serviceForCustomImageDeploy(cid)
log.Info("Creating a new service.", "Namespace: ", svc.Namespace, "Name: ", svc.Name)
err = r.Client.Create(context.Background(), svc)
if err != nil {
log.Error(err, "Failed to create a new service", "Namespace: ", svc.Namespace, "Name: ", svc.Name)
return ctrl.Result{}, err
}
}
if err != nil {
log.Error(err, "Failed to create a new service")
return ctrl.Result{}, err
}
// make sure service is created(has a clusterip)
if service.Spec.ClusterIP == "" {
return ctrl.Result{RequeueAfter: time.Second * 5}, nil
}
ingress
// check if Ingress already exists, if not create a new one
ing := &networking.Ingress{}
err = r.Client.Get(context.TODO(), types.NamespacedName{Name: cid.Name, Namespace: cid.Namespace}, ing)
if errors.IsNotFound(err) {
log.Info("Creating a new ingress.", "cid: ", cid)
ing := r.ingressForCustomImageDeploy(cid)
log.Info("Creating a new ingress.", "Namespace: ", ing.Namespace, "Name: ", ing.Name)
err = r.Client.Create(context.TODO(), ing)
if err != nil {
log.Error(err, "Failed to create a new ingress", "Namespace: ", ing.Namespace, "Name: ", ing.Name)
return ctrl.Result{}, err
}
}
if err != nil {
log.Error(err, "Failed to create a new ingress", "Namespace: ", ing.Namespace, "Name: ", ing.Name)
return ctrl.Result{}, err
}
if len(ing.Status.LoadBalancer.Ingress) == 0 {
return ctrl.Result{RequeueAfter: time.Second * 5}, nil
}
测试
以 nginx 为例,我们需要创建 nginx deployment、nginx service 和 nginx ingress。以往我们都会准备三个文件:deployment.yaml, service.yaml, ingress.yaml,现在我们只需一个文件就可以了 nginx.yaml。
apiVersion: customimagedeploy.example.com/v1
kind: CustomImageDeploy
metadata:
name: customimagedeploy-nginx
spec:
# Add fields here
size: 1
port: 80
image: "nginx:1.17"
一键部署:
kubectl apply -f nginx.yaml
查看结果:
$ k get pod,svc,deploy,rs,ing -l managed_by=custom-image-deploy
NAME READY STATUS RESTARTS AGE
pod/customimagedeploy-nginx-7f55f7c585-pb9bm 1/1 Running 0 6m20s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/customimagedeploy-nginx ClusterIP 172.20.50.80 <none> 80/TCP 6m20s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/customimagedeploy-nginx 1/1 1 1 6m20s
NAME DESIRED CURRENT READY AGE
replicaset.apps/customimagedeploy-nginx-7f55f7c585 1 1 1 6m20s
NAME HOSTS ADDRESS PORTS AGE
ingress.extensions/customimagedeploy-nginx customimagedeploy-nginx.default a123456789012345623242424424-1314151151515.elb.cn-northwest-1.amazonaws.com.cn 80 84s
由于我们部署了 kong 作为 api gateway,我们可以通过访问 load balancer 地址来测试一下是否能正确访问刚刚部署的 nginx 服务
curl -H "Host: customimagedeploy-nginx.default" \
a123456789012345623242424424-1314151151515.elb.cn-northwest-1.amazonaws.com.cn
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>
If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.
</p>
<p>
For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br />
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.
</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
Flink DataStream Socket Source and Print Sink
Intro
In this tutorial, we will walkthrough how to use flink datastream api to read data from socket and print the result.
Setup
First, let's set up a new flink project. We can use the official flink quickstart script to create a new project.
bash -c "$(curl https://flink.apache.org/q/gradle-quickstart.sh)" -- 1.15.0 _2.12
Walkthrough for flink datastream api, socket as source and print as sink
Let's see how to initialize StreamExecutionEnvironment and setup print sink.
We start by creating a StreamExecutionEnvironment, which is the main entry point for all Flink applications. We then create a DataStream by adding a source function that reads from a socket and a sink function that prints its input to the console.
public class DataStreamJob {
public static void windowWordCount() throws Exception {
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(value -> value.f0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1);
dataStream.print();
env.execute("Window WordCount");
}
public static void main(String[] args) throws Exception {
// Sets up the execution environment, which is the main entry point
// to building Flink applications.
// final StreamExecutionEnvironment env =
// StreamExecutionEnvironment.getExecutionEnvironment();
windowWordCount();
}
}
The windowWordCount method first creates a datastream from a socket, then splits the words from the text into a tuple of (word, 1) and groups by the word. It then creates a window of 5 seconds and sums the counts of each word in the window. The result is then printed to the console.
Run local socket using nc:
nc -lk 9999
Build flink job:
gradle clean installShadowDist
Submit flink job:
FLINK_HOME=~/flink/flink-1.15.1
$FLINK_HOME/bin/flink run -c org.myorg.quickstart.DataStreamJob build/install/quickstart-shadow/lib/quickstart-0.1-SNAPSHOT-all.jar
The output will be like:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.flink.api.java.ClosureCleaner (file:/home/ec2-user/flink/flink-1.15.1/lib/flink-dist-1.15.1.jar) to field java.lang.String.value
WARNING: Please consider reporting this to the maintainers of org.apache.flink.api.java.ClosureCleaner
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Job has been submitted with JobID 674851e1ff9da68eb742f93d6d874ca6
Tests
Let's see how to test the job.
Simple test
We can test it by using nc command.
Type in terminal running nc command:
123 555
hello world
hello world
hi jon
hi non
hello 123
Check log in $FLINK_HOME/log directory, file flink-ec2-user-taskexecutor-1-ip-172-24-145-118.cn-northwest-1.compute.internal.out:
==> flink-ec2-user-taskexecutor-1-ip-172-24-145-118.cn-northwest-1.compute.internal.out <==
(world,1)
(hello,1)
(555,1)
(hello,1)
(world,1)
(hi,2)
(non,1)
(jon,1)
(hello,1)
(123,1)
Random string
nc:
a b c a b c a b c hello non hello k
flink log:
==> flink-ec2-user-taskexecutor-1-ip-172-24-145-118.cn-northwest-1.compute.internal.out <==
(a,3)
(k,1)
(non,1)
(hello,2)
(c,3)
(b,3)
Shakespeare
input
To be, or not to be, that is the question
log
==> flink-ec2-user-taskexecutor-1-ip-172-24-145-118.cn-northwest-1.compute.internal.out <==
(To,1)
(question,1)
(the,1)
(is,1)
(that,1)
(to,1)
(not,1)
(or,1)
(be,,2)
Long string
input
To be, or not to be, that is the question:
Whether 'tis nobler in the mind to suffer
The slings and arrows of outrageous fortune,
Or to take arms against a sea of troubles
And by opposing end them. To die—to sleep,
No more; and by a sleep to say we end
The heart-ache and the thousand natural shocks
That flesh is heir to: 'tis a consummation
Devoutly to be wish'd. To die, to sleep;
To sleep, perchance to dream—ay, there's the rub:
For in that sleep of death what dreams may come,
When we have shuffled off this mortal coil,
Must give us pause—there's the respect
That makes calamity of so long life.
For who would bear the whips and scorns of time,
Th'oppressor's wrong, the proud man's contumely,
The pangs of dispriz'd love, the law's delay,
The insolence of office, and the spurns
That patient merit of th'unworthy takes,
When he himself might his quietus make
With a bare bodkin? Who would fardels bear,
To grunt and sweat under a weary life,
But that the dread of something after death,
The undiscovere'd country, from whose bourn
No traveller returns, puzzles the will,
And makes us rather bear those ills we have
Than fly to others that we know not of?
Thus conscience doth make cowards of us all,
And thus the native hue of resolution
Is sicklied o'er with the pale cast of thought,
And enterprises of great pith and moment
With this regard their currents turn awry
And lose the name of action
log
==> flink-ec2-user-taskexecutor-1-ip-172-24-145-118.cn-northwest-1.compute.internal.out <==
(,2)
(action,1)
(name,1)
(lose,1)
(awry,1)
(turn,1)
(currents,1)
(their,1)
(regard,1)
(moment,1)
(pith,1)
(great,1)
(enterprises,1)
(thought,,1)
(cast,1)
(pale,1)
(with,1)
(o'er,1)
(sicklied,1)
(Is,1)
(resolution,1)
(hue,1)
(native,1)
(thus,1)
(all,,1)
(cowards,1)
(doth,1)
(conscience,1)
(Thus,1)
(of?,1)
(know,1)
(others,1)
(fly,1)
(Than,1)
(ills,1)
(those,1)
(rather,1)
(will,,1)
(puzzles,1)
(returns,,1)
(traveller,1)
(bourn,1)
(whose,1)
(from,1)
(country,,1)
(undiscovere'd,1)
(death,,1)
(after,1)
(something,1)
(dread,1)
(But,1)
(life,,1)
(weary,1)
(under,1)
(sweat,1)
(grunt,1)
(bear,,1)
(fardels,1)
(Who,1)
(bodkin?,1)
(bare,1)
(With,2)
(make,2)
(quietus,1)
(his,1)
(might,1)
(himself,1)
(he,1)
(takes,,1)
(th'unworthy,1)
(merit,1)
(patient,1)
(spurns,1)
(office,,1)
(insolence,1)
(delay,,1)
(law's,1)
(love,,1)
(dispriz'd,1)
(pangs,1)
(contumely,,1)
(man's,1)
(proud,1)
(wrong,,1)
(Th'oppressor's,1)
(time,,1)
(scorns,1)
(whips,1)
(bear,2)
(would,2)
(who,1)
(life.,1)
(long,1)
(so,1)
(calamity,1)
(makes,2)
(respect,1)
(pause—there's,1)
(us,3)
(give,1)
(Must,1)
(coil,,1)
(mortal,1)
(this,2)
(off,1)
(shuffled,1)
(have,2)
(When,2)
(come,,1)
(may,1)
(dreams,1)
(what,1)
(death,1)
(For,2)
(rub:,1)
(there's,1)
(dream—ay,,1)
(perchance,1)
(sleep;,1)
(die,,1)
(wish'd.,1)
(be,1)
(Devoutly,1)
(consummation,1)
(to:,1)
(heir,1)
(flesh,1)
(That,3)
(shocks,1)
(natural,1)
(thousand,1)
(heart-ache,1)
(we,4)
(say,1)
(sleep,2)
(more;,1)
(No,2)
(sleep,,2)
(die—to,1)
(them.,1)
(end,2)
(opposing,1)
(by,2)
(And,5)
(troubles,1)
(sea,1)
(a,5)
(against,1)
(arms,1)
(take,1)
(Or,1)
(fortune,,1)
(outrageous,1)
(of,14)
(arrows,1)
(and,7)
(slings,1)
(The,5)
(suffer,1)
(mind,1)
(in,2)
(nobler,1)
('tis,2)
(Whether,1)
(question:,1)
(the,14)
(is,2)
(that,4)
(to,8)
(not,2)
(or,1)
(be,,2)
(To,5)
Hands on Linkerd
- 1、安装
- 2、安装 linkerd
- 3、下载镜像
- 4、开启 dashboard
- 5、安装示例工程 emojivoto
- 6、注入 linkerd 到 emojivoto
- 7、通过 grafana 查看监控
- 8、调试
- Refs
1、安装
首先搭建 kubernetes 环境,我用的是 Docker Desktop for Mac:
2、安装 linkerd
curl 安装,并将 linkerd 加到 PATH 路径:
curl -sL https://run.linkerd.io/install | sh
export PATH=$PATH:$HOME/.linkerd2/bin
检查下版本(这里是 statble-2.3.2):
$ linkerd version
Client version: stable-2.3.2
Server version: stable-2.3.2
3、下载镜像
众所周知的原因 gci.io 无法访问,需要另辟蹊径替换镜像地址:
linkerd install | \
sed -e 's/gcr.io\/linkerd-io\//dylankyc\/gcr.io_linkerd-io_/g' \
kubectl apply -f -
这里是输出:
namespace/linkerd created
configmap/linkerd-config created
serviceaccount/linkerd-identity created
clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-identity unchanged
clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-identity unchanged
service/linkerd-identity created
secret/linkerd-identity-issuer created
deployment.extensions/linkerd-identity created
serviceaccount/linkerd-controller created
clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-controller unchanged
clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-controller unchanged
service/linkerd-controller-api created
service/linkerd-destination created
deployment.extensions/linkerd-controller created
customresourcedefinition.apiextensions.k8s.io/serviceprofiles.linkerd.io unchanged
serviceaccount/linkerd-web created
service/linkerd-web created
deployment.extensions/linkerd-web created
serviceaccount/linkerd-prometheus created
clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-prometheus unchanged
clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-prometheus unchanged
service/linkerd-prometheus created
deployment.extensions/linkerd-prometheus created
configmap/linkerd-prometheus-config created
serviceaccount/linkerd-grafana created
service/linkerd-grafana created
deployment.extensions/linkerd-grafana created
configmap/linkerd-grafana-config created
serviceaccount/linkerd-sp-validator created
clusterrole.rbac.authorization.k8s.io/linkerd-linkerd-sp-validator unchanged
clusterrolebinding.rbac.authorization.k8s.io/linkerd-linkerd-sp-validator configured
service/linkerd-sp-validator created
deployment.extensions/linkerd-sp-validator created
或者你也先将 linkerd install 输出的 yaml 保存起来:
linkerd install > linkerd.yaml
# replace gcr.io image with docker hub; for linux, replace `sed -i ""` with `sed -i`
sed -i "" -e 's/gcr.io\/linkerd-io\//dylankyc\/gcr.io_linkerd-io_/g' linkerd.yaml
再通过 kubectl 安装:
kubectl apply -f linkerd.yaml
喝杯咖啡之后 linkerd 就安装完成了,如果不行就两杯。
4、开启 dashboard
linkerd dashboard &
默认会随机分配一个端口如 50750,打开 http://127.0.0.1:50750/overview,通过 dashboard 可以探索 linkerd mesh 内部组件。
5、安装示例工程 emojivoto
curl -sL https://run.linkerd.io/emojivoto.yml | kubectl apply -f -
将容器 80 端口转发到本地 8080,这样通过 localhost:8080 就能访问 emojivoto 服务了。
kubectl -n emojivoto port-forward svc/web-svc 8080:80 &
由于通过 kubectl 安装,此时没有注入 linkerd sidecar,所以 Meshed 显示 0/1。
6、注入 linkerd 到 emojivoto
kubectl get -n emojivoto deploy -o yaml \
| linkerd inject - \
| kubectl apply -f -
注入 linkerd 的 deployment 在 dashboard 上可以查看到显示为 Meshed。
注入 linkderd 需要操纵的是 deployment,如:
linkerd inject deployment.yml \
| kubectl apply -f -
它会把 linkerd 作为 sidecar inject 到 pod 里,并配置 iptables。
$ kubectl get -n emojivoto deploy -o yaml | linkerd inject - | kubectl apply -f -
deployment "emoji" injected
deployment "vote-bot" injected
deployment "voting" injected
deployment "web" injected
deployment.extensions/emoji configured
deployment.extensions/vote-bot configured
deployment.extensions/voting configured
deployment.extensions/web configured
7、通过 grafana 查看监控
访问 emojivoto 几次,可以在 grafana 面板 http://127.0.0.1:50750/grafana 查看到服务的历史数据,如 Success rate, Request rate, Latency distribution percentiles 等。
8、调试
为了演示,demo 故意在代码里埋了一些错误。
点开 deployment/web,可以看到 deploy/web 接收 deploy/vote-bot 请求,同时也会给 deploy/emoji 和 deploy/voting 发送请求。
TODO:
但是值得注意的是,deploy/vote-bot 和 deploy/voting 的成功率都不是 100%,由于 deploy/vote-bot 调用 deploy/web 进而调用 deploy/voting,
还可以看出,对 web 而言,deploy/vote-bot (对应 PATH /api/vote)是入口,而 deploy/voting (对应 PATH /emojivoto.v1.VotingService/VoteDoughnut)是出口,我们可以猜想错误因 deploy/voting 而起。
我们还可以点击 tap,通过查看只针对这一接口 /emojivoto.v1.VotingService/VoteDoughnut 的请求来进一步定位错误。
通过图中 Unknown 的消息及 grpc 针对 Unknown code 的说明文档(https://godoc.org/google.golang.org/grpc/codes#Code),可知这个接口有异常。
我们还可以通过查看代码来验证:https://github.com/BuoyantIO/emojivoto/blob/master/emojivoto-voting-svc/api/api.go#L22,我们可以看到 doughnut(甜甜圈)那里报错了,从而定位坑。
Refs
https://linkerd.io/2/tasks/debugging-your-service/
Multiple GRPC Service Routing in Kong
Into
这里演示了利用 kong 对多个 grpc 服务进行路由的方法。
1.在 kubernetes 安装 kong
kubecstl apply -f https://bit.ly/kong-ingress-dbless
2.安装完查看 kong 服务情况
$ kubectl -n kong get all
NAME READY STATUS RESTARTS AGE
pod/ingress-kong-1122334455-mzfnx 2/2 Running 0 23h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kong-proxy LoadBalancer 172.20.179.34 a111222333444555666777888999000f-1122334455667788.elb.cn-northwest-1.amazonaws.com.cn 80:30004/TCP,443:32418/TCP 23h
service/kong-validation-webhook ClusterIP 172.20.59.181 <none> 443/TCP 23h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ingress-kong 1/1 1 1 23h
NAME DESIRED CURRENT READY AGE
replicaset.apps/ingress-kong-1122334455 1 1 1 23h
将 AWS ELB 保存在变量 ELB 中
ELB=$(kubectl -n kong get svc -o=jsonpath="{.items[0].status.loadBalancer.ingress[0].hostname}")
echo $ELB
# a111222333444555666777888999000f-1122334455667788.elb.cn-northwest-1.amazonaws.com.cn
3.安装 grpcbin 服务
kubectl apply -f https://bit.ly/grpcbin-service
给 service 打 patch,让 kong 使用 gRPC 协议来和 upstream 通信,grpcbin 9001 服务需要指定 protocol 为 grpcs
kubectl patch svc grpcbin -p '{"metadata":{"annotations":{"konghq.com/protocol":"grpcs"}}}'
安装 ingress
kubectl apply -f ingress.yaml
ingress.yaml
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: grpcbin-grpc
annotations:
konghq.com/protocols: grpc,grpcs
spec:
rules:
- http:
paths:
- path: /hello.HelloService
backend:
serviceName: grpcbin
servicePort: 9001
下面进行测试。
测试前需要准备 protobuf 文件
hello.proto
// based on https://grpc.io/docs/guides/concepts.html
syntax = "proto2";
package hello;
service HelloService {
rpc SayHello(HelloRequest) returns (HelloResponse);
rpc LotsOfReplies(HelloRequest) returns (stream HelloResponse);
rpc LotsOfGreetings(stream HelloRequest) returns (HelloResponse);
rpc BidiHello(stream HelloRequest) returns (stream HelloResponse);
}
message HelloRequest {
optional string greeting = 1;
}
message HelloResponse {
required string reply = 1;
}
通过 grpcurl 来测试
$ grpcurl -v -d '{"greeting": "Kong Hello world!"}' -proto hello.proto -insecure $ELB:443 hello.HelloService.SayHello
Resolved method descriptor:
rpc SayHello ( .hello.HelloRequest ) returns ( .hello.HelloResponse );
Request metadata to send:
(empty)
Response headers received:
content-type: application/grpc
date: Wed, 13 May 2020 02:29:43 GMT
server: openresty
trailer: Grpc-Status
trailer: Grpc-Message
trailer: Grpc-Status-Details-Bin
via: kong/2.0.4
x-kong-proxy-latency: 1
x-kong-upstream-latency: 13
Response contents:
{
"reply": "hello Kong Hello world!"
}
Response trailers received:
(empty)
Sent 1 request and received 1 response
4.安装 helloworld-grpc 服务
kubectl apply -f helloworld-grpc.yaml
helloworld-grpc.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: helloworld
spec:
selector:
matchLabels:
app: helloworld
replicas: 1
template:
metadata:
labels:
app: helloworld
spec:
containers:
- name: helloworld
image: "quay.io/dylankyc/grpc-examples-helloworld-server"
resources:
limits:
cpu: 64m
memory: 128Mi
requests:
cpu: 10m
memory: 64Mi
---
apiVersion: v1
kind: Service
metadata:
name: helloworld
labels:
app: helloworld
annotations:
konghq.com/protocol: grpc
spec:
# type: ClusterIP
selector:
app: helloworld
ports:
- port: 50051
targetPort: 50051
name: grpc
# protocol: TCP
给 service 打 patch,让 kong 使用 gRPC 协议来和 upstream 通信,因为 helloworld 采用非 TLS 方式,这里指定 protocol 为 grpc
kubectl patch svc helloworld -p '{"metadata":{"annotations":{"konghq.com/protocol":"grpc"}}}'
安装 ingresss
kubectl apply -f ingress.yaml
ingress.yaml
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: helloworld-grpc
annotations:
konghq.com/protocols: grpc,grpcs
spec:
rules:
- http:
paths:
- path: /helloworld.Greeter
backend:
serviceName: helloworld
servicePort: 50051
下面进行测试。
测试前需要准备 protobuf 文件
helloworld.proto
// protoc -I helloworld/ helloworld/helloworld.proto --go_out=plugins=grpc:helloworld
syntax = "proto3";
// option go_package = "github.com/dylankyc/grpc-examples/helloworld/internal/pb/helloworld";
// option go_package = "../pb/helloworld;helloworld";
// OK
option go_package = "pb/helloworld;helloworld";
// NOT OK
// option go_package = "helloworld";
package helloworld;
// The greeter service definition.
service Greeter {
// Sends a greeting
rpc SayHello (HelloRequest) returns (HelloReply) {}
}
// The request message containing the user's name.
message HelloRequest {
string name = 1;
}
// The response message containing the greetings
message HelloReply {
string message = 1;
}
通过 grpcurl 来测试
$ grpcurl -v -d '{"name": "Kong Hello world!"}' -insecure -proto helloworld.proto $ELB:443 helloworld.Greeter.SayHello
Resolved method descriptor:
// Sends a greeting
rpc SayHello ( .helloworld.HelloRequest ) returns ( .helloworld.HelloReply );
Request metadata to send:
(empty)
Response headers received:
content-type: application/grpc
date: Wed, 13 May 2020 02:55:01 GMT
server: openresty
via: kong/2.0.4
x-kong-proxy-latency: 0
x-kong-upstream-latency: 2
Response contents:
{
"message": "Hello Kong Hello world!"
}
Response trailers received:
(empty)
Sent 1 request and received 1 response